
类似于ChatGPT引起的关于“AI是否有意识”的讨论,OpenAI的新模型Sora让更多人知道了“世界模型”的概念。不同的是,这一次,AI圈内的头部科学家、研究者都参与进来,掀起了一场“Sora是不是世界模型”的大争议。
争议来自于Sora的技术报告,OpenAI在报告中把Sora定义为可以生成视频的世界模型(World Simulators),并认为Sora的技术是打造通用世界模型的一种有前景的方法。

由Sora生成
关于世界模型并没有一个标准的定义,但可以非常简单地理解它。一个第一次开车的成年人在过弯道的时候会自然地“知道”提前减速;儿童只需要学会一小部分(母语)语言,就掌握了几乎这门语言的全部;动物不会物理学,但会下意识地躲避高处滚落的石块。AI科学家认为,人和动物会潜移默化地掌握世界的运作规律,从而可以“预知”接下来发生的事情并采取行动。世界模型的研究就是让AI学习这种能力。
Sora可以生成逼真的视频,看起来视频当中包含一个完整的3D世界建模。它支持在保持画面内容一致的前提下切换镜头,甚至能够按照时间顺序往前或者往后生成新的视频内容。很多人认为,Sora学会了“预知”事物发展的能力,这刚好是世界模型研究追求的目的。
然而,一直在研究世界模型的AI科学家、图灵奖获得者杨立昆(Yann LeCun)则认为,Sora的生成式技术与世界模型的因果预测完全不同,Sora不仅成本高昂,而且对于世界模型完全没有意义。
今天的人工智能拥有人类无法比拟的能力,但在前沿的科学家那里却很难称得上是“真正的智能”。这样的落差是如何发生的?通往“智能”的世界模型真的重要吗?
一、“白痴天才”
在以ChatGPT为代表的生成式AI浪潮出现之前,AI领域经历了一轮深度学习革命。这个过程中,卷积神经网络CNN大放异彩,引领机器视觉技术走向成熟。今天的手机、电脑以及各种互联网产品当中的图像识别功能,几乎都是CNN作为驱动。
杨立昆在20世纪80年代发明了CNN,它模拟了位于人眼的视觉神经和位于大脑的视皮层神经之间的工作过程,能够识别图片当中的视觉特征,在当时被用来识别手写字体。
CNN真正成为主流是在2010年前后。GPU并行计算能力提升,图像训练数据库ImageNet建立,以及强化学习算法等技术应用,种种条件成熟,使得CNN可以通过深度学习训练来提升图像识别能力,识别准确率高达98%。

特别是在2016年,AlphaGo在围棋比赛中技惊四座,一度让CNN大红大紫。几乎在同期,CNN催生了互联网科技公司的产品更新,比如搜索引擎有了以图搜图功能,自动驾驶汽车可以“看见”行人,社交媒体平台可以自动过滤不符合规范的图片,并且能够在用户上传的照片中圈出好友的名字,等等。
今天,CNN支持的计算机视觉能够快速且准确地识别数以百万计的人脸、汽车的车牌和型号,以人类无法做到的方式分辨动植物的品种。搭载AI识别功能的互联网产品给科技公司带来了超额的收入。然而,这样的识别能力却在一开始就被证明是不够智能、甚至是脆弱的。
