
ChatGPT以及硅谷AI大战终于升级,长出了“眼睛”和“嘴”。5月中旬,OpenAI和谷歌前后发布重磅AI多模态更新,从基于文字交互的ChatGPT全面升级,实现了“声音,文字和视觉”三者全面结合的人工智能新交互功能,而这,也标志着硅谷科技巨头的生成式AI之战正式进入到第二轮。新一轮竞争,只会更加激烈、更加全面。
大家好,欢迎来到硅谷101,这次我们聊聊这次多模态AI之战对科技巨头们的商业版图意味着什么变化,以及生成式AI智能技术的下一步会发生什么。那我们首先来快速复盘一下OpenAI和谷歌发布的多模态重磅更新。
OpenAI GPT-4o:低延迟语音交互,《Her》成为现实
OpenAI这次的发布时长很短,全程就26分钟,发了一款产品GPT-4o。
GPT-4o的“o”是拉丁词根“Omni”,意思是“所有的”“全部的”或“全能”,意味着文本、音频和图像的任意组合作为输入,并生成文本、音频和图像输出的能力,这样的“全面”多模态能力。

说实话,2024年AI之战会升级到多模态产品,这个预期在2023年已经是行业共识,我们在之前多期视频都提到过,仅仅是文字的prompt很难表达人类的意图,非常低效也非常受限,所以有语音和视觉加持的多模态AI交互是人类通往AGI道路上的必经之路。但当多模态AI交互真的到来的时候,我觉得还是会被震撼到。
OpenAI说,GPT-4o可以在232毫秒内响应音频输入,平均为320毫秒,这已经达到人与人之间的响应时间。也就是说,AI语音对话的交互已经能做到非常低延迟、很丝滑,像真人一样对话了。
GPT-4o发布之前,ChatGPT的语音模式功能有着好几秒的延迟,这让整个交互体验非常差,这是因为之前的GPT系列的语音功能是好几个模型的拼合,先把声音转录成文本,再用GPT大模型接受后,输出文本,然后再用text to speech模型生成音频,但这其中会损失非常多的信息,比如说语调,语气中的情绪情感,多个说话人的识别,背景的声音等等,所以语音功能会很慢很迟缓也很基础。
而这次,GPT-4o是OpenAI专门训练的跨文本、语音和视觉的端到端新模型,所有输入和输出都由同一个神经网络处理,这使得GPT-4o能够接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合输出,是兼具了“听觉”、“视觉”的多模态模型,同时还支持中途打断和对话插入,且具备上下文记忆能力。
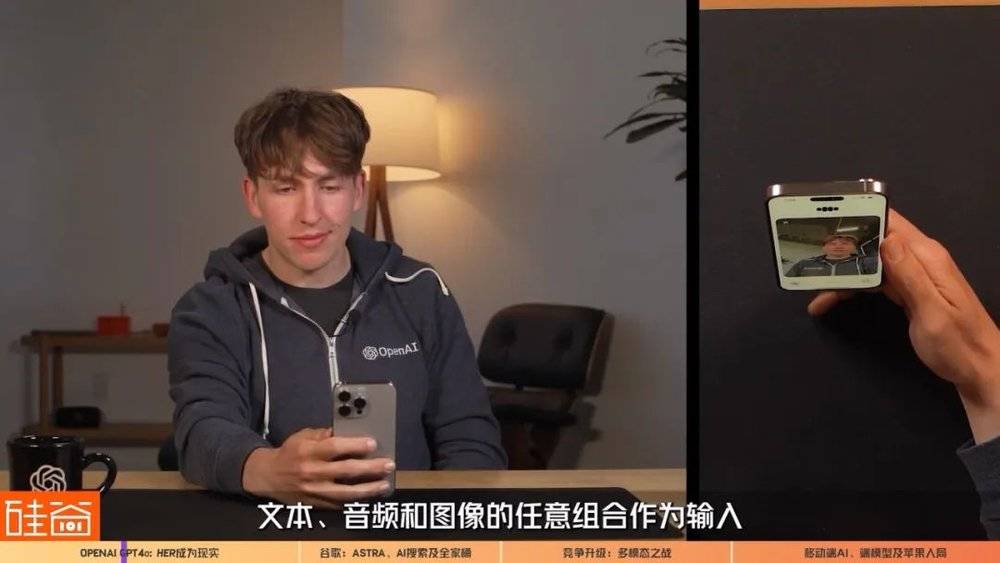
这样的多模态模型是OpenAI首次发布,表示还有很多探索的空间,但目前展现出的功能已经让人惊喜。比如说,在现场demo中,GPT-4o可以理解人们的呼吸急促声音并用轻松的方式安慰人类。

它可以识别人脸表情,以及辨认情绪。

它可以随意变换语气和风格来讲故事。

同时,GPT-4o还可以通过硬件设备的视觉来分析人们正在从事的工作、看的书,可以引导人们解题,可以切换语言实时翻译,也能通过视觉识别给它的信息并且给出非常拟人化的反馈。

