
继 OpenAI 的 Sora 连续一周霸屏后,昨晚,生成式 AI 顶级技术公司 Stability AI 也放了一个大招 ——Stable Diffusion 3。该公司表示,这是他们最强大的文生图模型。

与之前的版本相比,Stable Diffusion 3 生成的图在质量上实现了很大改进,支持多主题提示,文字书写效果也更好了。以下是一些官方示例:
提示:史诗般的动漫作品,一位巫师在夜晚的山顶上向漆黑的天空施放宇宙咒语,咒语上写着 "Stable Diffusion 3",由五彩缤纷的能量组成(Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy)

提示:电影照片,教室的桌子上放着一个红苹果,黑板上用粉笔写着 "go big or go home" 的字样(cinematic photo of a red apple on a table in a classroom, on the blackboard are the words "go big or go home" written in chalk)

提示:一幅画,画中宇航员骑着一只穿着蓬蓬裙的猪,撑着一把粉色的伞,猪旁边的地上有一只戴着高帽的知更鸟,角落里有“stable diffusion”的字样(a painting of an astronaut riding a pig wearing a tutu holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, in the corner are the words "stable diffusion")

提示:黑色背景上变色龙的摄影棚特写(studio photograph closeup of a chameleon over a black background)

此外,Stability AI 媒体主管也晒出了一些生成效果:
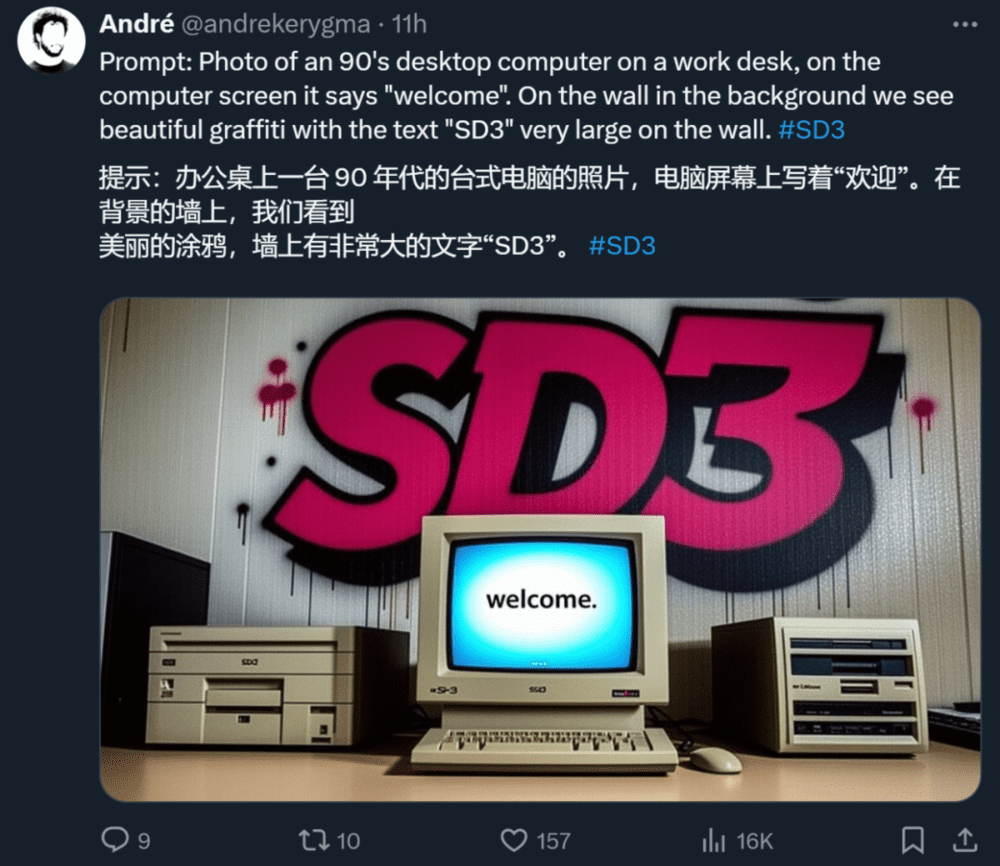
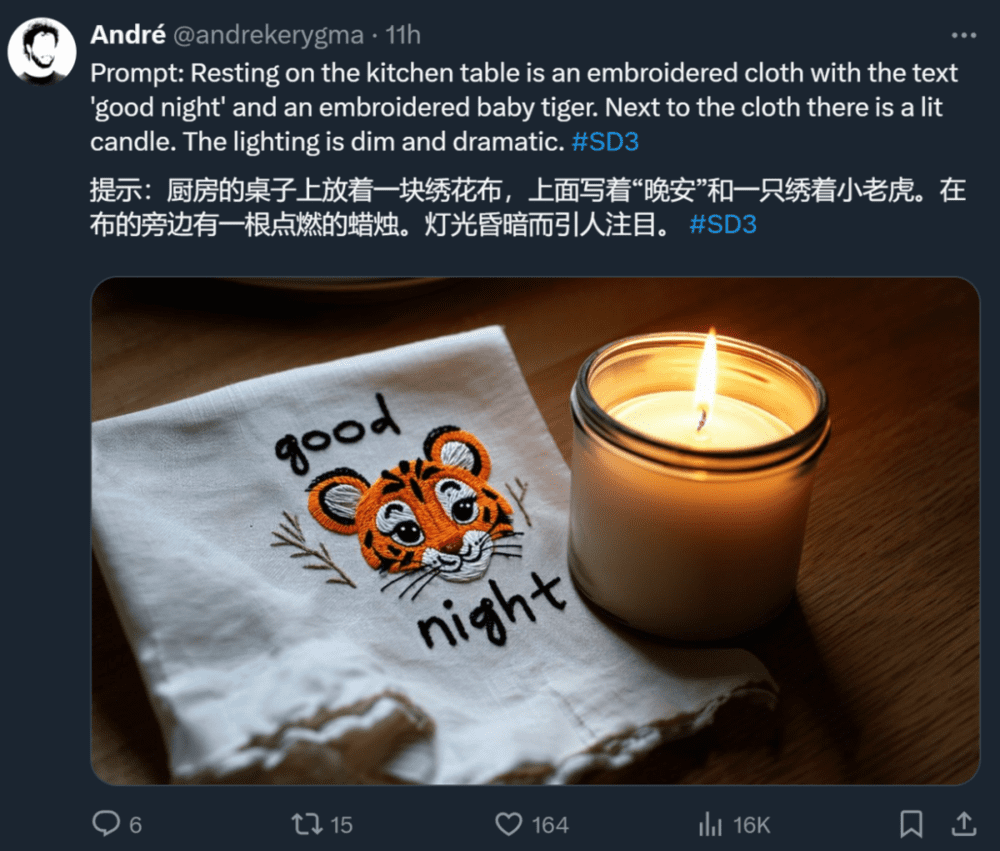
Stability AI 表示,Stable Diffusion 3 是一个模型系列,参数量从 800M 到 8B 不等。这个参数量意味着,它可以在很多便携式设备上直接跑,大大降低了 AI 大模型的使用门槛。
此外,Stability AI 还透露,他们和 Sora 一样,在新模型中采用了 diffusion transformer 架构,并在博客中链接了 William (Bill) Peebles 和谢赛宁合著的 DiT 论文。这篇论文目前的被引量是 201,今年有望大幅增长。
不过,现在,Stable Diffusion 3 还没有全面开放,权重也没有公布。团队提到,他们正在采取一些安全措施,防止不法分子滥用。
该公司首席执行官 Emad Mostaque 在 X 平台的帖子中提到,在得到反馈并进行改进后,他们会把该模型开源。
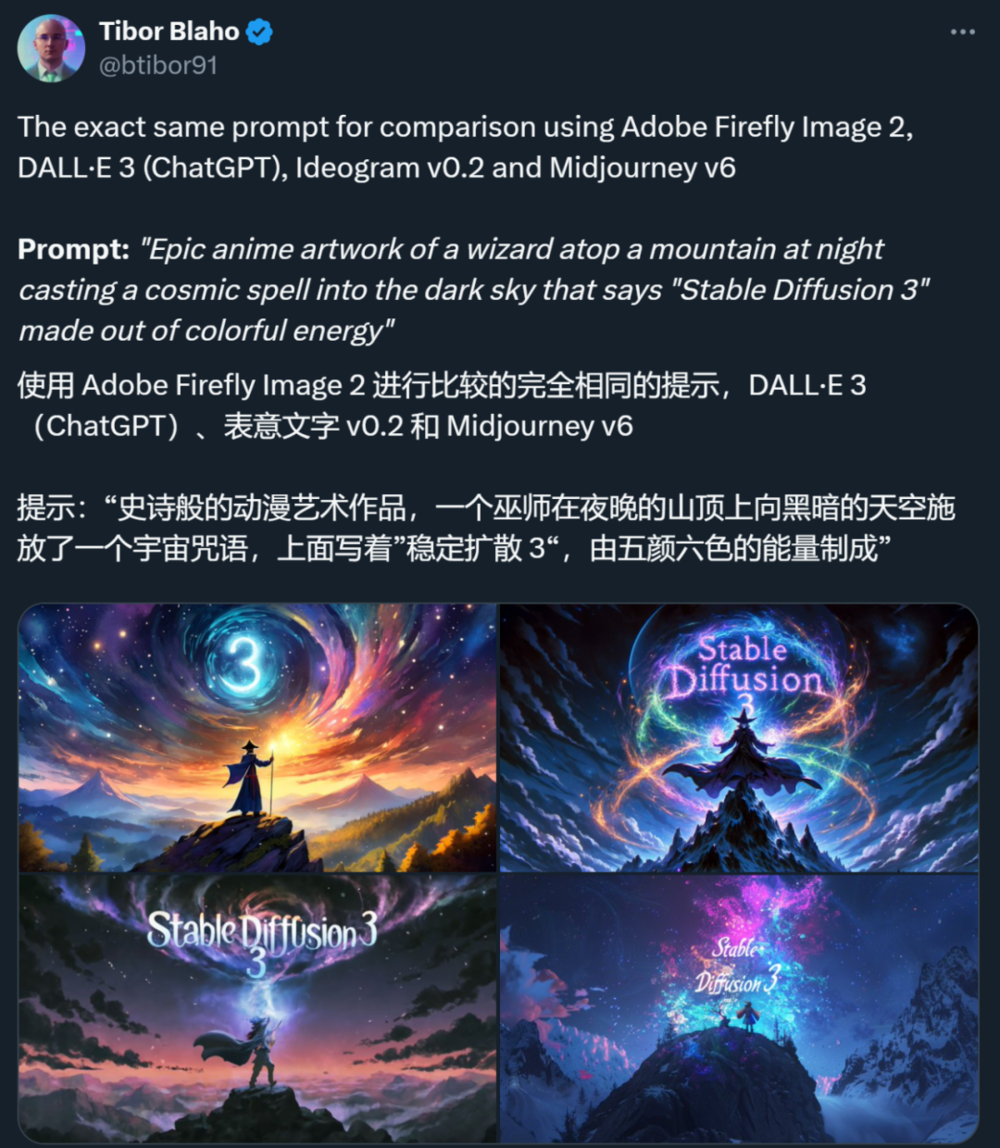
很多人可能会好奇,这个 Stable Diffusion 3 和 DALL・E 3、Midjourney 比效果如何?有些人做了测试,看起来似乎没有拉开明显差距。不过,Stable Diffusion 3 是开源领域的希望。
