
本文为图解 Transformer 的第三篇文章。在前两篇文章中,我们学习了何为 Transformer,其架构及工作原理。本文将在此基础上进一步探讨作为 Transformer 核心的多头注意力机制(Multi-head Attentions)。
以下为本系列前几篇文章的摘要。在整个系列中,我希望读者不仅能了解这些东西是如何运行的,还要进一步理解它们为何这样运行。
1. 图解 Transformer——功能概览:阐述如何使用 Transformer,为什么 Transformer 优于 RNN,以及 Transformer 的架构,和其在训练和推理过程中的运行。
2. 图解 Transformer——逐层介绍:阐述 Transformer 如何运行,从数据维度变化或矩阵变换的角度,端到端地阐释了 Transformer 内部的运作机制。
本文在前两篇的基础上,探讨多头注意力机制(Multi-head Attentions),旨在说明注意力机制在整个 Transformer 中的工作原理。
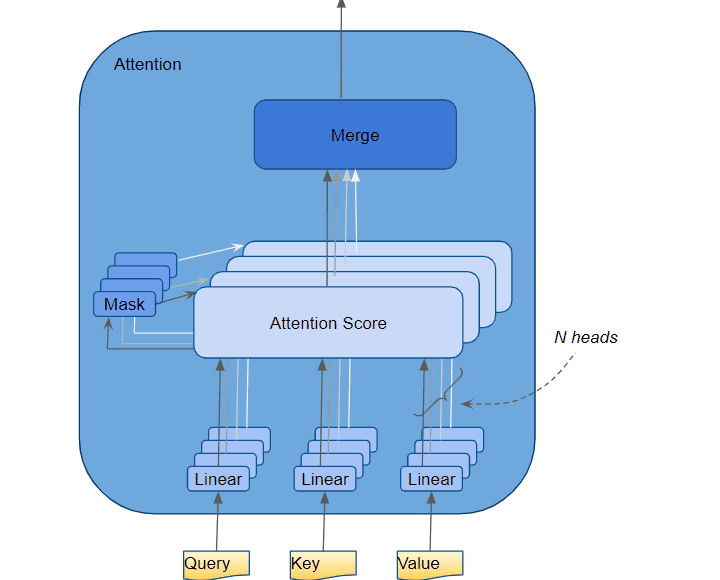
在 Transformer 中,注意力模块会并行多次重复计算。每个并行计算称为一个注意力头(Attention Head)。注意力模块将其查询 Query 、键 Key和值 Value的参数矩阵进行 N 次拆分,并将每次拆分独立通过一个单独的注意力头。最后,所有这些相同的注意力计算会合并在一起,产生最终的注意力分数。能够更细致地捕捉并表达每个词汇之间的多种联系和微妙差异。
一、注意力超参数(Attention Hyperparameters)
Transformer 内部流动的数据维度由三个超参数决定:
Embedding Size:嵌入向量的大小(例子中使用的嵌入向量大小为6)。这个维度在整个 Transformer 模型中都是向前传递的,因此有时也被称为“model size - 模型大小”等其他名称。
Query Size(与 Key size 和 Value size 相等):查询向量的长度,与键向量和值向量的长度相等,也是分别用来产生Query、Key 和 Value矩阵的三个线性层的权重大小(例子中使用的查询大小为3)。
Number of Attention heads:注意力头个数。例子中使用注意力头个数为 2 。
此外,还有 Batch_size,批量大小,是一次输入模型中样本的数量。
二、输入层(Input Layer)
经过词嵌入和位置编码后,进入编码器之前,输入的数据维度为:
(batch_size, seq_length, embedding_size)
之后数据进入编码器堆栈中的第一个 Encoder,与 Query、Key、Value 矩阵相乘。
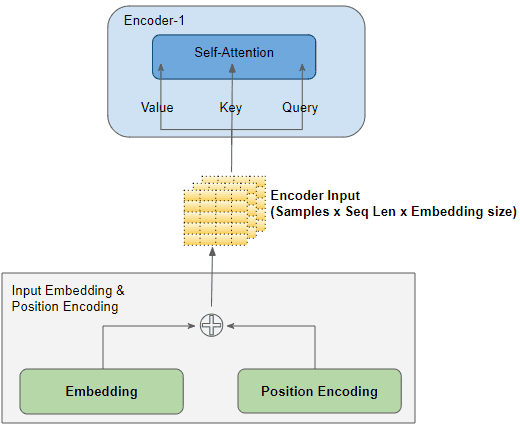
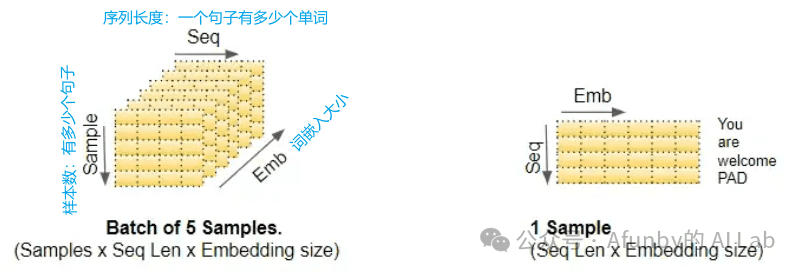
为方便理解,以下的图示与介绍中将去掉 batch_size 维度,聚焦于剩下的维度:
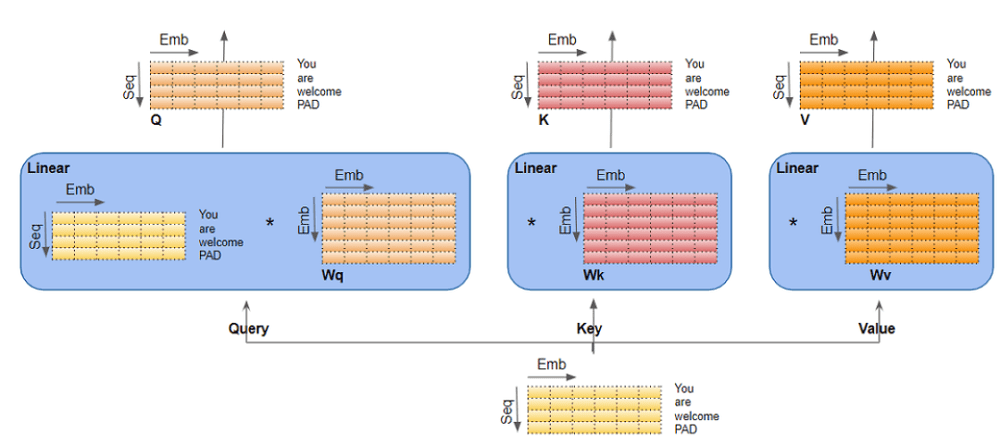
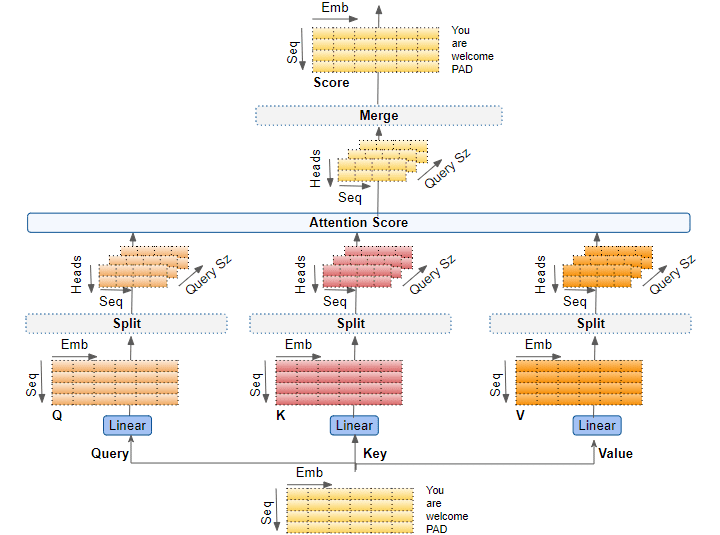
三、线性层(Linear Layers)
Query, Key, Value 实际上是三个独立的线性层。每个线性层都有自己独立的权重。输入数据与三个线性层分别相乘,产生 Q、K、V。
四、通过注意力头切分数据(Splitting data across Attention heads)
现在,数据被分割到多个注意头中,以便每个注意头能够独立地处理它。
需要注意:
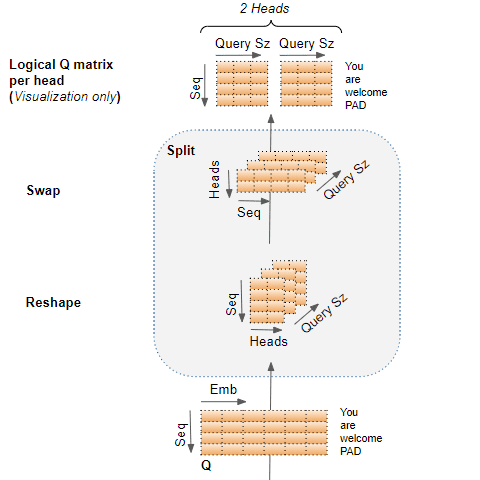
1. “切分”只是逻辑上的分割。对于参数矩阵 Query, Key, Value 而言,并没有物理切分成对应于每个注意力头的独立矩阵。
2. 逻辑上,每个注意力头对应于 Query, Key, Value 的独立一部分。各注意力头没有单独的线性层,而是所有的注意力头共用线性层,只是不同的注意力头在独属于各自的逻辑部分上进行操作。
这种切分可以按照两个步骤理解:
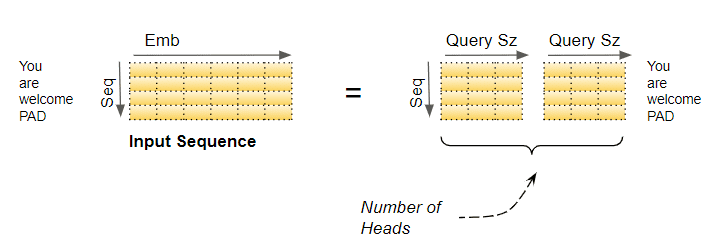
第一步,线性层权重矩阵的切分。
这种逻辑分割,是通过将输入数据以及线性层权重,均匀划分到各注意头中来完成的。我们可以通过选择下面的 Query Size大小来实现:


在我们的例子中,这就是为什么 Query_Size=6/2=3。尽管层权重(和输入数据)均为单一矩阵,我们可以认为它是“将每个头的独立层权重‘堆叠’在一起”成为一个矩阵。
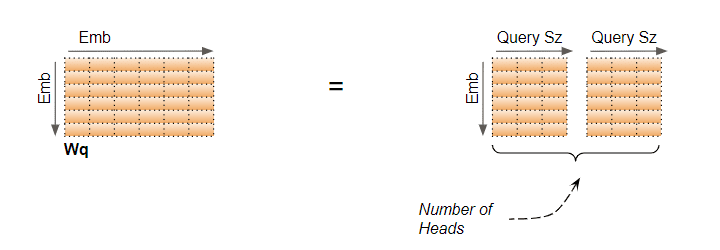
也因此,在代码中定义 W_Q、W_K、W_V 矩阵时可这样定义:
self.W_Q = nn.Linear(embedding_size, Query_size * n_heads, bias=False) self.W_K = nn.Linear(embedding_size, Query_size * n_heads, bias=False)self.W_V = nn.Linear(embedding_size, Value_size * n_heads, bias=False)