说实话,在直播发布会中直接现场演示这件事情是很需要勇气的,因为一旦出错会引发非常大的公关灾难,但OpenAI有这个勇气去直接现场演示直播,给人的感觉非常自信。除了现场的演示之外,OpenAI还在官网上放出了更多更复杂场景的交互,展现出AI多模态的更多的潜力。
比如说,在官网上OpenAI做了17个案例展示,包括了照片转漫画、3D物体合成、海报创作、角色设计等样本。
此外,OpenAI总裁Greg Brockman的演示视频中,GPT-4o可以识别出他所穿的衣服、身处的环境、可以识别出Brockman的情绪和语气和房间里正出现的新动作,但最让外界关注的一个动作是,让两台运行GPT-4o的设备进行语音或视频交互。
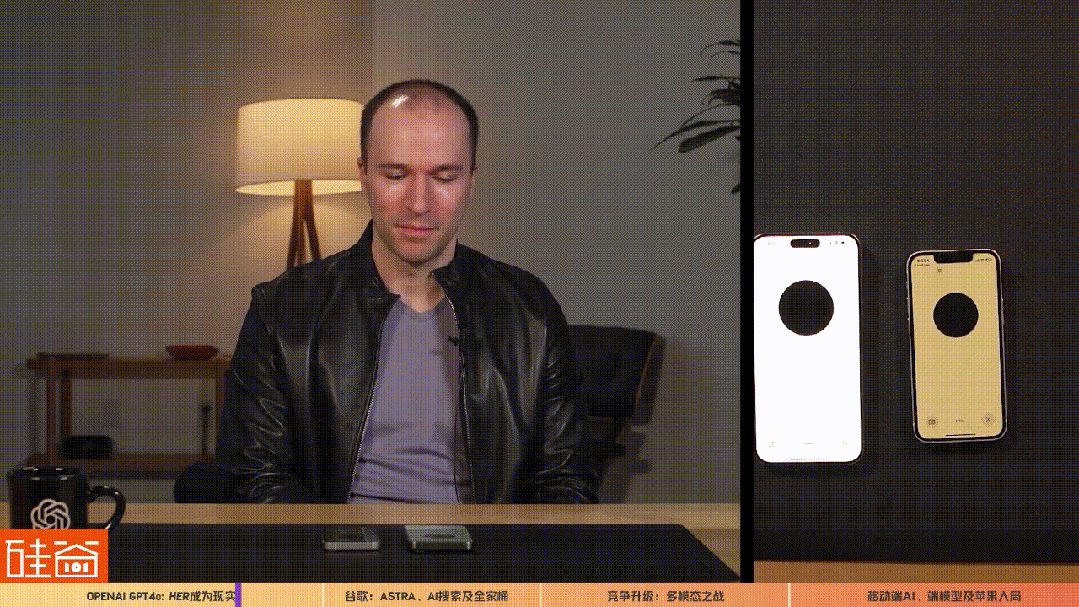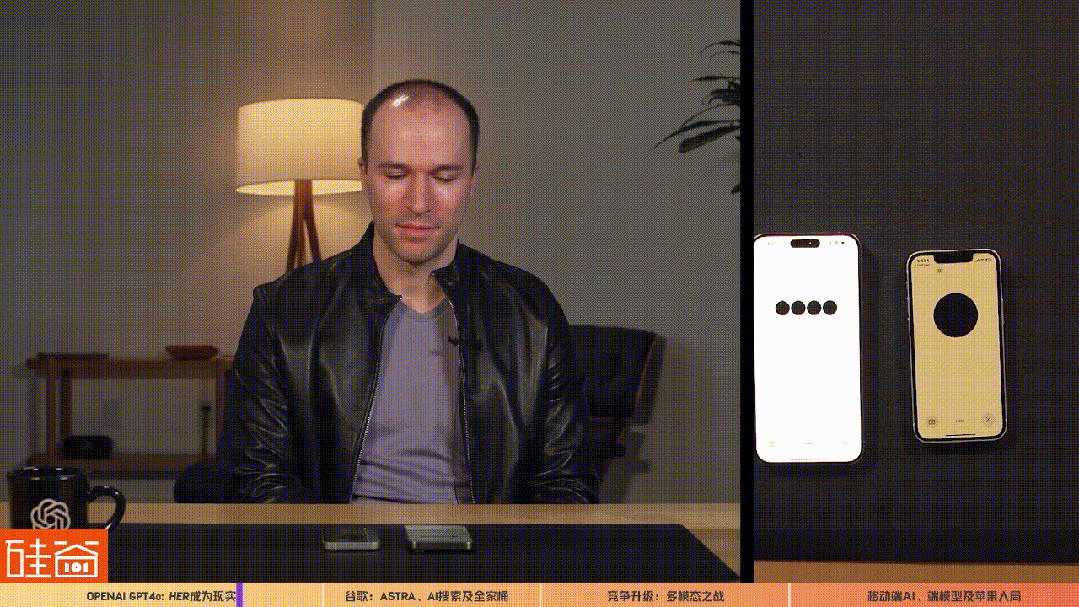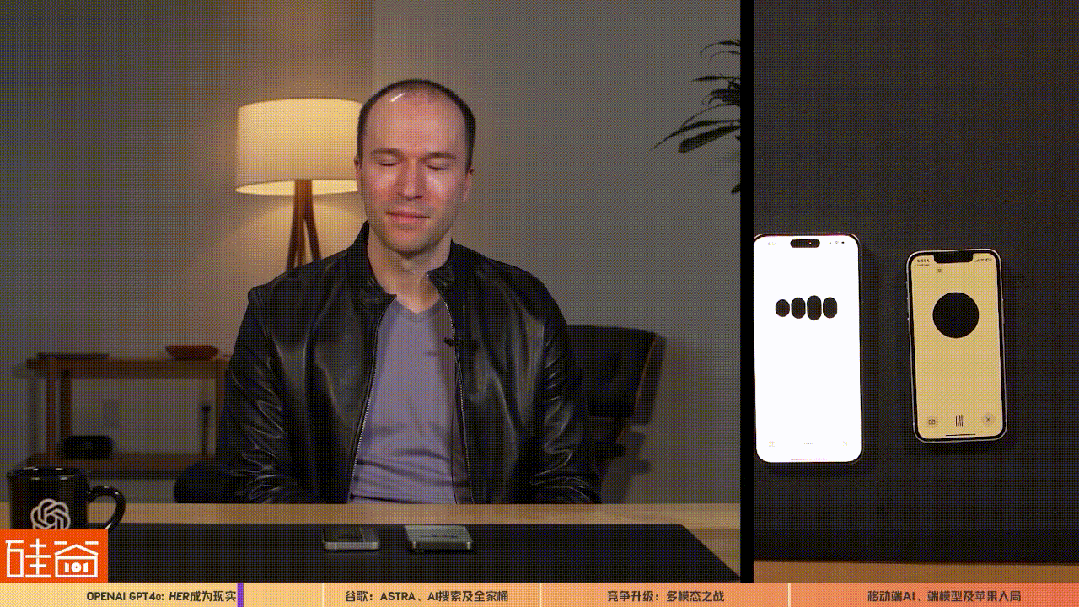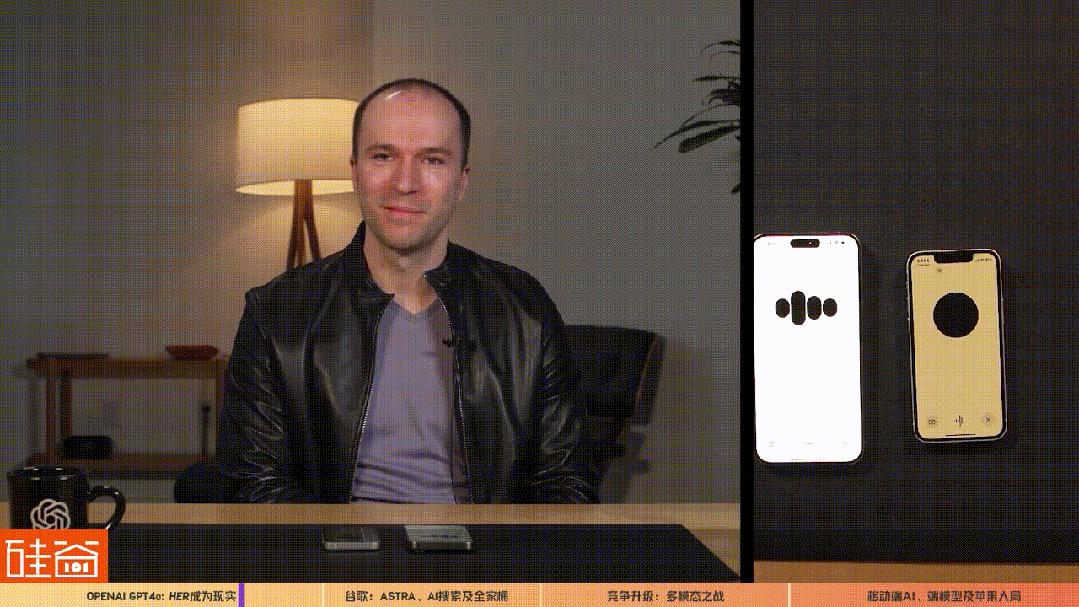
也就是说,OpenAI的GPT-4o多模态给了AI交互的声音和视觉,不仅升级了人和AI之间的交互,也升级了AI和AI之间的交互,这样的交互更自然,更拟人,有着更大空间的应用场景。而且整个AI的声音和语言非常的灵动,机器人感比较弱,会开玩笑会安慰人会害羞,难怪很多人在OpenAI发布会之后直呼,那部讲述人类和AI语音助手Samantha电影《Her》的时代真的到来了。

