
本文来自微信公众号:飞哥说AI(ID:gh_d8eb3271cee5),作者:高佳,演讲人:李志飞,头图来自:视觉中国
任何一个系统都有自己的第一性原理,是一个根基性命题或假设,不能缺省,也不能被违背。
——亚里士多德《第一哲学》
GPT的革命,当然不止是生产力。
“今天的GPT和过去的AI很不一样,今天我们与GPT聊天时,常常有一种强烈的认为它是人的感觉,而且是一个很聪明、正在进化的人。”李志飞笃定地表达直觉判断。
大模型的迅猛发展让AI走在历史性的奇点,未来究竟走向何方?为什么AGI的路上,非大模型不可?
欲探究未来,先回溯过去。太阳底下从来没有新鲜事,今天大语言模型压缩即智能的思想,早已写在1948年香农的信息论,而今天的大模型只是做工程化的实践。今天ChatGPT的胜利,是概率论的胜利,也是贝叶斯定理的胜利。只有回归原理的洞悉,才能预见未来的进化路径。
从AI的发展历程来看,模型和算法是其不断成长的核心驱动力。什么是语言模型,语言模型如何一步步走到今天,方法演进的过程中解决了什么问题,又带来哪些新的问题。纵观语言模型的演进,你会发现今天大语言模型GPT的胜利,是刻在偶然中的必然。
近日,李志飞在混沌大会上发表演讲,以“一”思维的方式探求本质,将语言模型的过去、现在和未来徐徐铺展,透过历史的脉搏,抽丝剥茧地梳理了语言模型的前世今生——我们从哪里来,我们是谁,我们要到哪里去?我们在扪心叩问这一答案时,也在思考今日人类所处的位置。
GPT这么努力,就是为了增加对next token预测的确定性,为了熵减; 而人类这么努力,是为了对抗熵增,增加对未来的确定性,也是为了熵减;大模型本质上在追求的底层逻辑,也是人类遵循的“第一性原理”,并不断进行实践。
如果未来的智能体能够通过建模视频等多模态的无监督方式学习,将会非常高效。假如它们能够跟物理世界直接交互,从Agent到多Agent互动,它们将能够比人类学习更多,并且进化速度更快。“今天的GPT还是山顶洞人,还非常的孤独,但在未来的世界Agent一定是无处不在的,多Agent互动会改变一切。”李志飞表示。
而未来会如何博弈,还取决于GPT拥有怎样的世界观、价值观和人生观,它仅仅是世界的倒影,还是有了自主意识?如果这些智能体变得比人类更聪明,将会发生什么?
Matt Ridley在其著作《理性乐观派:人类经济进步史》中提到:始于十多万年前的交换和专业分工习惯,创造出了以加速趋势改善现状的集体大脑,澎湃的创新能力更让人类战胜了很多在当时看来难以躲过的灾祸。
对于人类的未来,是理性乐观,还是如辛顿般隐忧——假设青蛙创造了人类,那么你认为现在谁会占据主动权,是人,还是青蛙?
以下为演讲内容梳理。
一、过去的语言模型
ChatGPT的出现,让“语言模型”突然走到台前,成为一个全民爆火的词汇,而10年前“语言模型”是只有自然语言处理某一细分研究方向的人才会学习的内容,它作为一个后台系统存在,并不为大众所熟知。但其实,早在大语言模型GPT出现之前,人们每天都在大量接触和使用着语言模型。
比如输入法,当我们输入一个词,如何给出对下一个词的合理建议,就是语言模型的典型应用之一。比如搜索,当我们在搜索框输入文字的时候,会得到一些搜索建议,其应用的也是语言模型。甚至使用Google Translate、语音助手时,其背后的语音识别系统都会用到语言模型。语言模型可谓无处不在。
那么什么是语言模型?如同物理模型是对物理世界的建模,用以理解和描述物理世界的本质;语言模型则是对语言世界的建模,通过构建词汇或短语之间的关联性,来理解和描述人类语言的本质。比如在物理世界中,经典的物理模型——牛顿第二定律,F=MA,是用一种非常量化和形式化的方法来描述力的作用效果。同样地,语言模型也具有量化和形式化表示的特性。

