
出品丨虎嗅医疗组
作者丨石三香
题图丨视觉中国
你相信 AI 能帮我们更快地发现更多新药,甚至找到人都找不到的药吗?
不管你信不信,资本正在相信。国内 AI 的新风口—— AI+药物研发,正以肉眼可见的速度崛起。
动脉网数据显示,2020 年,AI 制药领域融资项目数量翻了一番,且当年融资总额同比增长 10 倍。其中,单一个晶泰科技在去年 9 月便拿到了 3 亿多美元的融资,历轮投资方也颇为亮眼,譬如谷歌、软银、晨兴、中金、红杉等。
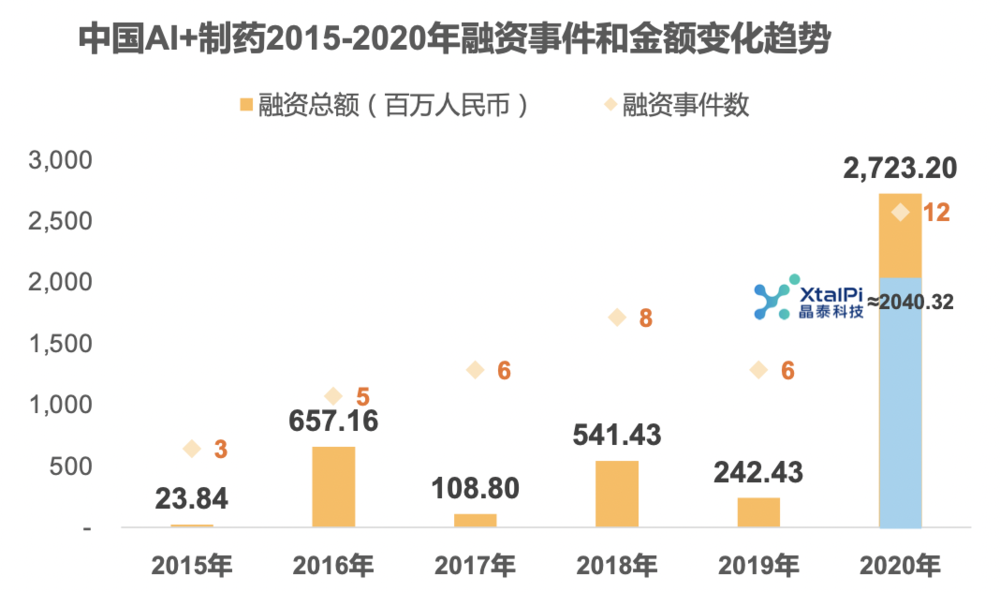
要知道,其中多家明星基金可不是第一次对这个赛道下手了。
除了这些初创公司拿钱、砸钱,更大型的玩家也频频亲自下场。国内科技巨头,除了投资相关公司以外,也做好了自己下场的准备。要么已经开始了正式的进军姿态,譬如百度成立百图生科、腾讯推出云深智药;要么在储备相关人才,譬如华为官网挂出的招聘药物研发算法工程师的操作。
医药领域的上市公司,国内如药明康德、豪森药业、先声药业等,也紧紧跟随着跨国巨头诺华、阿斯利康等的步伐,对 AI 制药的投入逐年增加。
更微观又直观的感受是,“我们交叉学院的学生以前毕业时工作没有那么好找,但现在还没毕业就都被预订了”,裴剑锋(北大前沿交叉学科研究院研究员、英飞智药创始人)告诉虎嗅。
一个新的元年似乎就此开始了。
这样的热烈,在上个月苏州举办的国内第一届生物计算大会上让人有更直观地感受。
从议程和嘉宾看过去,可以说这是一场学界与企业的大联欢。先进的算力、算法与包括各种组学在内的前沿生物技术,在这个会场里似乎已经实现了某一种融合,并开始要革生物医药研发方式的命,随后还要再颠覆诊断和治疗的思路。
作为百图生科的董事长,李彦宏表达了对生物计算宏图的满满信心:“生物计算领域有三个关键指标在快速增长,分别是基因组学研究带来的数据快速增长、新药研发过程中所积累的知识在快速增长甚至是爆发,以及新生的各类机器学习的算法在快速迭代。”
“我们希望打造一批融合生物+计算技术的药企,利用大量的生物数据,能够把所有的常识积累到统一的知识图谱上去,从而把药物发现的大海捞针变成按图索骥,这样就可以加快发展 first-in-class 的创新药物为人类的生命健康带来福祉。”
而在由此而生的庞杂且无序的数据海洋中,作为桥梁的 AI 理所当然地被寄予了厚望。
尤其是深度学习,“从数据分析的角度和科学模型的角度,能给我们带来新的机会”,中国科学院院士鄂维南院士也同样看好。
在这两天的狂热氛围中,我有幸听到了不少学者与企业家的分享,亦无比激动于他们在做的一项项通过计算更精准度量生命的研究和探索。
但素以传统保守长周期闻名的制药行业与完全凭数据驱动、跑得飞快的人工智能行业,到底能碰撞出的是火花,还是泡沫?