戴雨森(真格基金管理合伙人):
我自己是非常激动的。因为我一直觉得我们对于 AI 落地的应用预期,其实不一定是准确的,大家可能在AI一开始的时候,觉得生产力的场景也很直接,但是现在可能发现,很多(AI)Agent(人工智能体)的落地反而比较难,但是感性的角度反而会更加容易一点。
对于绝大部分人来讲,生活其实是单调的,或者是一成不变的,是乏味的。那这个时候其实不管像 《Her》 里面说所谓的这种,男女情感的表达,还是说一种陪伴、一种倾听,其实都是很稀缺的一种资源或内容。当 AI 能够做到以一个低延迟、低成本,很好的形式去表达这种情绪价值的时候,这可能会对我们的社交社会带来很大的影响,也会带来很大的这个机会。
随着AI能力的提升,图灵测试这个概念会越来越模糊化,电影《Her》中描述的场景实现几乎是早晚的事。但AI多模态带来的不仅仅是情感上的陪伴和交互,更多的是整个工作场景和生态上的颠覆。
就在OpenAI发布会的一天之后,谷歌发布的一系列多模态更新,进一步说明了AI多模态能带来的颠覆性潜力。
谷歌的战书:Project Astra及“120次AI”的全生态升级
对比起OpenAI的发布会,谷歌的发布会就更像一个巨头了:长达两小时,在各个生态方向用AI发力。连CEO Sundar Pichai自己也说,整场Keynote的演讲稿里总共提了120次“AI”,表明谷歌目前所有的工作都围绕多模态AI模型Gemini来展开。

