
谷歌于2023年5月的Google I/O上官宣了Gemini, 能力接近或超过GPT-4, 真正的多模态,底层神经网络架构沿用Transformer Decoder,针对TPU做了优化,采用了multiquery attention。Transformer已成为事实上的大模型神经网络架构行业标准了,然而这个领域研究依然十分活跃,有潜力替代Transformer的后浪会出现吗?
论文“Mamba: Linear-Time Sequence Modeling with Selective State Spaces基于选择性状态空间的线性时间序列建模”,学者来自卡耐基梅隆和普林斯顿大学。论文认为Transformer架构及其核心注意力模块长序列上的计算效率低下,而采用“输入依赖的结构化状态空间”模型,无需注意力甚至MLP模块,可实现比Transformer高5倍吞吐量,提高到百万长度序列,在语言、音频和基因组学等多个模态实现最先进的性能。其3B语言模型性能甚至与两倍大小的Transformer模型匹配。
这里补充一些状态空间模型(SSM: State Space Model)的背景知识,对理解论文的思路很有助力。下面这个图,估计学过中学物理的读者都眼熟:
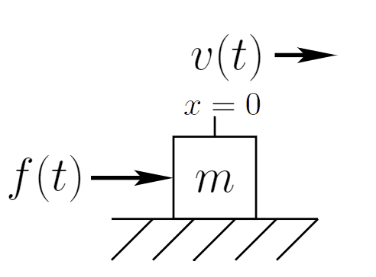
一个质量为 m 的系统, 受外力 f(t), 有位移 s(t), 速度v(t),加速度a(t), s(t) = x1, v(t) = x2, x2 可以由 x1 表示出来 (x1 偏导数),a (t) = x3, 也可以由 x1 表示出来。f(t) = u(t) 作为输入, y(t) 为输出。[ s(t), v(t), a(t) ] 构成此系统的状态向量,张成的空间即该系统的状态空间。斯坦福学者给出了更一般性的阐释:任何物理系统的运动方程都可以很方便地用它的状态来表征。
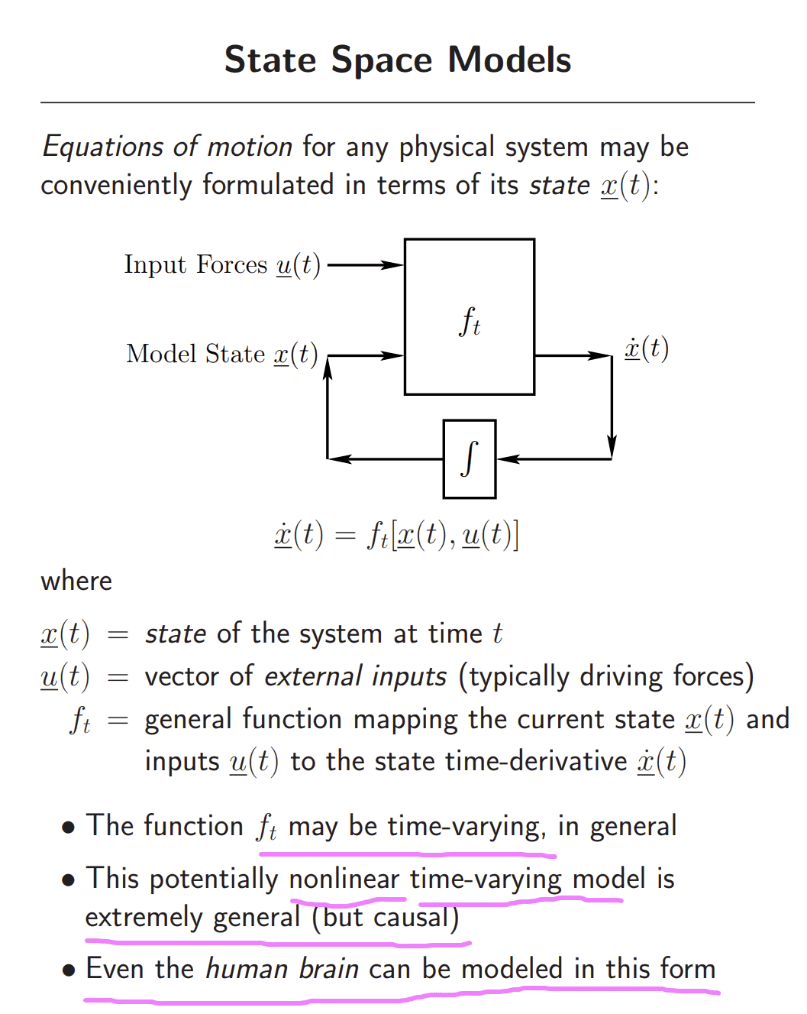
状态空间模型简单,但是具备强大的刻画能力,即使人脑也能用这个形式建模。这里概括了三个关键词:时变性time-varying,非线性nonlinear,通用性general。SSM广泛应用于许多科学领域,并与隐式马尔可夫模型(HMM)相关。