基于此,所有 Heads 的计算可通过对一个的矩阵操作来实现,而不需要 N 个单独操作。这使得计算更加有效,同时保持模型的简单:所需线性层更少,同时获得了多头注意力的效果。
回顾前一小节的内容,input 的维度是:
(batch_size, seq_length, embedding_size)
而线性层的维度是:
(batch_size, embedding_size, Query_size * n_heads)
由于 embedding_size = Query_size * n_heads,所以线性层的维度并未发生变化。
输入经过线性层映射后,得到 Q、K 和 V 矩阵形状是:
(batch_size, seq_length, Query_size * n_heads)
第二步,重塑 Q、K 和 V 矩阵形状。
经由线性层输出得到的 Q、K 和 V 矩阵要经过 Reshape 操作,以产生一个 Head 维度。现在每个“切片”对应于代表每个头的一个矩阵。
通过交换 n_heads 和 seq_length 这两个维度,改变 Q、K 和 V 矩阵的形状。图示中虽然未表达出 Batch 维度,但对应于每一个注意力头的 'Q' 的维度是:
(batch_size, n_heads, seq_length, Query size)
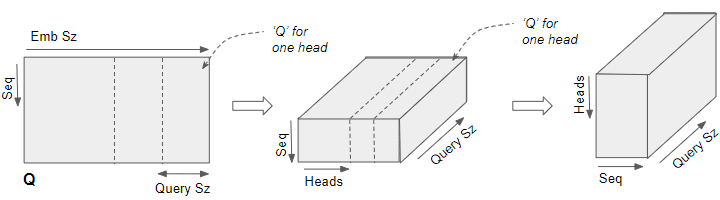
在上图中,我们可以看到从线性层 (Wq) 出来后,分割 Q 矩阵的完整过程。
最后一个阶段只是为了形象化。
实际上 Q 矩阵仍然是一个单一矩阵,但可以把它看作是每个注意力头的逻辑上独立的 Q 矩阵。
五、为每个头计算注意力分数(Compute the Attention Score for each head)
现在有了分属各头的 Q、K、V 3个矩阵,这些矩阵用来计算注意力分数。
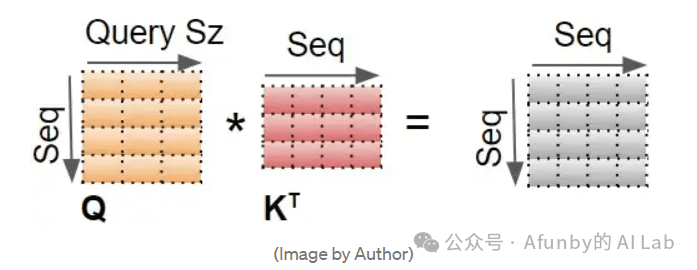
为方便理解,只展示单个 head 的计算。使用最后两个维度(seq_length, Query size),跳过前两个维度(batch_size, n_heads)。从本质上讲,可以想象,计算对于每个头和每个批次中的每个样本都是“重复”进行的(虽然实际上它们是作为一个单一矩阵操作进行的)。
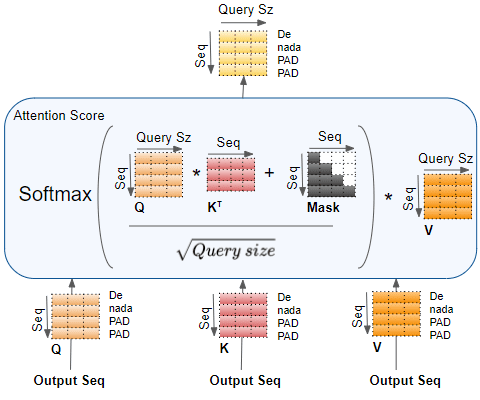
