
真正的具身智能提前一年到来?
创建不到两年、估值26亿美元的机器人初创公司Figure, 在X上亮相它与OpenAI的首次合作。全尺寸仿人机器人Figure 01正与人类和环境互动,展示它所拥有的识别、计划和执行任务的能力。
Figure 机器人背后的技术原理是什么?OpenAI为其配置的智慧大脑是怎样运作的?与Google发布的机器人系统RT-1、PaLM-E、RT-2是怎样的关系?
以下我们将做以简要解读。
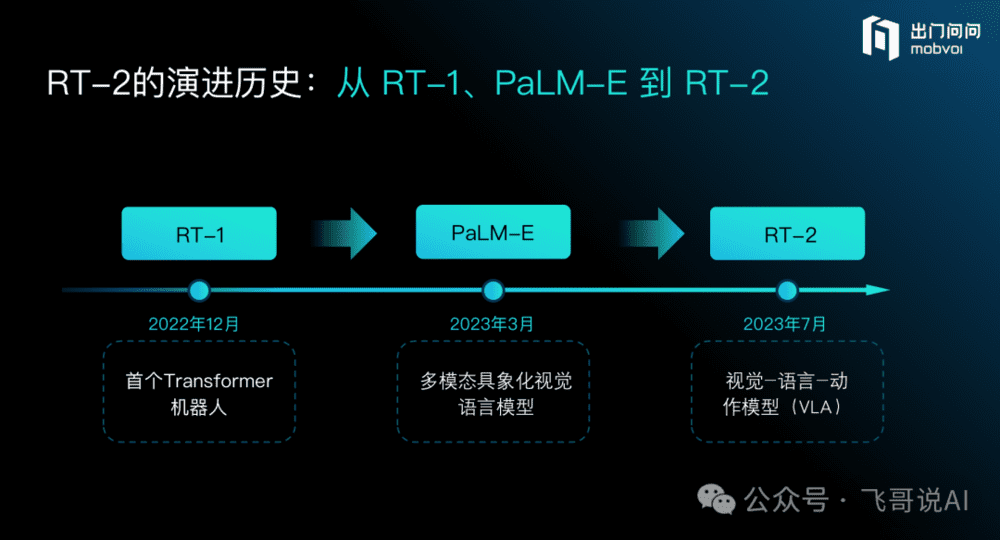
一、原理:Figure类似PaLM-E + RT-1,而非端到端的RT-2
原理上,机器人Figure 看起来类似于Google在2023年3月发布的PaLM-E和RT-1的pipeline组合,而不是Google于2023年7月发布的端到端模型 RT-2。
我们知道,如果机器人要与人进行自然语言交互(比如,人说“把桌子上的苹果拿给主人”),可以大致分为以下两个步骤。
一是机器理解自然语言,并把自然语言转换成机器的抽象计划(所谓 high-level planning),这个抽象的计划可能是一系列的简单自然语言指令(比说“拿起苹果”、“把苹果移到人手上方”、“放开苹果”)。
二是把这个抽象计划转换成底层具体的操控(所谓 low-level 执行),既把简单的自然语言指令转换成一系列的具体动作(比如旋转、移动、抓取、放开等基本动作)。
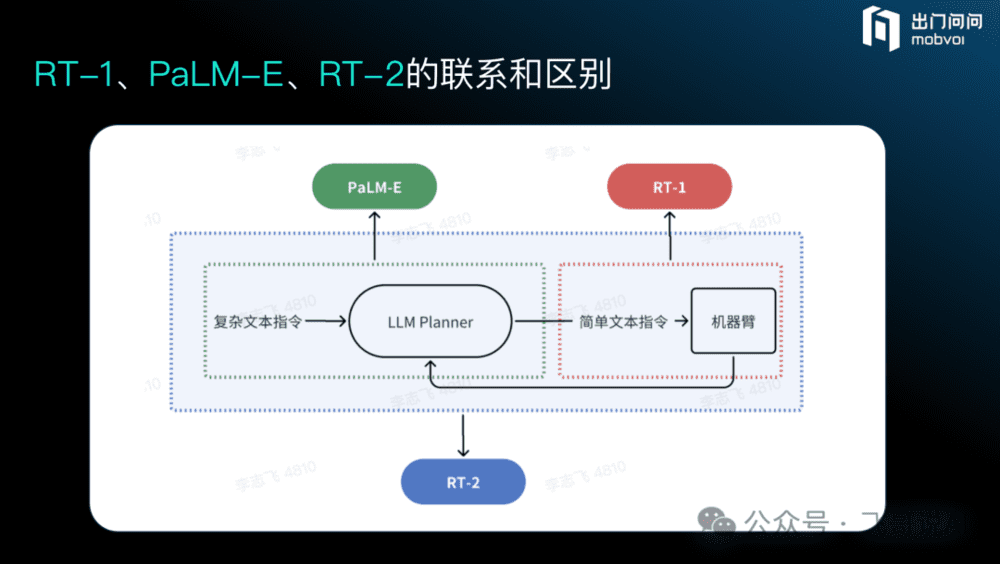
简单来说,RT-1 仅是一个能听懂简单指令的机械臂,完成上面说的第二个步骤,模型中没有思维链,也不具备推理能力。PaLM-E 让机器人有了聪明的大脑,可以将复杂自然语言指令分解为简单指令,完成上面说的第一个步骤,然后再去调用 RT-1执行动作。
所以,PaLM-E所做的只是自然语言理解以及 Planning 部分的工作,并不涉及机器人动作本身,它是一个VLM(Vision-Language Model )模型。