值得注意的是,在 Stable Diffusion 3 发布的同一时间,外媒还传出了 Stability AI 旗下图像生成应用公司 Clipdrop 被收购的消息。总部位于巴黎的 Clipdrop 成立于 2020 年 7 月,使用开源 AI 模型允许用户生成和编辑照片。在 2023 年 3 月以未披露的金额出售给 Stability AI 之前,它已从 Air Street Capital 筹集了种子投资。当时,Clipdrop 表示它拥有超过 1500 万用户。但仅仅一年之后,Stability AI 就将它卖给了美国写作助理初创公司 Jasper。
有人评价说,Stable Diffusion 3 的发布就是在掩盖这个消息。和很多 AI 创业公司一样,Stability AI 面临的困境在于其以惊人的速度烧钱,但却没有明确的盈利途径。去年年底,该公司还传出了 CEO 可能被投资者赶下台的消息,公司本身可能也在寻求卖身。在这样的背景下,Stability AI 迫切地需要提振投资者信心。

路透社评价说,这笔交易标志着 Stability AI 战略的逆转。Emad Mostaque 在一份电子邮件声明中表示,这笔交易将使该公司能够继续专注于开发“尖端的开放模型”。在 Stable Diffusion 3 的相关博客中,该公司也强调,“我们对确保生成式人工智能开放、安全和普遍可及的承诺仍然坚定不移。”目前看来,Stability AI 的前途仍不明朗。
Stable Diffusion 3 背后的技术:Diffusion Transformer+Flow Matching
在博客中,Stability AI 公布了打造 Stable Diffusion 3 的两项关键技术:Diffusion Transformer 和 Flow Matching。
Diffusion Transformer