首先,直接与OpenAI前一天发布的GPT-4o对标的是Project Astra。

语音助手Project Astra
虽然谷歌不是现场演示,不像OpenAI那么激进,毕竟巨头还是需要保守一些,但从谷歌的demo视频来看,如果谷歌的demo是实时生成的,谷歌的Gemini多模态模型比起OpenAI在功能上也不算弱。
谷歌DeepMind负责人Demis Hassabis在台上宣布了Project Astra,Project Astra基于Gemini多模态大模型,是一个实时、多模态的人工智能助手,可以通过硬件设备“看到”世界,知道东西是什么以及你把它们放在哪里,并且可以回答问题或帮助你做几乎任何事情。在谷歌的demo视频中,谷歌伦敦办事处的一名工作人员用Astra识别自己的地理位置,找到丢失的眼镜,检查代码等等。

如果谷歌demo是实时拍摄的,反正Demis Hassabis是打包票说这个视频没有任何篡改,那么毫无疑问这会解锁众多的交互场景。Hassabis说,“展望未来,人工智能的故事将不再是关于模型本身,而是关于它们能为你做什么”。
而与OpenAI的GPT4o宣战的Project Astra只是其中的一个产品而已,谷歌其实发布了非常多的更新,包括谷歌展示了最新版Gemini加持的搜索功能。
AI搜索
谷歌首先在美国上线名为AI Overviews的AI技术生成摘要功能。简单来说,在你搜索信息的时候,谷歌的AI就直接帮你查找、整理和展示了。具体来说,通过多步推理,Gemini可以代替用户研究,实现更好更高效的搜索总结和结果,比如说规划一日三餐,购物餐厅选择,行程规划,都可以在AI搜索中完成,更重要的是,这样的AI搜索还会直接帮你做规划,比如说“帮我创建一个3天的饮食计划”,谷歌AI搜索就直接一个计划书摆在你面前了。
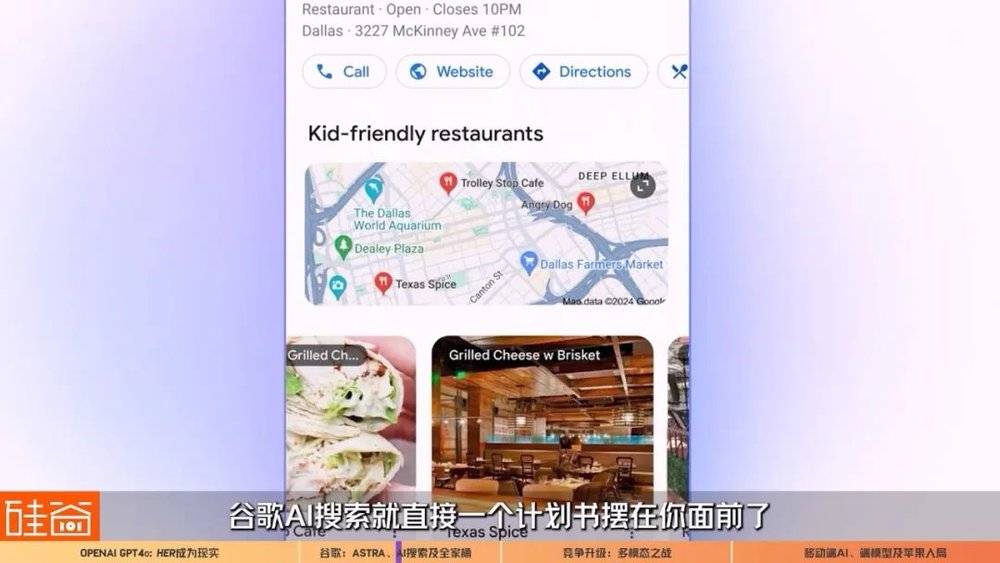
另外让我觉得很期待的两个功能,一个是多模态搜索。你会不会遇到过这种情况,搜索时发现难以用语言来描述问题,或者遇到不熟悉不认识的物体,不知道如何去搜索相关的名词。
现在你就可以直接拍张照片或者录段视频用语音或打字问AI搜索,这个是啥,怎么修理,之后谷歌就会帮你整理出相关的各种信息。