靠人猜,不如靠 AI
我们需要承认的是,AI 的确已在制药领域展露了一些头角。
譬如疫情期间被美国 FDA 授予治疗新冠肺炎重症患者紧急使用权的巴瑞替尼,这款老抗风湿药的新疗效便是由 AI 预判的。
更进一步的是,今年年初,颇受大药企欢迎的AI+药物研发公司 Insilico 宣布,自己在纯 AI 驱动下,找到了一个全新的特发性纤维化疾病新靶点,以及能打开这把锁的钥匙——一个新的针对该靶点的化合物。
仅用 18 个月、180 万美元,完全靠 AI,新靶点、新药物,每一个关键词似乎都在刺激着医药研发从业者的兴奋点。
毕竟,眼下全球新药研发都面临着效率不断下降的窘境。
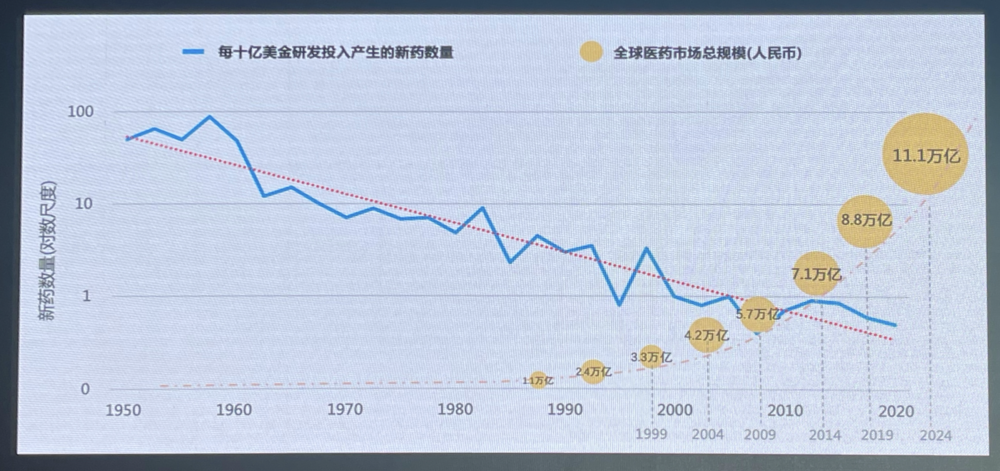
此前,Nature 上的一篇论文就已经指出,自 1950 年以来,每 10 亿美元能换来的新药批准数量大约每 9 年会减少一半,按通货膨胀调整后,这 10 亿美元的价值下降了约 80 倍。
拆开来看,一方面,一款新药研发的成本正在不断上探。
过往,我们就常听到新药研发“10 年 10 亿美元”的传说。虽然这样的时间和金钱成本已然十分不菲,但眼下的实际开销仍一路水涨船高。
塔夫茨药物研发中心对三十年来的新药研发统计后发现,目前开发一个上市新药的直接现金支出为 13.95 亿美元,间接时间成本为 11.63 亿美元,还有被批准后的后续研发费用 3.12 亿美元,这样开发一个新药总价高达 28.70 亿美元。