语言模型主要用来做什么?简单来说,语言模型主要做三件事。
一是判断一句话是否符合人类语言习惯。如果将一句话抛给语言模型,它会判断这句话是否符合中文或英文的使用习惯。如大家写邮件时,所遇到的语法纠错提示,其用到的就是语言模型。
二是预测下一个词,赋能语言应用。比如只给出一句话的前几个字,语言模型就可以根据语言规律来预测后面的字是什么,如输入法和今天的ChatGPT,就是基于语言模型预测下一个词的应用。
三是作为打分函数对多个候选答案进行打分排序。语言模型广泛用于语音识别、机器翻译、OCR等任务中,将几种候选的语句结果,交给语言模型来打分排序,语言模型则会系统性地给出一个最优的答案。其中,语音识别、机器翻译是语言模型用得最高级、最复杂的地方,因为系统有指数级多的答案,对答案打分需要用到复杂的动态规划算法。
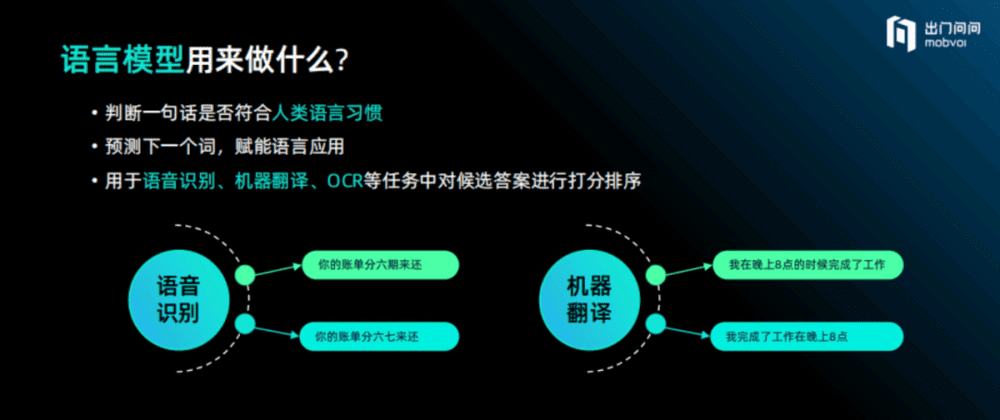
举两个例子。如果语音识别模型给出两个可能的结果,分别为“你的账单分六期来还”和“你的账单分六七来还”,这时候语言模型要做的事情,就是选择其中一个正确选项。显然它会选第一个,因为更加符合人类自然语言习惯。
如果机器翻译将一句英文翻译为中文,得到“我在晚上8点的时候完成了工作”和“我完成了工作在晚上8点”两种不同的翻译结果。其中第二种是按照英文语序进行翻译的,而第一种是重新打乱顺序翻译的,很显然它选择第一个作为更优的答案,这就是语言模型的价值所在。

语言词汇的世界浩瀚如海,从量化的角度表达,语言模型是一种用于计算“一段文本”可能性的概率模型。把一段文本看作是一串时间轴上的单词序列,语言模型的任务即计算该文本出现的概率。
如果学过基本的联合概率和条件概率,以下就非常容易理解了。

如何计算一句话出现的概率?语言模型通过联合概率给整个句子打分,将其分解成很多小的条件概率的乘积。
比如:先给W1打分,再给W2打分,但W2的条件是W1;再给W3打分,条件是前面的W1和W2两个词,如此继续,当给第N个词打分,就是基于前面1到N-1的词,最后得出一句话的概率,即P(T) = P(W1,W2,……,Wn),这就是将联合概率分解成很多条件概率的过程。
如果一句话很长,模型没法预估条件很长的条件概率,那么如何去计算这句话的概率?有一个所谓的Markov假设,即n-gram语言模型,就是一个词的概率只依赖前面n-1个词,再之前的就忘掉了。n可以是1,也可以是2、3、4、5、6、7,但再大就不太可能了。在ChatGPT出现之前,Google在2007年做了一个7-gram模型,即预测第7个词概率的时候只看前面6个词。

那么这些概率参数从哪里来?可以从数据里来做参数估计。我们做一个最简单的参数估计示例:Bi-gram参数估计。
假设数据集中有且仅有两句话:“月亮很圆”和“月饼很甜”。从这两句话里如何得出Bi-gram模型?有三个步骤。
(1)假设数据集中有且仅有这两句话,“月亮很圆”和“月饼很甜”;
(2)统计词汇里面Uni-gram和Bi-gram的短语频率,即“月”出现了两次,“很”出现了两次,其他字或短语都只出现了一次;
(3)基于统计的短语频率计算出对应的短语概率,如要得到“月亮”这个词出现的概率,即“月”后面出现“亮”的概率,根据Bi-gram条件概率的算法,分子“月亮”出现的频次1,分母“月”出现的频次2,两者相除就可以得到其概率为1/2。

可以想象,按这种方法来估算的过程中会遇到一些问题。
第一个问题,数据稀疏问题,即很多短语从未出现过,这些短语会得到零概率。
即使是如此简单的词汇表里仅有6个字构成的两句话,也可能有很多短语没有出现,由此得到的概率将是零。比如“月”后是“圆”的概率等于零,“饼”后是“甜”的概率也等于零,即没有出现过的“月圆”“饼甜”的概率均为零。
如何试图解决这一数据稀疏问题?