2015年的一篇论文揭示了深度神经网络容易被“骗”的特点。实验发现,对于一张被AI成功识别的图片,如果仅改变它一处细微的细节,识别效果就会天差地别。这一发现强调了AI虽然擅长识别图像中的物体,但并没有像人一样读懂了图片的内容,而仅仅是提取了图片中像素排列的数学特征。
这样的特点限制了计算机视觉的应用前景,自动驾驶就是典型的例子。CNN被广泛应用到自动驾驶中,参与图像处理和目标识别任务,自动驾驶公司投入了巨量资源给车辆行驶过程中记录的数据做标记,从而训练深度神经网络。然而,长尾问题一直在阻碍自动驾驶技术的突破。具体而言,对于没有在训练数据中出现过的物体,视觉算法通常难以识别,而车辆行驶过程中出现无法识别的可能性会一直存在。
计算机科学家梅拉妮·米歇尔(Melanie Mitchell)把打败了世界顶尖棋手的AlphaGo称为“白痴天才”。即使AlphaGo拥有无与伦比的围棋技术,但它“不具备任何思考、推理和规划的能力”,同时跟其它CNN神经网络一样,“它所学到的能力没有一项是通用的,也没有一项可以被迁移到任何其他任务上”。甚至只要改变棋盘的形状或者大小,AlphaGo的能力就会化为乌有。
不只是CNN,基于深度学习训练的神经网络几乎都存在类似的瓶颈,能力无法泛化、没有理解力、容易被“欺骗”等等。苇草智酷创始合伙人段永朝认为,智能机器目前所能做的,还只是“最快的猜测”,或者说“以快取胜”,但与真正的人工智能之间依然有巨大的鸿沟。
二、知识 VS 常识
多年以来,前沿的AI研究一直致力于突破深度神经网络的瓶颈,让人工智能学会“理解”,其中的关键被认为是人所具有的世界知识。不同于书面上的知识,这种更靠近直觉的知识组成了人的常识,通过掌握常识,AI能够根据当下的情况预测接下来可能会发生的事情。
最近几年,很多AI科学家走出实验室进入商业公司,借助工程化的能力继续投入研究。在这样的时刻,ChatGPT带着生成式技术横空出世,凭借大规模的数据训练和算力投入,实现了能力“涌现”。一夜之间,AI似乎掌握了知识,并拥有了理解力。Sora发布不久之后,OpenAI首席执行官Sam Altman发布推文称“Scaling Laws是由上帝决定的”,强调人工智能能力指数级增长的关键是“规模”,且这种增长是一种不可阻挡的力量。
普遍的看法是,生成式技术打造的大语言模型核心是概率模型,通过一个前值来预测与前值最为相关的一个后值,这一能力的前提是模型掌握了海量的数据。计算机科学家斯蒂芬·沃尔夫勒姆(Stephen Wolfram)在《这就是ChatGPT》一书中直白地介绍了ChatGPT的原理:
首先从互联网、书籍等获取人类创造的海量文本样本,然后训练一个神经网络来生成“与之类似”的文本……值得注意和出乎意料的是,这个过程可以成功地产生与互联网、书籍中的内容“相似”的文本…ChatGPT“仅仅”是从其积累的“传统智慧的统计数据”中提取了一些“连贯的文本线索”。但是,结果的类人程度已经足够令人惊讶了。