论文作者在其早前一篇获奖论文 “Efficiently Modeling Long Sequences with Structured State Spaces (用结构化状态空间高效建模长序列)”中提到:SSM 将一维输入信号u(t)映射到多维隐状态x(t),然后投影到一维输出信号y(t),可由简单的方程定义:
x'(t) = Ax(t) + Bu(t)
y(t) = Cx(t) + Du(t)
将SSM用作深度序列模型中的黑盒表征,A, B, C, D参数可通过梯度下降学习到,并可忽略D,因为Du(t)可以被视为跳过连接(skip connection)且易于计算。对方程做离散化,例如 u(t) 变成:(u0, u1, . . .) ,可视为对连续方程u(t)的采样。A,B,C以及步长Δ相应变成Ā 等离散矩阵。离散化使得上述方程由“方程到方程”变成“序列到序列” 。Ā 即系统的状态转移矩阵。
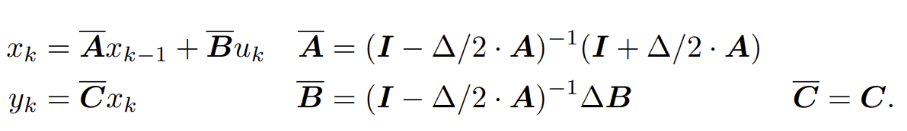
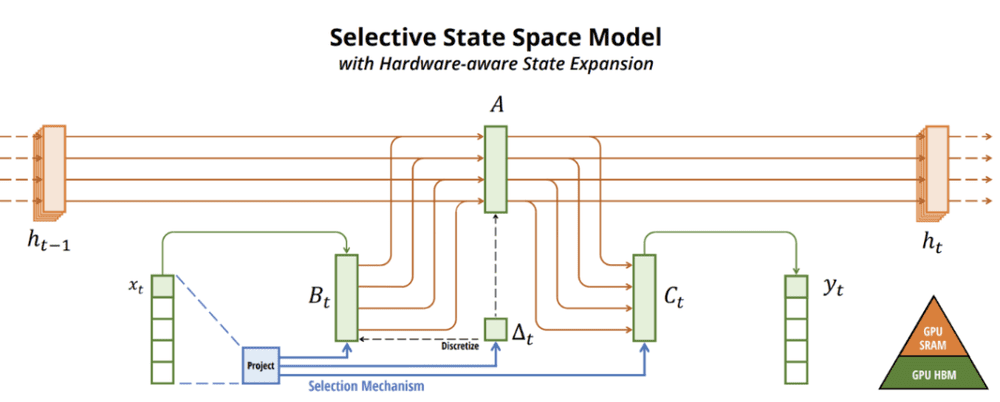
论文称Mamba模型有两大特点:1. 不使用注意力机制,核心创新是引入了选择性SSM,允许模型的参数(A,B,C, Δ)受到输入u(t)的影响,从而实现选择性信息传播;2. 为处理长序列提供了更有效的方式,使得计算和内存需求与序列长度呈线性关系,优于自注意下两者间的二次关系,并借助GPU硬件感知设计了高效算法。模型架构见下图:
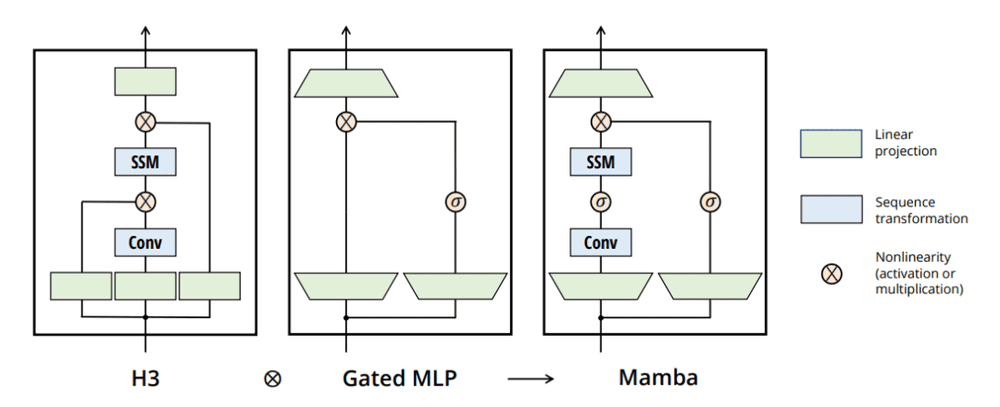
在《爱因斯坦校友提出的Transformer简化方案是条歧路》中,笔者梳理过:
1. 层归一化(layer normalization):其实是对“离散的概率向量之和与平滑的概率曲线积分”之间差异的校正,避免自由能概率分布偏离积分为 1;
2. 跳过连接(Skip Connection):通过在不同的path上跳过一些层,本质上等同于提供了不同尺度的信息提取路径,来弥补尺度选取离散化与线性化带来的非线性部分的损失;