当然,国内目前有很多 fast-follow 及 me-better 的新药项目,相对而言能节约不少。可但凡要做国际多中心临床试验,又或者试图靠自己找新的靶点,所耗费的时间和金钱也并不会少到哪去。
另一方面,不断上涨的成本却并没有换来更高的成功率。如下图所示,每 10 亿美元能产生的新药数量从上世纪 60 年代开始便几乎在不断走低。
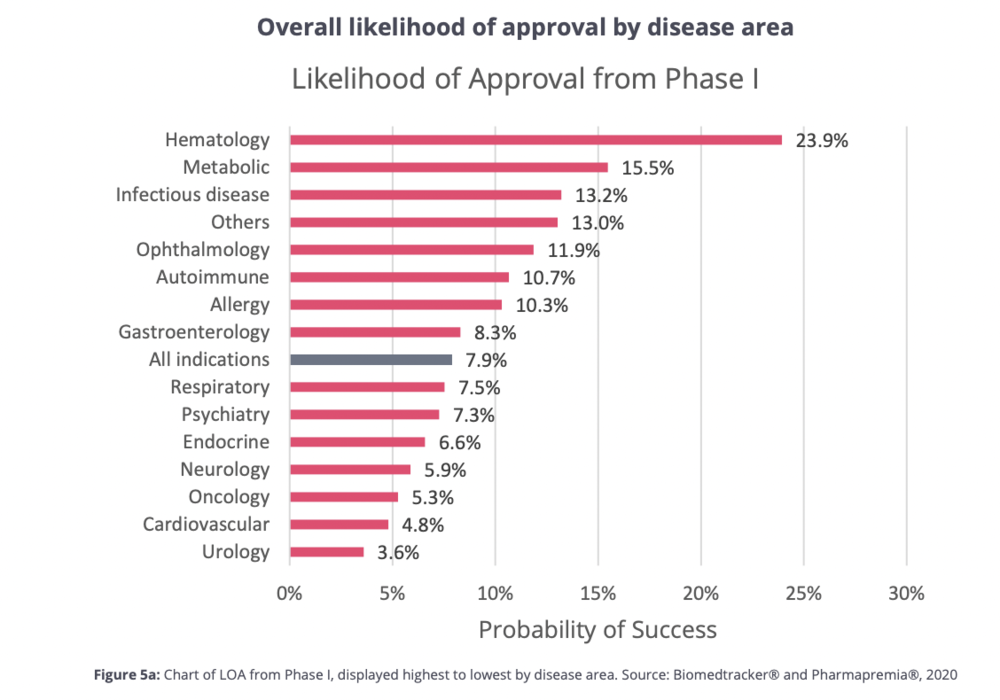
在对 2011 年~2020 年十年间 1779 家药企的 9704 个药物临床项目进行研究后,生物技术行业组织 BIO 发现,这些药物从进入临床 I 期到获得美国 FDA 批准上市的成功率平均只有 7.9%,其中肿瘤药物的成功率只有 5.3%,而一款药物的成功平均耗时 10.5 年。
也正因如此,药企的回报率也在不断下降。据德勤统计,16 家全球巨头药企的研发回报率已从 2010 年的 10.1%,下降到了 2016 年的 3.7%。
就算中国的创新药走到这一步还有点距离,但这换谁能不焦虑呢?
不仅如此,在同一靶点、差不多适应症上的内卷,还会让已经成功上市产品的药企面对极大的商业化压力。巨头尚且如此,譬如同属 PD-1 的 BMS 的 O 药和默沙东的 K 药,都在市场里挤破头,小公司又该如何自处?