对于我这种3C杀手、经常容易弄坏各种电器的人来说,我简直太期待这个多模态搜索功能了。而多模态模型Gemini的强大搜索和推理能力还能做更多的事情,也正好是我的痛点。
比如说,CEO Pichai在现场演示,Gemini可以在谷歌相册Google Photos里进行更多的相关搜索,比如通过名为Ask Photos with Gemini的新功能让Gemini找到用户想要的车牌照号。
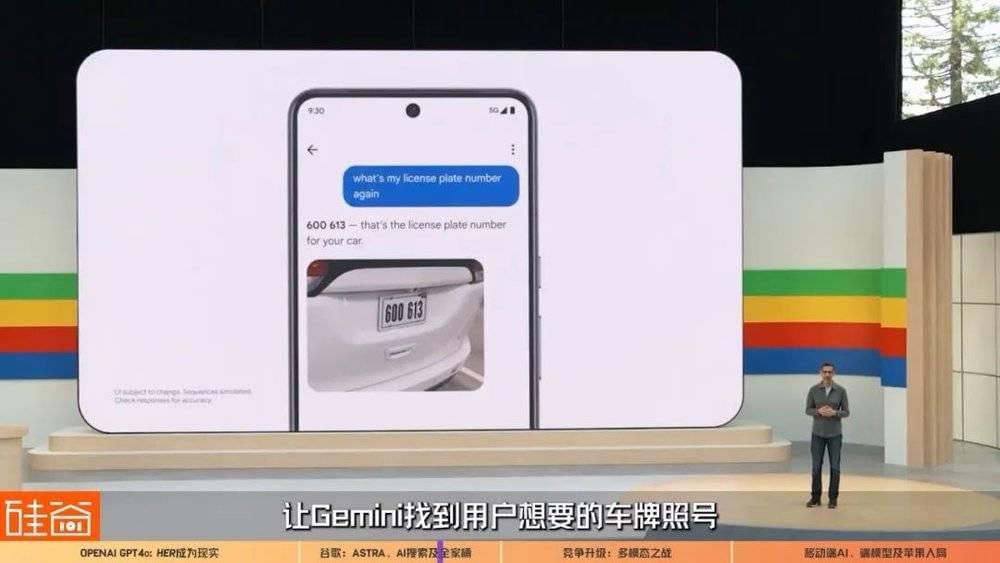
实话告诉大家,我就是那个记不住我家车牌号的人,所以,谷歌Gemini可以在用户的相册中搜索,找到相应信息和对应的照片,比如说获取照片中拍到的车牌照号码,这个功能对我来说,真的是非常期待。以及任何可以帮我寻找以往照片、文 件中信息的功能,我觉得都会解决很多痛点。
还有一个对我来说很大帮助的是,谷歌AI将会结合到谷歌的所有workspace中,俗称“谷歌全家桶”,也就是说,在Gemini的加持下,Google Workspace,包括Gmail、Google Docs、Google Drive、Google Calendar、Google Meet等都可以打通,可以在这里进行跨文档搜索。比如说,你在邮箱里收到了一张发票,那么可以直接通过Gemini,把这张发票,整理到网盘Google Drive和表格Google Sheet中。还可以在邮件中搜索、读取信息和亮点、归纳总结,这些功能都会在今年稍后推出。
另外谷歌还发布了一系列其他的模型更新,包括画图的Imagen 3,音乐的Music AI Sandbox,还有生成视频的Veo,还有有史以来最长、上下文窗口200万token的Gemini 1.5 Pro,还有Gemini app以及谷歌的自研芯片第6代TPU等等,因为细节和产品太多了这个视频我们就不一一复述了,如果感兴趣的小伙伴可以去看看谷歌的两小时发布会全程。
看到这里,你可能会问,在OpenAI之后发布这一系列重磅更新的谷歌,两个对手这一轮的发布,谁是赢家呢?
OpenAI vs. Google:多模态之战与AI的应用落地
两场发布会之后,我看到不少人在对比OpenAI和谷歌的产品发布。我们从公司策略层来解读一下。
首先,OpenAI比谷歌I/O早一天发布了春季更新,而且非常临时,很难说是不是故意抢在谷歌前面的,发布时长也只持续26分钟,非常聚焦在GPT-4o这一个产品上。虽然外界对GPT-4o的评价没有说像当时发布ChatGPT时那么惊喜那么轰动,但不得不说,业内的很多人觉得这是一个很重要的里程碑。
多模态的这些功能是去年业内共识,OpenAI会在2024年做出来并发布,并没有那么多惊喜或创新,但是“实现”了大家“期待中早晚会实现的AI更新”,也是非常有意义的,并且也是正确的发展道路。
Howie Xu(AI及云服务行业高管、斯坦福大学客座教授):
OpenAI这个GPT 4模型出来,也能够做些translation(翻译),翻译什么的并不是一个新东西,如果没有实时效应,其实是很难落地,但星期一他那个宣布的东西,让我感觉到我有可能真的会去用,比如下次我跟你一起去采访谁或者跟谁讲话,语言不通(的时候),我们真的可能就打开我们的手机来给来用translation。就以前的,那个延迟这么慢,效果很不好,你都不好意思拿出来就用对吧?
那为什么能够做到延迟性这么低,那被广泛认为的就是因为它是做到了Native(原生的)Multimodal(多模态模型),我看到那个demo,我的第一反应是说OK,以前他说的这些东西我都是玩玩是可以的,但是我是不会拎出来用的,但是他星期一给我的东西,我就觉得有可能我会拿来,就在实际的生活工作的场景里面可能用得到。