RT-2 则是把以上环节端到端地集成到了一起,它能够用复杂文本指令直接操控机械臂,中间不再需要将其转化成简单指令,通过自然语言就可得到最终的 Action,它是一个VLA(Vision-Language-Action Model)模型。
端到端的好处,是通用、能自动适应环境的各种变化,但问题是决策速度慢,很难做到Figure这种200hz的决策速度,比如RT-2论文里提到的决策频率是1到5hz,具体取决于语言模型的参数规模。

关于RT-1、PaLM-E、RT-2的来世今生、区别和联系可以参见之前关于RT-2的文章:
《从机器人模型 RT-2 看多模态、Agent、3D视频生成以及自动驾驶》。
二、亮点:既能用到大语言模型的常识和COT,又能达到人一般的操控速度
Figure 视频的亮点是它既利用了大语言模型的常识和思维链COT的能力,又实现了快速的底层操控,几乎接近人的速度。
比如在视频中,当人说“我饿了”,Figure思考了2秒~3秒后,小心翼翼地伸手抓住苹果,并迅速给人递过来。
因为Figure基于大语言模型的常识,明白苹果是它面前唯一可以“吃”的事物,在人类没有任何提示和说明的前提下,即可以接近于人类的反应速度,与人自然交互。
另外,也用上了大语言模型的长上下文的理解能力,比如“你能把它们放到那里吗”,谁是“它们”,“那里”是哪里?这些只有大语言模型才有能力精准抓取长上下文里的指代关系。


三、Figure 是否用到了Sora?
最近,OpenAI的Sora红了半边天,而Sora自称是世界的模拟器,所以很多人自然会疑问这个机器人是否用到了Sora。
肯定的是,Figure与Sora一点关系都没有,因为Sora现阶段主要是生成,不是理解,就算未来Sora既能理解也能生成,是否能端到端做到200hz的决策速度也是一个很大的问题。
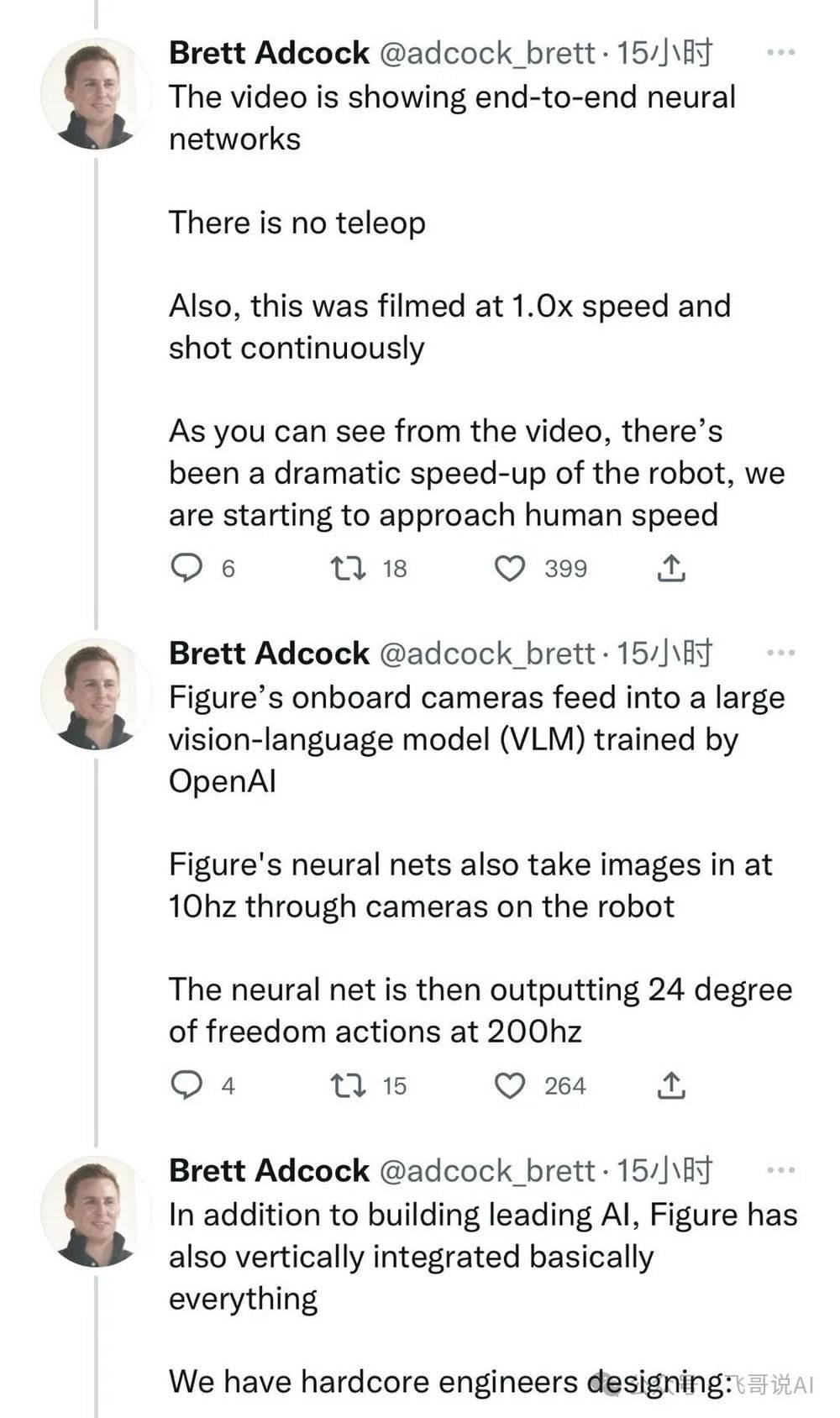
四、Figure 是否用到了远程操控?