当然,新药研发进入瓶颈的原因很复杂,我们今天就只谈谈药企遇到的困难。
从流程上来看,如今一款新药的诞生要经历药物发现(此处我们将靶点验证合并到这一阶段)、临床前研究、临床试验、监管审批与上市后监测四大阶段。
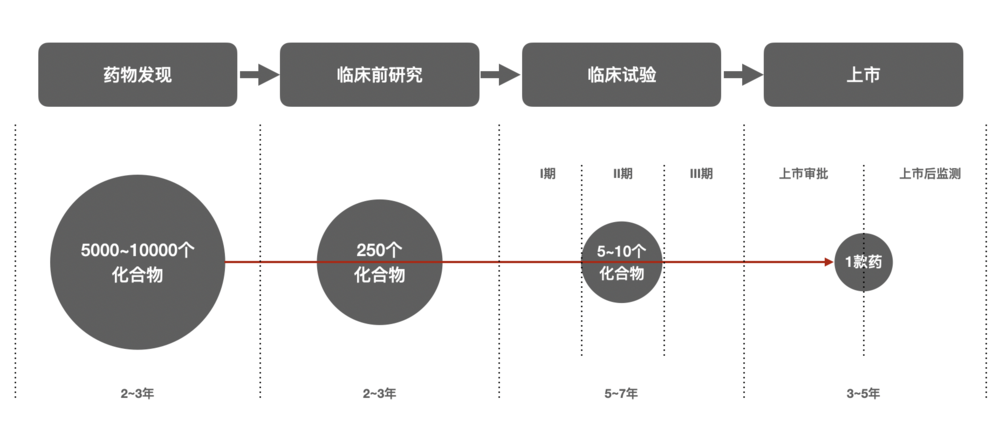
其中,药物发现是最基础也最重要的一步,从研究和靶点验证、靶点药理学和生物标志开发,再到先导化合物发现、先导化合物优化,从而找到可以解决某一疾病的有效化合物。
但正如鄂维南介绍,眼下生物设计是非常经验化的学科。
简单来讲,从事药物研发的科学家们凭着前辈学者们的研究,再加上自己多年积累下的经验,来推测哪些靶点和化合物可能可行,再通过一次次的实验——从分子到细胞、动物,再到人体身上——来验证其吸收、代谢、有效性及毒性。
用恒瑞医药高级副总经理兼全球研发总裁张连山的话来说便是,“过去我们都是从猜做药”。
“后来有了计算机辅助,能做的靶点做了非常多,但到今天,太复杂了,一个新的靶点都找不到”,做药物研发近三十年的他也不由感慨。
的确,随着我们用更多更精细地方式挖掘人体,所得到的数据量,包括基因组学、蛋白质组学、单细胞组学,无论从复杂程度还是数量来说都愈发“失控”。“诊疗必须基于海量数据和多参数的表征,这样一个时代已经来临”,中国科学院院士谭蔚泓断言。
而维数灾难之下,如何从中找到规律,是矗立在科学家面前又一个颇具难度的挑战。
尤其在过往的工具渐渐失效的当下,大家的一个设想是,用人类的智慧训练AI来猜,或许能成为提效降本的不错方式。
能猜什么?
那么问题来了,在药物研发的四大阶段中,AI 有哪些发挥空间?
对此,和玉资本合伙管理人曾玉给财新的答案是,在化合物筛选、全新靶点发现、临床试验中病人的筛选,以及临床试验设计和数据采集分析等领域,AI 均有用武之地。
目前来看,我国 AI 制药公司的业务大多集中在药物发现领域,主要功能就是帮助研究者们筛选/设计、优化化合物,譬如晶泰科技、深度智耀、星亢原等。
究其原因,一方面是由于这是新药研发的需求所在。“新药的核心痛点本就是要有新结构,没有新结构后面都是空中楼阁”,裴剑锋告诉虎嗅。
另一方面,过去几十年全球制药企业发现的化合物数据量已较为可观,一定程度上,能喂养出更聪明的 AI 。
如前文所述,传统的药物发现是从猜到一次次实验的验证。理论上来讲,药企确定靶点后,AI 的预测能力可以帮助他们直接找到那些可能有效的药物分子。而这样的预测过程又完全在虚拟中进行,从而避免一些本不必要的实验。
譬如,根据前文所述塔夫茨总结的数据,药企们要从 5000~10000 个活性化合物(Hit Compound)中,筛选出约 250 个先导化合物,简单来讲,每一个被踢出队列的化合物背后,都意味着一轮重复的实验。
而如果人类能够把所有已知的对该靶点有效及无效的化合物都让 AI 知道,AI 便可从中分析这些化合物成功或失败的规律,从而判断一个分子能否脱颖而出,包括那些可能被人类经验忽略的化合物。AI 甚至还能够对这些分子结构的选择性、ADMET(药物的吸收、分配、代谢、排泄和毒性)等性质做出预测。
人力研发的经年累月,到 AI 这儿可能最终只需要几个月。如果顺利,别说从几千个化合物中找到一个,做到“万里挑一”也不是不可能。
如今,国外投入 AI 制药的公司们,无论巨头还是初创,在这一阶段中已取得了一些实质性的进展。