如果光从语音助手这个产品上来看,GPT-4o对打谷歌Project Astra,目前业内很多声音仍然认为OpenAI是领先的。单从多模态模型上来说,GPT-4o是OpenAI第一款完全原生的多模态模型。
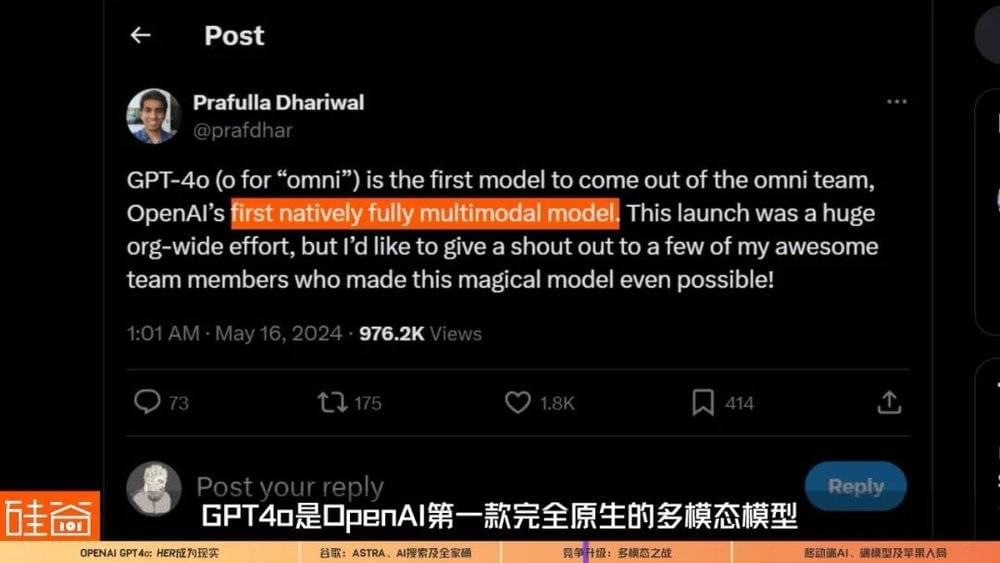
我们之前也说到,它所有的多模态输入和输出都由同一个神经网络处理,这使得GPT-4o能够接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合输出,是所谓的“multimodal in(多模态输入), multimodal out(多模态输出)”。
但目前不少业内人士认为,谷歌的Gemini目前并没有做到这个程度,比如说英伟达高级科学家Jim Fan在LinkedIn上发表观点认为,谷歌是多模态作为输入,但并不是多模态作为输出(multimodal in, but not multimodal out)。
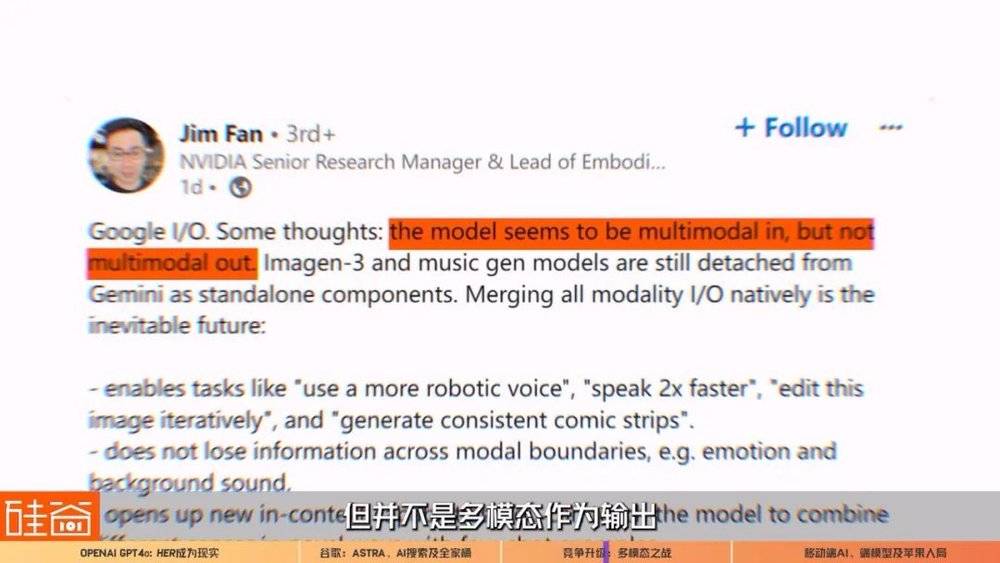
这意味着谷歌本次更新的视频、音乐等模型依然是独立于Gemini大模型的存在,只是输出的时候把所有模型给整合起来拥有的多模态输出能力。所以Jim Fan认为,谷歌整合所有的输入输出模态,将是不可避免的未来发展趋势。
但他还有一句评论挺有意思的,Jim Fan说,谷歌在这次发布会中做对的一件事是:“他们终于认真努力将AI集成到搜索框中。谷歌最坚固的护城河是分销,Gemini不一定要成为最好的模型,才能成为世界上被使用最多的模型。”