学习了大量文本知识的生成式AI能是不是通往“真正的人工智能”的道路?发明了CNN的杨立昆认为,生成式技术的过程不可能产生真正的智能。他表示,大语言模型拥有从书面文本中提取的大量背景知识,但缺少人类所拥有的常识。常识是我们与物理世界互动的结果,并没有在任何文本中体现出来。大语言模型对潜在的现实没有直接的经验,因此展示的常识性知识非常浅薄,在应用中可能与现实脱节。
可以通过这样一个例子理解杨立昆的看法:大语言模型能够根据足球的材质、颜色等物理信息,得出足球被踢飞后的运行轨迹,这个推理过程不需要考虑物理力学的参数,而是基于训练数据中的概率。通过规模化训练,大模型在语言交流、图像和视频生成方面达到了出人意料的效果,但无法应用于解决基于因果的现实问题。这也是关于“Sora是不是世界模型”争论的焦点。
杨立昆认为,实现真正的智能突破不是靠规模,而是让AI在世界模型中学习常识。在论文《A Path Towards Autonomous Machine Intelligence Version》中,杨立昆提出了有关世界模型架构的思路,与生成式架构通过前值预测后值不同,这一思路把重点放在预测前值与后值之间的抽象关系上。
论文中提到,人或者动物大脑中似乎运行着一种对世界的模拟,称之为世界模型,这个模型指导人和动物对周围发生的事情做出良性预测。杨立昆曾举例表示,婴儿在出生后的最初几个月通过观察世界来学习基础知识,比如看到一个物体掉落,就几乎了解了重力。这种预测接下来会发生什么的能力来自于常识,杨立昆认为这就是智能的本质。
根据论文中的思路,杨立昆提出了联合嵌入预测架构(JEPA),并帮助Meta发布了I-JEPA和V-JEPA两个大模型,两个模型分别展示了在图像和视频方面的预测能力。Meta在训练V-JEPA模型的过程中屏蔽了视频的大部分内容,模型仅显示一小部分上下文。他们发现,通过屏蔽视频的部分内容,可以迫使模型学习并加深对场景的理解。
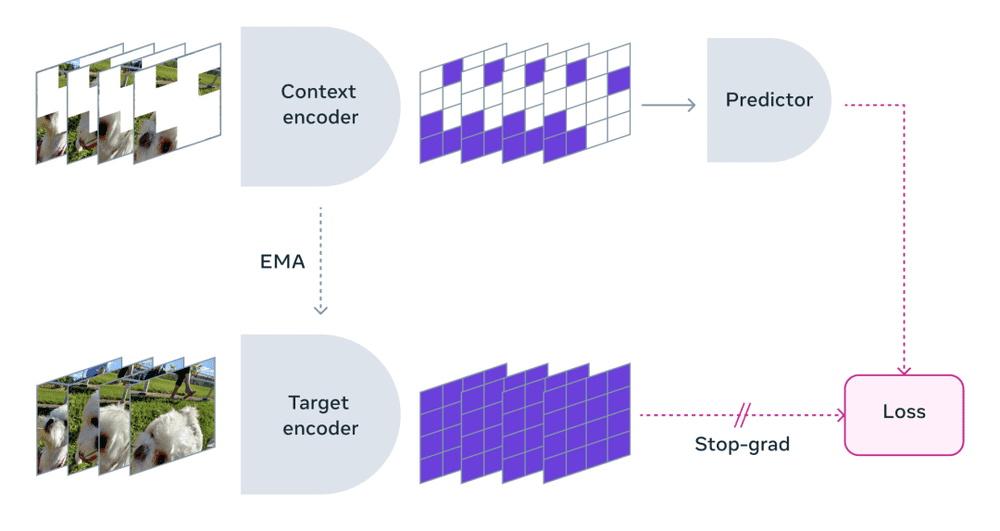
整个过程就像老师把问题和答案给到学生,让学生还原推导出答案的步骤。V-JEPA可以预测短时间内画面前后的抽象变化,比如给定一个厨房案板的画面,它可以“还原”制作三明治的过程。
现阶段,V-JEPA更像是一种技术展示,并且由于仅关注学习抽象关系,它会选择性地忽视不相关的信息,那么三明治的外观就难以辨认。在这一点上,Sora生成的画面则细节饱满。不过,业内人士在评论V-JEPA时表示,相比于Sora,V-JEPA更符合纯粹的人工智能研究。
在2月14日举行的迪拜世界政府峰会上,Sam Altman融资7万亿美元的计划成为记者提问的热点。出席峰会的杨立昆却犀利地表示,现在的大语言模型是新一轮的炒作(Al Hype),跟过去五年一次的炒作一样,目的都是为了创业公司融资。他认为,实现AGI的路径肯定不是AIGC路线,而是需要新的架构,需要至少20年的时间。
然而,关于“纯粹的人工智能研究”这一评论,有回复认为,即使OpenAI的路线是错误的,也与它将实现的商业价值无关。就像杨立昆发明的CNN神经网络,即使所有人都知道有很大缺陷,但仍然改变了我们的生活。
本文来自微信公众号:电厂(ID:wonder-capsule),作者:肖余林