譬如 BMS 曾经宣布,其部署的 AI 经过训练后,对药物与靶点间的作用关系预测准确度提高到了 95%,较传统方法失败率降低六倍。这项测验关乎药物的毒副作用,AI 的确能帮助企业筛选淘汰那些潜在有毒药物,转而把注意力投向那些可能通过人体试验的药物,让注定失败的趁早失败。
更有一批 AI 制药初创公司陆续公开宣布,他们已经进入临床的几款药物完全依靠 AI 发现与设计。
如 AI 制药创业公司 Exscientia,去年便拿下了第一款由 AI 发现并进入临床的新药,该药的目标适应症为强迫症。据该公司介绍,在此之前,他们只用 12 个月就完成了从筛选到完成临床前研究的过程。今年4月,该公司由 AI 设计的肿瘤免疫分子将进入人体临床试验。
英国的 BenevolentAI 也在去年 2 月将一款由 AI 发现设计的药物推进临床,测试其对治疗特应性皮炎(也就是湿疹)的治疗效果。
遗憾的是,国内的 AI 药神还没有实现走进临床这一步的突破。但这也不意味着,国内的企业没有其他的路子。
眼下最受资本关注的创业公司晶泰科技,及其孵化的剂泰医药,就在药物发现之外,走出了另一条不那么主流的路——稍稍将关口后移到临床前研究阶段,探索以 AI 服务于晶型和剂型的研究的方式。
要知道,即便是一个非常优秀的化合物,其最终能否成药、药物是否稳定、药效如何、患者吸收情况等,全部依赖于其化合物分子的排列方式,也就是晶型。简单来说,若晶型过于稳定,如同钻石一样,则患者难以吸收,甚至根本不能吸收;若晶型不稳定,就好比石墨,放着放着自己就可能变质了。
同时,对于一款新药来说,晶型专利也是其专利的一部分,也能对其价值加一道保障。
而过往这一步,同样需要人工一点点实验试错,X 线衍射、磁共振、热分析……不管药企用哪种方法,烧的都是大量的时间和金钱。
根据晶泰科技的官方介绍,该公司对药物晶型的预测,是通过量子化学计算与 AI 结合的方式来计算分子之间的作用力来判断不同晶型间的理化性质。有业内人士告诉虎嗅,这样一来,晶泰可以在没有很多数据积累的基础上完成对算法的训练。
晶型过后,剂型又是一道关卡。尤其对于靶向药来说,若要更好地将药物递送到靶点,制剂也起到至关重要的作用。
据剂泰医药创始人兼 CEO 赖才达介绍,眼下有40% 在研药物由于药物递送难点而放弃开发,国内的复杂制剂又严重依赖进口,制剂的差异化或许将成为未来创新药的新突破口。
不过,就算一款新的化合物成药表现再出色,也只是一个单兵罢了;如果能找到全新的靶点,就可能带来一个崭新的药物军团。
显然,靶点发现是最值钱的,不然国内科技巨头怎么都对之虎视眈眈,腾讯的云深智药要做,百度的百图生科也要做。
然而,靶点发现的难度也是显而易见的。过去几十年间,被科学家们发现的靶点不少,但验证有效的数量并不多,不然也不会出现 PD-1 的严重内卷。
眼下,有且只有一个公司宣称自己已经做到了,就是前文提到的 Insilico。值得注意的是,Insilico 发现的全新特发性纤维化疾病新靶点及相应的药物,也不过刚刚走到临床前研究这一步,到底能否成功,还需不少时间观望。
总而言之,我们可以看到,在新药研发的前期阶段,AI 的确是起到了一些作用。可毕竟尚无一款真正走过人体试验到审批上市的 AI 新药出现,所有的好与坏,都没有办法得到确定性的结论。
冰火两重天