Stable Diffusion 3 使用了类似于 OpenAI Sora 的 Diffusion Transformer 框架,而此前几代 Stable Diffusion 模型仅依赖于扩散架构。
Diffusion Transformer 是 Sora 研发负责人之一 Bill Peebles 与纽约大学助理教授谢赛宁最初在 2022 年底发布的研究,2023 年 3 月更新第二版。
论文探究了扩散模型中架构选择的意义,研究表明 U-Net 归纳偏置对扩散模型的性能不是至关重要的,并且可以很容易地用标准设计(如 Transformer)取代。

论文链接:https://arxiv.org/pdf/2212.09748.pdf
具体来说,论文提出了一种基于 Transformer 架构的新型扩散模型 DiT,并训练了潜在扩散模型,用对潜在 patch 进行操作的 Transformer 替换常用的 U-Net 主干网络。他们通过以 Gflops 衡量的前向传递复杂度来分析扩散 Transformer(DiT)的可扩展性,各个型号的 DiT 都取得了不错的效果。
我们都知道,扩散模型的成功可以归功于它们的可扩展性、训练的稳定性和生成采样的多样性。在扩散模型的范围内,所使用的骨干架构存在很大差异,包括基于 CNN 的、基于 Transformer 的、CNN-Transformer 混合,甚至是状态空间模型。
用于扩展这些模型以支持高分辨率图像合成的方法也各不相同,现有方法或是增加了训练的复杂性,或是需要额外的模型,或是牺牲了质量。潜在扩散是实现高分辨率图像合成的主要方法,但在实践中无法表现精细细节,影响了采样质量,限制了其在图像编辑等应用中的实用性。其他高分辨率图像合成方法还有级联超分辨率、多尺度损失、增加多分辨率的输入和输出,或利用自调节和适应全新的架构方案。