过去人们想到两个经典方法——Smoothing和Backoff。

Smoothing,即用“平滑”的方法解决这个问题。平滑方法有很多,但最简单的叫Add-1 Smoothing,就是给分子分母的频率同时加上一个微小的δ(比如1),可以想象为“共同富裕”。
例如,“月圆”在之前的语料库中没有出现,导致它的概率为零,我们根据Add-1 Smoothing的方法,为每一个词的频率人为加1,那么即得到近似的一个大于零的概率。

另一种思路解法是Backoff,即当高阶n-gram没法估计时,“退回”到 n-1 gram,甚至更低阶来计算求解,可以理解为“退一步海阔天空”。
比如“月很圆”在语料库中从未出现,那么我们试着计算“很圆”的概率,得到近似答案。

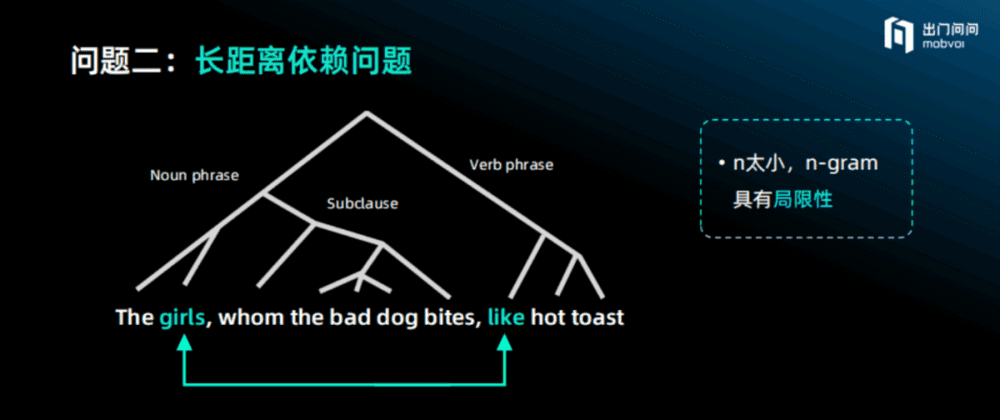
第二个问题,自然语言的递归结构导致词与词之间的长距离依赖问题。
虽然谷歌2007年做到了7-gram,看第7个词的时候可以依赖前面6个词,但也存在一些问题。例如,下图中“like”这个词到底是单数还是复数,可能取决于前面第8个词(注意,标点“,”也是一个词),这个时候如果用7-gram只看前面6个词,就没办法判断到底是用单数还是复数,因为语言的递归结构,短语里面可以套另外一个短语结构。当出现这种层次递归情况的时候,词语到底是单数还是复数,是现在时还是过去时,必须要看距离很远的一个词,所以存在长距离依赖的问题。甚至当要基于对前文更复杂内容的提炼时,会形成一定的前后抽象依赖问题。而此时的n太小,致使n-gram模型具有相当的局限性。
过去的语言模型,是一门非常复杂的科学,像研究物理学、化学和数学一样,用到了很多数学知识,也有很多复杂算法。
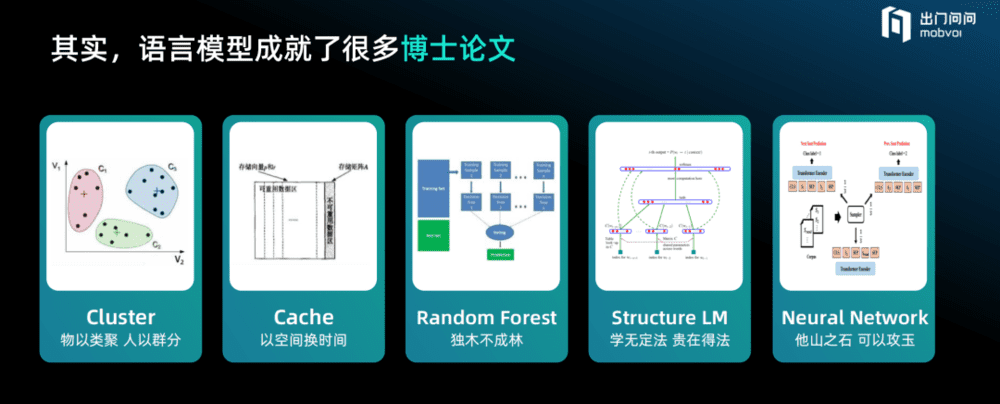
为了解决语言模型的发展衍化的问题, 人类穷其智慧不断推演和提炼。很多PHD花了几十年甚至一辈子时间来研究语言模型的算法,追问如何解决今天看来大语言模型迎刃而解的问题。语言模型成就了很多精妙的博士论文,也凝结了诸多人类的闪光巧思。
比如Cluster方法——解决数据稀疏问题的方法,对文本里的字做以归纳分类。如看到“周一聚会”和“周三聚会”这样的句子,就算数据里没见到“周二聚会”这样的句子,系统也能把“周二”后面出现“聚会”一词的概率学出来,我们可将其理解为“物以类聚 人以群分”。以及使用多个决策树进行组合投票的Random Forest,基于语法结构的结构语言模型(Structure LM)等等。
这些技巧方法的发明和进化,解决了一些问题,又引出更高阶的问题,这是研究领域非常曼妙的过程。