有人觉得视频是远程操控(所谓Teleop)录制的,但Figure创始人Brett Adcock强调了视频不是Teleop,录制速度也是1倍原速度,所以视频中能看到回答问题的明显延迟(因为语音识别、大语言模型、TTS是通过pipeline方式连起来的,都需要计算时间)。
五、Figure 是端到端模型吗?
Figure创始人Brett Adcock上面这个Post提到是端到端的神经网络,个人觉得这可能是口误吧。从他们技术负责人的Twitter post里可以看出,至少用了两个神经网络模型,一是OpenAI的GPT4V(类似于Google的PaLM-E);另外一个是机器人操控的模型(类似于RT-1)。
所以Figure不是类似于RT-2的“端到端”模型,而是一个pipeline系统。
六、结语
总结一下,我们可以理解为Figure的机器人模型是:
GPT4V + 操控模型 ~= Google的PaLM-E + RT-1。
再次感叹,OpenAI的“远见卓识”,在机器人与大模型结合的领域,又让隔壁的Google起了大早,赶了晚集。一如既往,OpenAI超越Google的方式不是在技术原理,而是在于产品定义以及宣传方式。比如,与RT-2用一个机械臂演示不一样,他们用了一个真实的人形机器人来演示。
此外,他们通过展示机器人的操控速度和自然度来吸引观众的眼球。这些都比Google那种纯工程师演示的方式倍加有吸引力。作为观者,我们一方面惋惜于Google,同时也乐于再次见证这类军备竞赛的上演,Google加油!
Figure联合创始人兼首席执行官Bred Adcock表示,“我们的目标是训练一个世界模型,以操作十亿单位级别的仿人机器人。”这些机器人,可以消除对不安全和不理想工作的需求,最终让人类拥有更有意义的生活,这也与OpenAI的“超级对齐”愿景不谋而合。
计算机是虚拟世界的通用平台,机器人是物理世界的通用平台。
从特斯拉的Optimus到今天的Figure,未来的模型能力和机器人硬件会如何平衡,从广告噱头到量产应用还有多远?人形机器人百家争鸣的春秋时代已拉开序幕。
本文来自微信公众号:飞哥说AI(ID:FeigeandAI),作者:李志飞