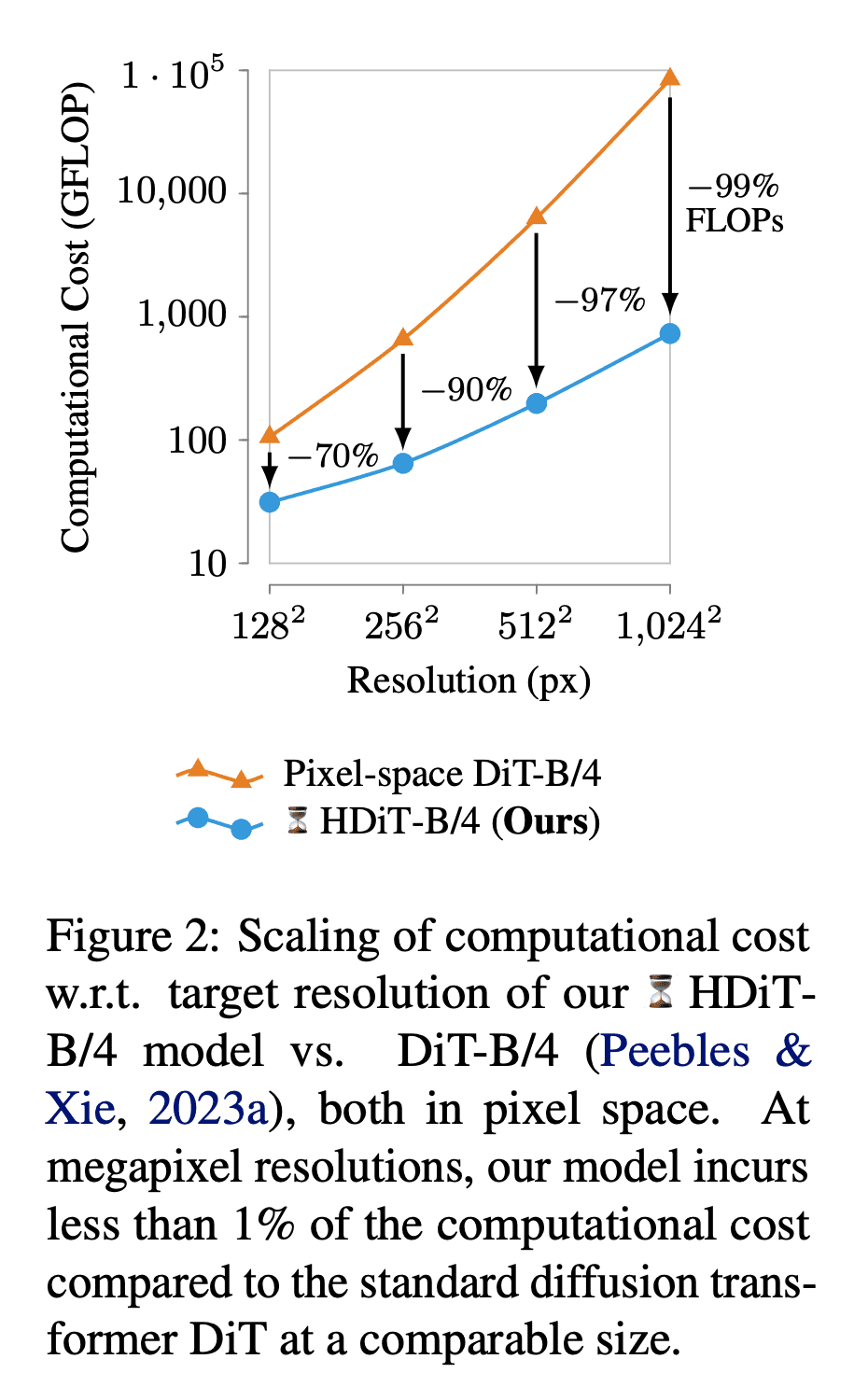
基于 DiT 的启发,Stability AI 进一步提出了 Hourglass Diffusion Transformer (HDiT)。这是一种随像素数量扩展的图像生成模型,支持直接在像素空间进行高分辨率(如 1024 × 1024)训练。
这项工作通过改进骨干网络解决了高分辨率合成问题。Transformer 架构可以扩展到数十亿个参数,HDiT 在此基础上,弥补了卷积 U-Net 的效率和 Transformer 的可扩展性之间的差距,无需使用典型的高分辨率训练技术即可成功进行训练。

论文链接:https://arxiv.org/pdf/2401.11605.pdf
研究者引入了一种“pure transformer”架构,获得了一种能够在标准扩散设置中生成百万像素级高质量图像的骨干结构。即使在 128 × 128 等低空间分辨率下,这种架构也比 DiT 等常见 Diffusion Transformer 骨干网络(图 2)的效率高得多,在生成质量上也具有竞争力。另一方面,与卷积 U-Nets 相比,HDiT 在像素空间高分辨率图像合成的计算复杂度方面同样具备竞争力。
Flow Matching
使用 Flow Matching 技术的意义则在于提升采样效率。
深度生成模型能够对未知数据分布进行估计和采样。然而,对简单扩散过程的限制导致采样概率路径的空间相当有限,从而导致训练时间很长,需要采用专门的方法进行高效采样。在这项工作中,研究者探讨了如何建立连续标准化流程的通用确定性框架。
这项研究为基于连续归一化流(CNF)的生成建模引入了一种新范式,实现了以前所未有的规模训练 CNF。