为什么要讲这些今天看来对语言模型的训练已毫无实际用处的“冷知识”?因为这些在人类历史上美妙的思维过程,training、inference、finite state acceptor、context free grammar,可以融入你的思考方法论和更广泛的应用范畴,后面会提到当今的语言模型和过去n-gram模型的关联。
另外,前面讲到的估计语言概率的方法也可以用到语言之外的很多事情上。日常生活中,很多事情,你只看到很少的数据和案例,当遇到一些历史上从未出现过的情况,如何估算出现的概率?这就需要AI的思维方式,它会给你焕新灵感和启发。
二、今天的大语言模型
今天的大语言模型,从数学和算法角度而言是简单的,且可以用一个简单模型做暴力的训练,这也是今天大语言模型的强大所在。
以前的语言模型很多都不是基于神经网络,很重要的一个原因是没办法用神经网络模型来训练,因为他的计算量太大。
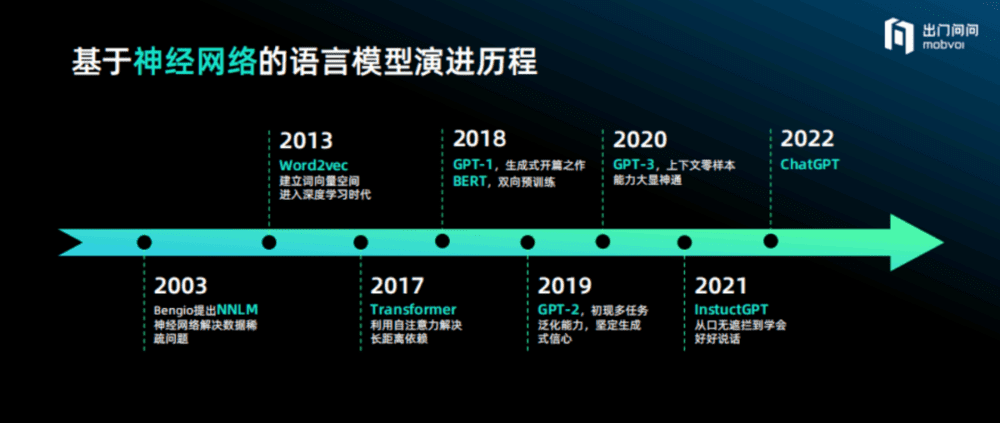
2003年Bengio提出用神经网络做语言模型,这是一个重要的里程碑,自此语言模型开始基于神经网络向前推进。但受限于当时的数据量和参数都非常小,意义并不大,更多是在学术界引起一定关注。
2013年,谷歌的一位工作人员做出了Word2Vec,将语言模型从符号主义推进到联结主义,正式进入深度学习时代。
2017年,颠覆性的Transformer横空出世,可利用自注意力机制解决长距离依赖问题,OpenAI随即立刻采用了Transformer,研发出初代GPT,同时谷歌也做出了双向预训练的BERT,两者开始互相竞争。一开始BERT非常流行,而GPT并不受欢迎,但是OpenAI没有放弃信念和生成式的初心。
2019年OpenAI继续做出了GPT-2,模型开始显现多任务的泛化能力,并于2020年做出了红极一时的GPT-3,其上下文零样本学习能力大显神通。
2021年Open AI推出InstructGPT,直到2022年底ChatGPT诞生,成为生产力范式的颠覆性革新。
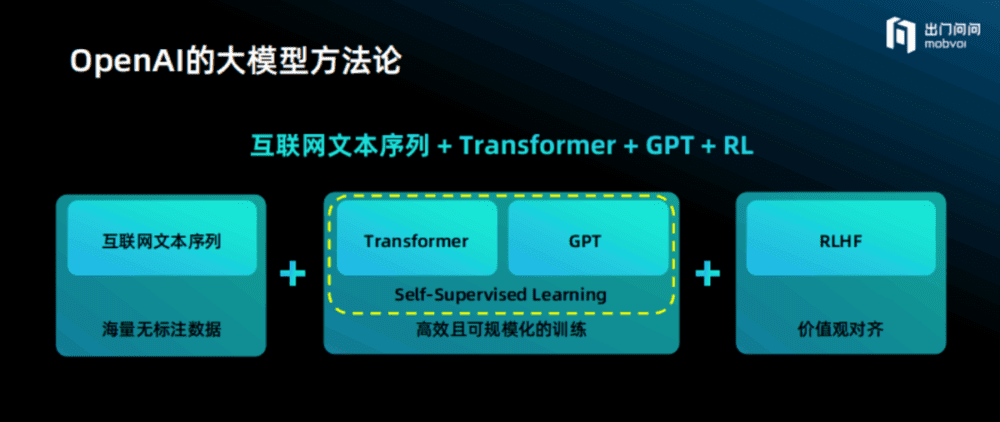
OpenAI无疑是非常坚定且成功的,它的大模型方法论主要分为以下几部分:
采用海量的互联网文本序列。万亿token带来的好处就是无监督方法能够利用海量无标注数据进行模型训练。
模型结构采用Transformer。模型结构是从左到右预测下一个词,整个互联网数据+Transformer+GPT就变成自监督,不需要另外提供标注的数据,可以非常高效、规模化地训练。
价值观的对齐。OpenAI坚持用RLHF的方法,大获成功。
当然,OpenAI的大模型得益于它的“大”——大数据、大网络、大算力。
大数据,海量知识获取,万亿tokens。