也就是说,谷歌在整个生态中只要顺畅融入AI功能,让用户觉得能解决问题,提高生活和工作效率,因为谷歌在搜索、邮箱、谷歌云上的种种积累和优势,谷歌的分销优势依然能保证谷歌在AI时代中立于不败之地。
所以,按照这个逻辑来看,谷歌在这次发布会上全生态全面升级AI功能,其实是做到了。所以,就算OpenAI前一天抢跑发布亮点颇多的GPT-4o,谷歌整体来看,这一局也不算输,第二天的股价稳中上涨也印证了市场的看法。
戴雨森(真格基金管理合伙人):
OpenAI发布会之后,Google 发布会之前,我跟一位Google的同学聊,然后他提到一个观点还挺有意思。他说一年以前OpenAI发GPT4的时候,他们有很多东西,他们是不知道OpenAI怎么做到的,觉得他们好厉害。现在OpenAI发布会发了之后,他们看到,这个东西我们也知道怎么做,但我们可能还没有像他那样做得那么好,或者那么ready(准备好)去demo,所以我觉得目前来看的话,他们肯定在这上面是有一些经验,所以我感觉就是双方的绝对差距还是在缩小的。
Howie Xu(AI及云服务行业高管、斯坦福大学客座教授):
相对来讲,Google注重的是一个solution(解决方案),就是解决方案,那个OpenAI目前注重的,更多的还是一个technology(技术),它在technology(技术)上面非常的惊艳,但你说他怎么去跟我们人的日常,不管是生活、工作去结合起来,他没有那么多的人力,他也没这么多思考,而且这不是他的强项。
Google I/O的那个发布,看上去可能从某些角度来讲,好像还没有那个前一天,OpenAI的东西那么惊艳,但实际上我觉得很惊艳,我觉得惊艳不只是说是一个model(模型)的惊艳,model只是一个维度,还有其他维度,怎么跟我的生活、工作能够结合起来,比如说跟我的手机结合起来,它一些的announcement(发布)是这个技术,所以说AI这件技术,我觉得今天落地是一个很大的一个挑战,或者说一件事情。
所以可以预期,接下来,多模态的继续整合和优化,以及将AI功能整合到谷歌的各个产品中,以及AI agent(人工智能体)的引入,将会是谷歌发力的重点。除此之外,这两场发布会听下来还让我非常感兴趣的一点是硬件。
OpenAI整个demo用的是苹果手机和苹果电脑,谷歌用的是安卓手机和硬件,同时还在视频demo中提到了一个谷歌内部类似谷歌眼镜一样的prototype原型设配,所以接下来,硬件和AI大模型的整合,也到了加入战场的时刻。而这个赛道的老大,苹果,在干什么呢?
移动端AI大战开启,苹果即将入局?
虽然苹果公司在这轮硅谷科技巨头AI大战中迟迟没有发声,但最近有不少的舆论风向稍微给我们勾勒出了苹果潜在的想法和布局。
目前市场都在等待6月10日举行的苹果2024年全球开发者大会WWDC,预计会在届时会宣布一系列在AI和硬件上的产品发布。
包括可能会和OpenAI合作,将ChatGPT整合到iOS 18操作系统,此外,外界期待苹果会宣布利用大模型全面升级Siri,给用户提供AI赋能的交互体验,还有苹果如何将大模型塞进手机移动端的“苹果全家桶”,也是马上召开的苹果发布会的最大看点。
今年早前,苹果发布了一系列的论文,包括第一个手机端UI多模态大模型Ferret-UI。