1. 在 Q 和 K 的转置矩阵做一个矩阵乘法。
2. 将掩码值被添加到结果中。在 Encoder Self-attention 中,掩码用于掩盖填充值,这样它们就不会参与到注意分数中。
3. 上一步的结果通过除以 Query size 的平方根进行缩放,然后对其应用Softmax。
4. 在 Softmax 的输出和 V 矩阵之间进行另一个矩阵乘法。
在 Encoder Self-attention 中,一个注意力头的完整注意力计算如下图所示:
每个注意力头的输出形状为:
(batch_size,n_heads,seq_length,Query size)
注意,实际上此处最后一个维度的大小为 value_size,只是在 Transformer 中 value_size=key_size=query_size。
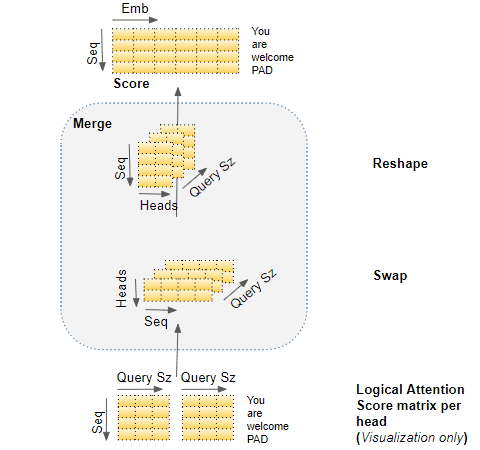
六、融合每个头的注意力分数(Merge each Head's Attention Scores together)
我们现在对每个头都有单独的注意力分数,需要将其合并为一个分数。这个合并操作本质上是与分割操作相反,通过重塑结果矩阵以消除 n_heads 维度来完成的。其步骤如下:
1. 交换头部和序列维度来重塑注意力分数矩阵。换句话说,矩阵的形状从(batch_size,n_heads,seq_length,Query_size)变为(batch_size,seq_length,n_heads,Query_size)。
2. 通过重塑为 (Batch, Sequence,Head * Query size)折叠头部维度。这就有效地将每个头的注意得分向量连接成一个合并的注意得分。
由于 embedding_size=n_heads * query_size ,合并后的分数是(batch_size,seq_length,embedding_size)。在下图中,我们可以看到分数矩阵的完整合并过程:
(在李沐的代码中,直接使用 permute 和 reshape 两次变换就可以)
整体上多头注意力的计算过程如下:
七、多头分割可以捕捉到更丰富的表示(Multi-head split captures richer interpretations)
一个嵌入向量捕捉了一个词的含义。在 Multi-head Attention 的机制下,正如我们所见,输入(和目标)序列的嵌入向量在逻辑上被分割到多个头。
这意味着,嵌入向量的不同部分可以表征每个词在不同方面的含义,而每个词不同的含义与序列中的其他词有关。这使得 Transformer 能够捕捉到对序列更丰富的表示。