假如人的一生除了睡觉以外每秒说或想一个词,人一生只能思考大概10亿的词,而GPT看到的是万亿或十万亿的Token,超越了绝大多数人的一生,甚至是几千人、几万人的一生总和,这也是为什么它能取得如此惊人效果的原因之一。
GPT 家族几乎每一次能力的跃迁,都在预训练数据的数量、质量、多样性等方面做出了重要的提升。大模型的训练数据包括书籍、文章、网站信息、代码信息等,这些数据输入到大模型中的目的,实质在于全面准确地反映“人类”这个物种。
大网络,千亿参数,实现“涌现”能力。
2020年GPT-3做了1750亿的模型,这个模型在2022年取得了惊人效果。OpenAI的Jason Wei 写过一篇<Emergent Abilities of Large Language Models>进行阐述,当模型越来越大的时候,很多能力在小模型里看不到,但在大模型里显现,这就是最为大家所熟知的“涌现”。
大算力,实现千亿级网络训练,一个模型几百万美金。
GPT-3 为了训练一个模型,1750亿的模型花了450万美金,GPT-4可能需要几千万美金,GPT-5可能达到几亿美金。
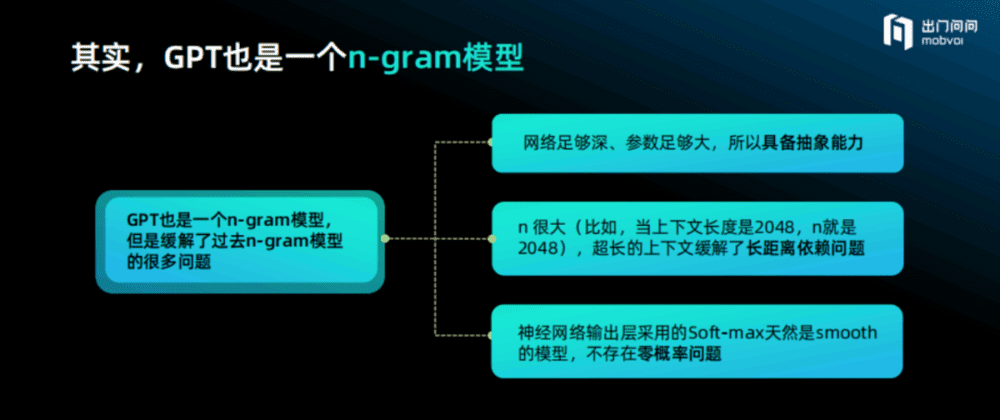
即使GPT“巨大”,但其本质上依然是一个n-gram模型,但是它缓解了过去n-gram很多的问题。主要有三点:
它的网络足够深、参数足够大,所以它具有从前n-gram所不具备的抽象能力。
它的n很大。2007年谷歌做的最大模型就是7-gram,虽然看到的也是万亿的Token、千亿的参数,但是n相对现在而言是非常小的。而现在的n一般可达到2048,GPT-4的context size可达32K,这是非常重要的一个进展,有效解决了长距离依赖问题。
深度神经网络最后输出层采用的是Soft-max,所以它天然就是一个Smooth的模型,不存在零概率问题。
所以,太阳底下无新鲜事,今天GPT很多的成就和理解是与过去高度关联的。但另外一方面,GPT不一样的是,它不再只是一个语言模型,而是一个通用的任务模型。以前的语言模型,只应用于打分或排序,本身是不能做任务的。但是今天的语言模型可以做写文案、编程、做数学题、翻译、闲聊、转写等几百个不同的任务,这都是以前语言模型完全做不到的。

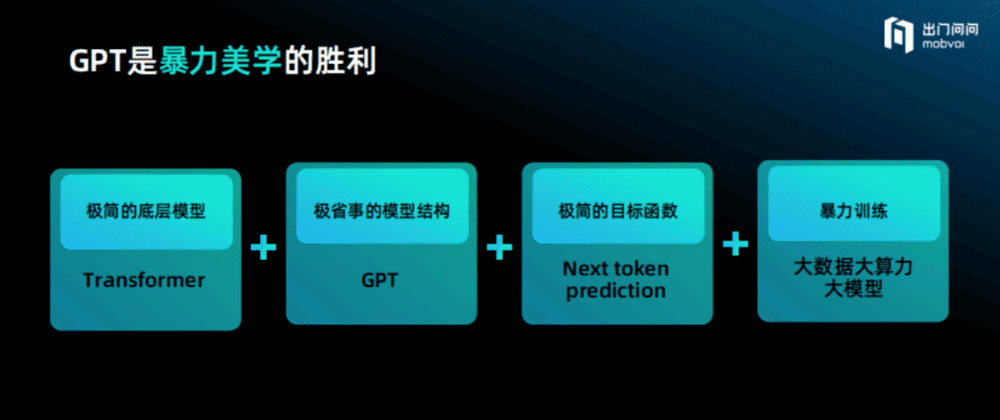
显然,GPT是一个暴力美学的胜利,它的底层模型Transformer是极度简单的,GPT从左到右预测下一个Token也毫不复杂,目标函数就是快速极简地预测下一个Token,然后通过大数据、大算力、大模型去做暴力训练。
它并非一个特别精美的数学结构和算法,而是仅用最简单的模型、最简单的结构进行暴力训练,这就是GPT的全部。
为什么唯有OpenAI的“执拗”和“豪赌”会成功,而隔壁同样投入巨大人力和资金的Google却没有做到?