这也就意味着,没人能知道 AI 到底能否给药企带来提效降本的真正收益。
同时,“目前来说,这些进入临床的,或者在报临床批件的(AI 制药公司),只说我是全用 AI 做的,但并没有披露技术细节”,裴剑锋对当前一些进展的质疑,也代表了不少人的看法。
也正因如此,即便自 2020 年以来,我们经常听到某某药企与某某 AI 制药平台达成了合作,但除了当初拜耳看中 Exscientia,大手一挥就与后者签订了为期 3 年、总价值近3亿美元的合约外,我们鲜少听到作为服务方的初创企业到底能拿到多少钱。
在八点健闻的报道中,一笔 200 万元的订单在业内已是高价,绝大多数AI制药企业一年接到的订单也屈指可数。
药企的观望态度并不难理解。毕竟,AI 技术虽已迭代良久,但仍然“涉世未深”。
一方面,AI 成长所需的数据量十分庞大,而它在医药研发领域显然很难得到足够的养料。对药企来说,化合物结构、晶型等研发数据是他们的立身之本,如非发表论文、提交专利所必须的部分,要他们公开几乎是不可能的,即便他们与一些 AI 制药公司处于合作之中。
国内在数据方面相对的确更为开放,但值得注意的是,我国的新药研发真正起步也不过不到 10 年,数据的量级无法与欧美国家同日而语。
也就是说,AI 制药公司能用到的基本都是公开数据,来源包括文献、药品专利库等。
但公开数据由于来源不同,质量无法保证,挖掘和标注的难度就不小。譬如我们想预测“毒性”,但针对不同适应症的不同药物,毒性本身就没有固定标准,我们又该如何让 AI 把握我们都不好总结的东西呢?
同时,公开数据在维度上也难免有所缺失。
以裴剑锋向虎嗅介绍的“负数据(Negative Data,即测试结果不理想的化合物等数据)”为例,“药物研发里面特别有用的数据就是负数据,负数据再少,也非常有用。就跟做题目一样,只有知道你错哪儿了,之后正确的几率就能更大一些”。
“而这些负数据我们很难从文献中找到,因为药企不会发表,甚至有些企业做完就扔掉了。”
另外,上述说的还是存货最多的小分子化合物数据,靶点、基因组学、蛋白质组学等的数据,更是少之又少、哪里都缺。
这就等于,把 AI 放在人类经验的子集之中,却希望 AI 能猜到跳出人类经验范围的东西,简直像天方夜谭。
另一方面,研究 AI 和新药的人如何融合,对 AI 制药公司来说也是个不小的挑战。“双方不打起来就是非常成功的第一步”,一位业内人士告诉虎嗅,两种截然不同的思维间的碰撞激烈程度可见一斑。
国内的计算和制药交叉人才又极少,用裴剑锋的话来说就是“工业界突然火爆,但学术界还没准备好”。
再加上眼下 AI 制药公司一边大把烧钱、一边难以赚钱的现状,直让人觉得,横亘在理想与现实之间的不啻于天堑。
但裴剑锋建议大家不要太乐观的同时,也不必太过悲观。“这毕竟不像 AI+医疗影像,或者自动驾驶,对准确性的要求特别高。新药研发的成功率本来已经很低了,如果 AI 能把 1%,提到2%、3%,就已经是发挥作用了。长线来看,如果经过 10 年的验证,药真的能做出来了,的确这 10 年内研发的周期和成本并没有被压缩,可就像一条汽车流水线一样,我生产第一辆汽车可能要用 10 小时,但流水线跑通后,剩下的汽车不可能再等 10 个小时出一辆。”
换言之,我们何必期待和大肆宣扬 AI 给医药行业带来完全的颠覆呢?将其当做一个辅助工具,能实际解决哪怕一个小细节的问题,现阶段来讲就已经足够了。