还有今年一月发布的一篇将大模型塞进iPhone的关键性论文,“使用有限的内存实现更快的LLM推理”。

还有这篇,苹果Siri团队在论文《利用大型语言模型进行设备指向性语音检测的多模态方法》中讨论了去掉唤醒词的方法。

同时, 在今年3月发布的另外一篇论文中,苹果首次披露一个具有高达300亿参数的多模态模型MM1,这个多模态能力如果集成到iPhone上,就能够通过视觉、语音和文本等多种方式理解并响应用户的需求。
所以综上所述,虽然近两年来,苹果时常为人诟病在AI领域动作迟缓,但是感觉,苹果是在等一个正确的时机来加入战局,它并没有落后,而是一直在等待。如今,多模态技术成熟,特别是文字输入、语音和视觉的交互和手机等硬件是天然的适配,OpenAI和谷歌的AI多模态之战打响之际,也是苹果入局的最佳时间了。
戴雨森(真格基金管理合伙人):
如果你看互联网和移动互联网时代,其实它们在软件的渗透上,都要叠加一个硬件的渗透,大家要买PC、手机,所以导致,之前软件的渗透速度,其实是相对比较慢的,那为什么ChatGPT一出来就渗透到了这么多的用户,实际上是因为它跑在一个,比较成熟的硬件上。
所以目前来讲,AI落地肯定首选还是在手机上,我肯定是期待像AI的这些模型,怎么样在苹果的生态系统中去落地,其实说全新形态的硬件,我自己觉得可能性比较低,但是在这个上面有了,包括最近刚发M4 对吧,大家说iPad这个上面有这么强的这个芯片,你如果还是做原来的任务,是不是就浪费了,你是不是用来干一些AI的任务呢?
而对于智能手机、智能手表、乃至于以后的VR和AR眼镜设备,更小的端模型将是业界着重发力的重点。在今年4月,苹果宣布在全球最大AI开源社区Hugging Face发布了全新的开源大型语言OpenELM系列模型,包括4个不同参数规模的模型:270 Million(百万)、450 Million(百万)、1.1 Billion(十亿)和3 Billion(十亿),没错,最大的也只有30亿个参数,对移动端小模型的布局有着明显的意图。而Howie Xu在采访中认为,端模型是人类应用AI发展的必然趋势。
Howie Xu(AI及云服务行业高管、斯坦福大学客座教授):
个人非常看好端模型,因为过去一年我们大量的讨论都集中在越大越好,但是万亿级的parameter(参数),不适合放在手机上面,那另外一个问题就是说,那个不是万亿级的,千亿级的,或者百亿级的参数,是不是能够把模型做到足够好。
现在我们看到的很多的小的模型可能是700亿参数的,一年之内我们能够看到就是,十亿这么一个参数的一个模型,能够做到当初ChatGPT出来时候,让大家惊艳的那个感觉,相当于(GPT)3.5的那个model(模型)的能力,我觉得是一个billion(十亿)的parameter(参数)是应该能够做到。
如果能够这个端上面能够运行一个十亿参数级别的模型,能够做到(GPT)3.5的(的能力),那就打开了很多的想象空间,然后接下去会有更小的模型,因为模型总归是越小,对耗电、对各方面的都有很大好处,我觉得甚至是sub 1 billion(小于10亿参数)的会更好,从privacy(隐私)的角度,从耗电的角度,从各方面角度,我觉得小模型是必须的。
文章的最后,我们来总结一下OpenAI和谷歌的这两场发布会,AI多模态之战打响之后,在更多更广的应用上,我们看到了AI杀手级应用的曙光,有了更落地更切实的可用性,这将重塑人类和AI以及电子设备的交互方式。
此外,虽然OpenAI和谷歌表面上刀光剑影,但两家公司的策略目标是有些区别的:前者一路勇向前目标scaling law(规模法则)和AGI,后者更注重自家生态和应用落地来捍卫商业营收与市场分销护城河——可能模型是不是最好的,并没有那么重要。所以目前的多模态初战,OpenAI虽然赢了,但谷歌也没输。

而在硬件端,各类硬件与AI的结合将带来巨大的新机会,而大模型“瘦身”进手机只是开始,打造应用体验才是关键所在。
此外,让人惊喜的是谷歌demo最后展示的AR眼镜与AI的结合,这给“AR智能眼镜”这个起起伏伏了好几个周期的产品,带来了新的曙光和希望,除了谷歌多年的AR经验,Meta在AR硬件上的布局,与苹果在Vision Pro以及自家AR团队的未来策略,都可能成为下一场科技硬件巨头们比拼的新战场。
对了,不要忘记微软这家与OpenAI深度绑定的巨头,它并没有将全部鸡蛋都放在OpenAI的篮子中。微软目前在AI布局上的优势,加上在软硬件上都有多年经验和布局,最近还收编了之前主打情感陪伴大模型公司Inflection的大部分AI顶级人才、发布了自己的大模型MAI-1。
所以我们很兴奋能感觉到,生成式AI的第二轮多模态战役打响了,越来越多的科技巨头入局,并且战术和方向也越发清晰,带来的是AI应用的潜在落地与爆发。
本文来自微信公众号:硅谷101(ID:TheValley101),作者:陈茜inTheValley