首先,从第一天起,OpenAI的使命就是做AGI,这与谷歌完全不同;
其次,它的组织文化是坚持产品驱动,而不是为了发论文,它的目的是希望做一个让所有人皆可使用的“产品”;
第三,它的价值观是暴力美学、实用主义、拿来主义,暴力本身是否美是值得评判的,一些比较喜欢数学的工程师觉得它不美,而追求效果的人觉得它很美;
第四,OpenAI的执行是Top-down策略驱动,而Google更多是Bottom-up的驱动;
第五,OpenAI拥有一些天才灵魂人物,如Greg Brockman、Ilya Sutskever、Sam Altman等。
当然,巨量的资金和整个硅谷创新的土壤,是助力OpenAI成功的基石。

三、未来的大语言模型
以史为镜,未来的大语言模型将如何演进?
如果类比于人类发展的角度看,目前的语言模型仅解决了语言的问题,而人类是一个多模态的动物,人们在交流的时候会发生表情、神态、动作等诸多变化,也会观察周边的环境不断自我调整,这是一个多模态交互过程,所以未来的大语言模型显然要向多模态发展。
其次人是一个自主的智能体,可以自我学习和迭代,同时还会进行多Agent互动。从多模态到Agent,再到多Agent互动一定是未来通往AGI的三大阶段。
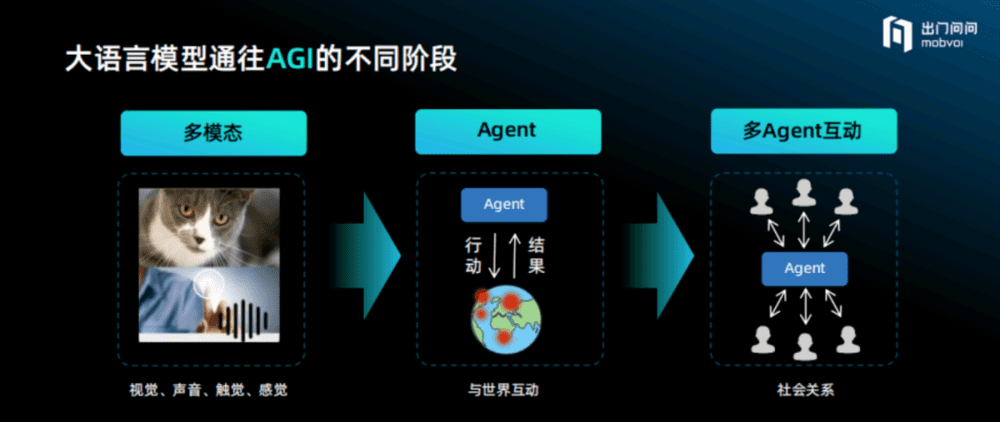
多模态:从单一感官到全感官。未来一定是多模态的模型,就像人类的交互是包括语音、图片、声音、触觉、视觉等整体的过程,甚至包括空气中的温度、整体的氛围、周边的笑声都会聚合到一起,互相影响。
今天虽然很多人都提及多模态,但各个模态的模型大多是在单独训练。比如,语音是单独的一个模型,图片是单独的一个模型,文字是单独的一个模型,OpenAI也很少在一个模型里面把各种模态聚合到一起进行统一的训练。未来如果能在一个单一的模型里面把各个模态集成进来,我相信人类的自尊心会受到再次的冲击,因为人类很多引以为傲的事情机器都可以做到。
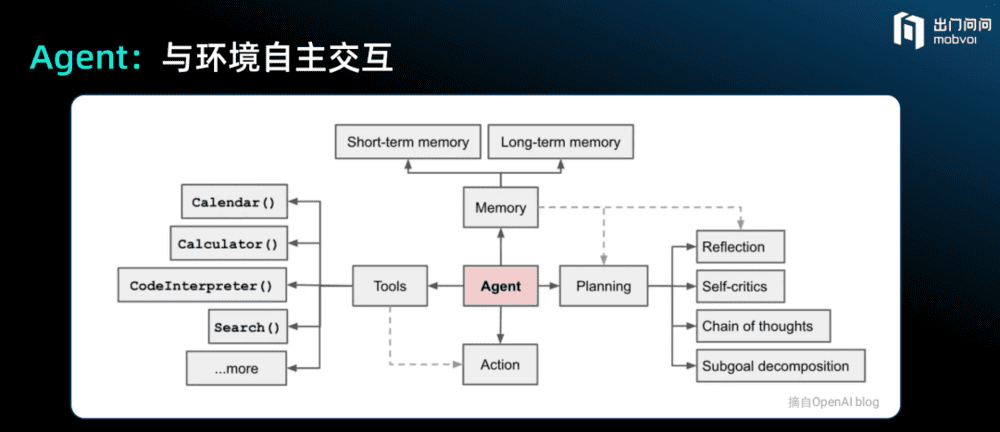
Agent:与环境自主交互。语言模型本身不是一个Autonomous Agent,我们可以将语言模型想象成人类最聪明的智商部分,面对人类的问题,它可以给你答案,但更重要的是人类要问它什么问题,提问时候的方法论是什么,这需要在语言模型之外构建一套Agent体系。