论文链接:https://arxiv.org/pdf/2210.02747.pdf
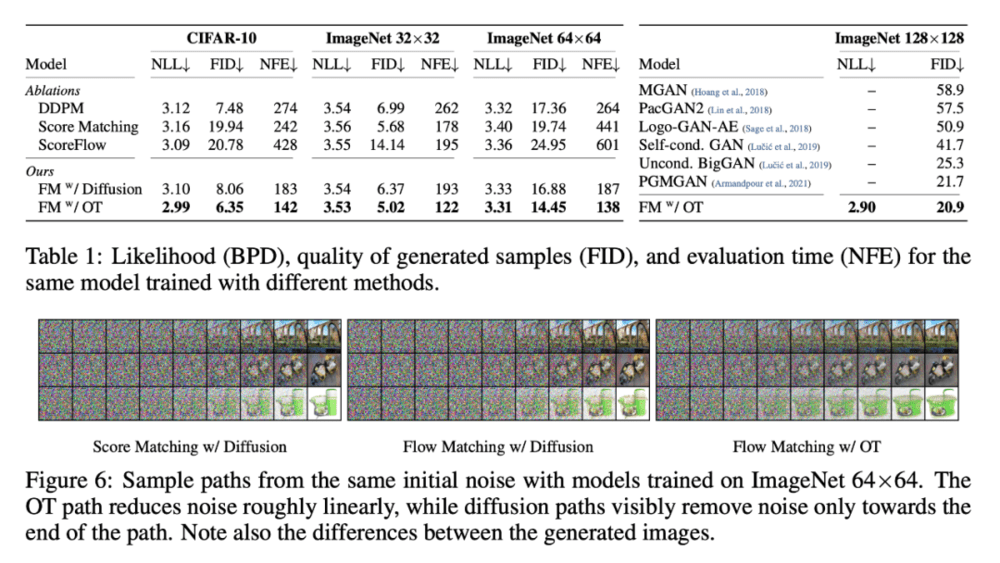
具体来说,论文提出了“Flow Matching”的概念,这是一种基于固定条件概率路径向量场回归训练 CNF 的免模拟方法。Flow Matching 与用于在噪声和数据样本之间进行转换的高斯概率路径的通用族兼容(通用族将现有的扩散路径归纳为具体实例)。
研究者发现,使用带有扩散路径的 Flow Matching 可以为扩散模型的训练提供更稳健、更稳定的替代方案。
此外,Flow Matching 还为使用其他非扩散概率路径训练 CNF 打开了大门。其中一个特别值得关注的例子是使用最优传输(OT)位移插值来定义条件概率路径。这些路径比扩散路径更有效,训练和采样速度更快,泛化效果更好。在 ImageNet 上使用 Flow Matching 对 CNF 进行训练,在似然性和采样质量方面的性能始终优于其他基于扩散的方法,并且可以使用现成的数值 ODE 求解器快速、可靠地生成采样。
参考链接:
https://stability.ai/stablediffusion3
https://www.reuters.com/markets/deals/ai-startup-jasper-acquires-image-generator-clipdrop-stability-ai-2024-02-22/
https://stability.ai/research/hourglass-diffusion-transformer-high-resolution-image-synthesis
本文来自微信公众号:机器之心 (ID:almosthuman2014),作者:张倩、蛋酱