例如,嵌入向量的某一部分可以捕获一个名词的词性,而另一个部分可以捕获一个名词的单复数。这在翻译中很重要,许多语言中,动词的使用与这些因素有关。
以上虽然不是一个现实的例子,但它可能有助于建立直觉。例如,一个部分可以捕捉名词的“性别”(男、女、中性),而另一个部分则可以捕捉名词的“词性”(单数与复数)。这在翻译过程中可能很重要,因为在许多语言中,需要使用的动词取决于这些因素。
八、解码器中的“编码器-解码器注意力”与“掩码操作”(Decoder Encoder-Decoder Attention and Masking)
“编码器-解码器注意力”从两个来源获得输入。因此,与计算输入中每个词与其他词之间相互作用的 Encoder Self-Attention 不同;也与计算每个目标词与其他目标词之间相互作用的 Decoder-Self-Attention 不同,“编码器-解码器注意力”计算的是每个 input word 与每个 target word之间的相互作用。
因此,所产生的注意分数中的每一个单元都对应于一个 Q(target sequence word)与所有其他 K(input sequence)词和所有 V(input sequence)词之间的相互作用。
九、总结
希望这能让你对 Transformer 中 Attention 的模块作用有一个很好认识。当与我们在第二篇文章中提到的整个 Transformer 的端到端流程放在一起时,我们现在已经涵盖了整个Transformer架构的详细操作。
我们现在明白了 Transformer 到底是做什么的。但是我们还没有完全回答为什么 Transformer 的 Attention 要进行这样的计算,为什么它要使用查询、键和值的概念,为什么它要执行我们刚才看到的矩阵乘法?
我们有一个模糊的直观想法,即它“抓住了每个词与其他词之间的关系”,但这到底是什么意思?这到底是如何让转化器的注意力有能力理解序列中每个词的细微差别的?
这是一个有趣的问题,也是本系列的最后一篇文章的主题。一旦我们了解了这一点,我们就会真正理解 Transformer 架构的优雅之处。
原文链接:https://towardsdatascience.com/Transformers-explained-visually-part-3-multi-head-attention-deep-dive-1c1ff1024853
本文来自微信公众号:Afunby的 AI Lab(ID:AI_Lab_of_Afunby),作者:Afunby