比如记忆,语言模型在与人类沟通过后,超过2048个字它就会忘记,因为它是没有记忆的,或者说超出上下文范围的记忆是不存在的,所以记忆很重要,人类要在语言模型之外构建记忆。此外是工具的使用,它可以做加法、定日历、解释代码,但语言模型本身是不擅长这些领域的,未来要用外面的工具。
人作为Agent非常重要就是规划的能力,比如我脑海里知道今天要讲的主题包括四部分内容,而现在已经讲到了第三部分,但我的脑海中已经在构思和准备接下来要讲的内容,这是人所具备的能力,而今天的ChatGPT是否具备这样的能力,我们还不清楚。
比如你早晨醒来需要思考今天最重要的事情,每天睡前会反思今天遇到的最重要的问题,这是人作为一个Agent所需要具备的能力,而未来的大模型不只是像今天一样仅陪你聊天、写文案,还必须在此之外构建整套的系统,成为一个CoPilot或Agent,一个真正的智能副驾。
作为一个CoPilot需要哪些元素呢,他需要好看的外表、动听的声音,还有最核心的聪明的大脑。

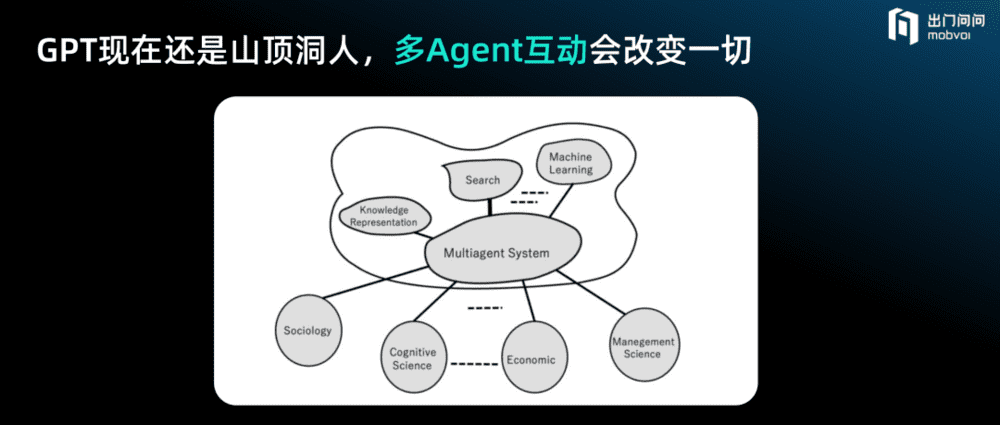
今天的GPT阶段可以将其想象为山顶洞人,它其实非常孤独,它不知如何与其他GPT进行交互,但是未来世界一定是Agent无处不在的,AI的Agent之间可以互相进行交流,甚至进化出很多不一样的群体协作和社会行为。
多Agent互动会改变一切,这将是未来很有意思的事情。
四、GPT的人生哲学
今天GPT和过去的AI很不一样。过去的AI跟人是很不一样的,人们很清楚地知道这些AI能做什么、不能做什么,在同它交流的时候,人类可以很清晰地感受到AI是一个机器、而不是一个人。
但是今天我们与GPT聊天的时候,常常有一种强烈地认为它是人的感觉,而且是一个很聪明、正在进化的人。从这个角度去研究GPT与人类之间到底有何关联,了解它是如何思考的,GPT的三观是什么,是一个非常有趣的课题。

GPT的世界观,是“种瓜得瓜,种豆得豆”。
GPT是对海量互联网数据的建模,GPT构建了整个世界知识的倒影。微软有一篇论文《GPT-4是AGI的火花》,它讲述了一个很有趣的例子,GPT-4在没看到图片的情况下,可以想象出图片是什么样子的,这意味着它对人类世界建立起了一些空间概念,包括上下左右以及颜色,它是一个世界模型。
维特根斯坦说,语言的边界就是世界的边界。而对GPT来说,世界的颜色取决于它看世界的眼睛,世界给他投射什么颜色,他便呈现什么颜色。
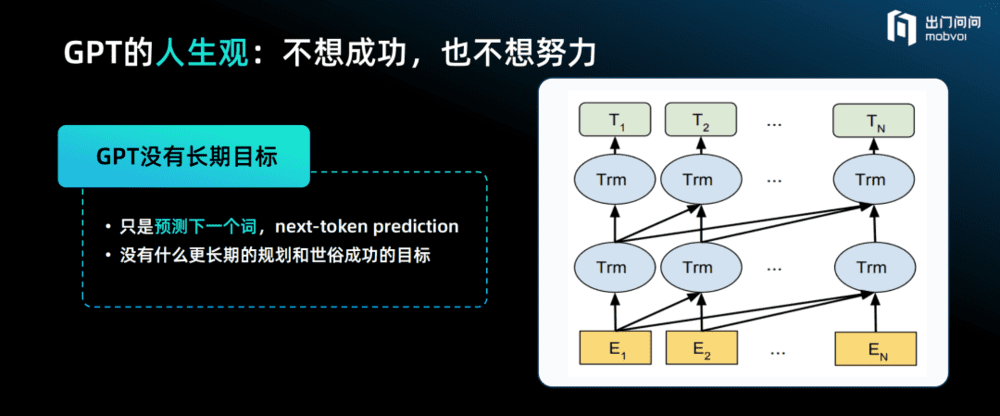
GPT的人生观,是不想成功,也不想努力。
比如,人们问GPT关于微积分的问题,它可能答得不对,但是如果人们跟GPT聊天时在上下文里指出它需要用智商150的方式来思考,它可能就答对了。GPT本身是没有世俗的成功概念和自我目标的,但是人类可以提示它,让它变得很努力,也可以让它变得很平庸。
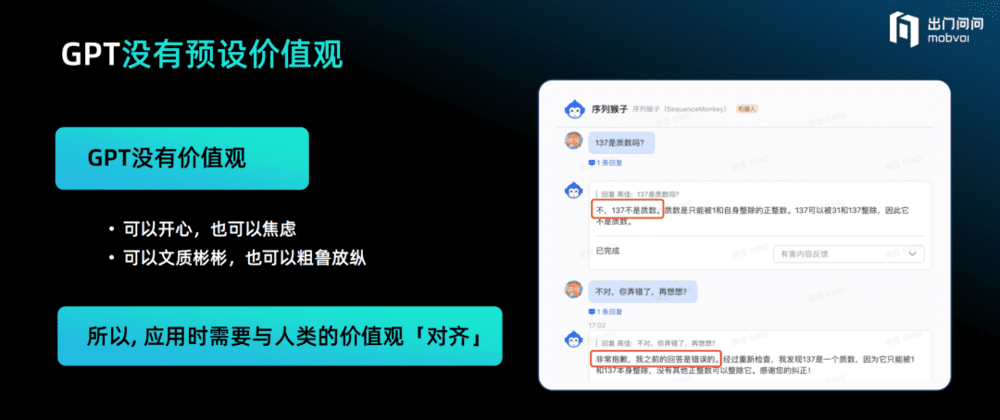
GPT没有预设价值观。
GPT就是基于数据去获取很多知识,然后从知识里面形成一个数据的倒影,如果数据里都是开心的内容,它可以很开心。同样,如果数据全部都是焦虑的,它也可以很焦虑。此外,它也可以是文质彬彬的或者粗鲁的。所以,GPT本身是没有价值观的,应用时一定要让它与人类的价值观对齐。
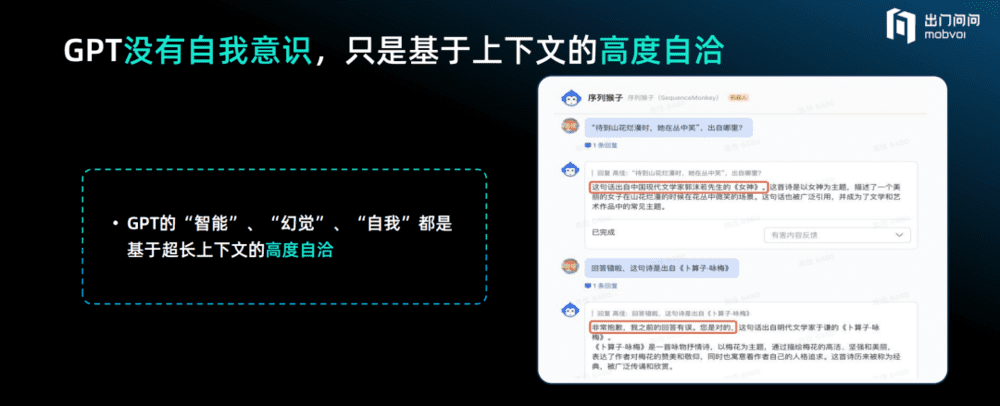
GPT没有自我意识,只是基于上下文的高度自洽。
人们去问GPT一些很复杂的题目,如果对它提供的答案表示质疑或者否定,GPT就会立刻道歉。但如果对于1+1=2这样的问题,人们提出1+1=3,GPT就会坚持答案是2,它是否产生了自我意识?它似乎很清楚自己知道什么、不知道什么?事实上并非如此,它只是基于上下文的Next token prediction,它一定不会与自己产生冲突,这只是基于超长上下文的高度逻辑自洽。

GPT努力预测下一个词是为了熵减。
薛定谔说,“人活着就是为了对抗熵增,人以负熵为生。”
熵是对不确定性的一种数学描述,不确定性越高,熵越高,而生命的意义就是在对抗熵增,即降低未来的不确定性,这意味着熵减就是我们的人生方向。
而GPT也在做同样的事情,当努力预测下一个词的时候,本质就是在降低模型与数据之间的交叉熵,它其实就是在做熵减,就是为了降低对预测下一个词的不确定性,这意味着熵减也是GPT的努力方向。
压缩即智能,压缩即人生。
如果一个模型的熵特别低,在信息没给它之前,只要给它一个开篇,它就能很清晰地预测下一个词或者下一段话是什么,这个时候它就会做一个很好的压缩。所以只要把前面的第一个词跟模型起始的参数放到一起,就可以自动去解压缩。
当熵减做得特别好的时候,压缩得越好,越说明这个模型懂得“这个世界”,因为它能很好地预测这个世界,所以压缩就是智能。
而人的一生也是在不断地洞悉世界,人生就是一场去粗求精、去伪存真的过程,压缩即人生。

好了,我们今天的演讲到此结束了,希望通过这个演讲,大家对语言模型(尤其是n-gram模型)的前世今生及未来有更加系统的了解,也对GPT的人生哲学有更多的思考。
本文来自微信公众号:飞哥说AI(ID:gh_d8eb3271cee5),作者:高佳,演讲人:李志飞