3. 参数的多少,参数的精度,隐变量空间维度的大小都代表着模型提取信息的精准度,也就是对原始连续概率分布的拟合逼近能力。
上述三点,论文中都有体现:
首先,Mamba非常注重强化非线性部分的处理。“我们重复这个块,用标准归一化和残差连接交织,形成Mamba架构”,“离散化与连续时间系统有着深度的连接,可以赋予它们额外的属性,如解不变性与自动确保模型适当归一化”。
可以看出,论文匠心独运,不仅“SSM的离散化”处理本身保障适当归一化,还在架构上与标准归一化与残差连接交织,确保了非线性处理能力,参数和步长都是如此,因而优于Transformer特别是仍具有炼金术特征的skip connection部分。
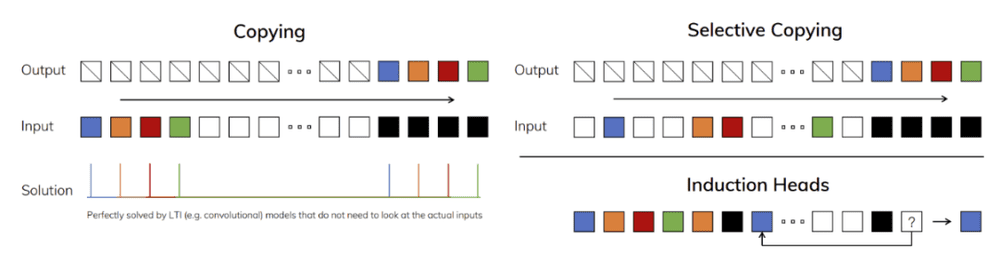
其次,增加了参数捕获能力。“允许模型的参数(A,B,C, Δ)受到输入u(t)的影响”,也就是(A,B,C, Δ)参数和步长,都作为输入u(t)的函数,使其依赖于输入以及与之伴随的张量形态的变化。笔者觉得这是在用输入input的信息概率分布distribution的形态shape,不断校准潜变量参数和步长,本质上效果与attention类似。
论文认为,线性时不变LTI模型的失败,从递归的角度来看,常数的状态转移不能从上下文中选择正确的信息。RWKV的WKV机制采用LTI 线性时不变,可见其模型的局限。序列模型的效率与有效性权衡以状态压缩的程度为特征:高效模型须小,而有效模型须包含上下文必要信息。构建序列模型的基本原则是选择性,或上下文感知能力。
Mamba让参数获得依据上下文提取信息的能力,强化了模型的参数捕获和对上下文的表征能力,与笔者在《爱因斯坦校友提出的Transformer简化方案是条歧路》中的观点一致:增加模型的精度,增加隐变量的数量,可以扩大隐变量空间的维度,提高概率向量对实际信息的表征能力的丰富性,强化信息细微差别的区分能力。

Mamba所展现的能力,与笔者判断也一致“各种DNN深度神经网络,本质上只要沿着这个思路增加参数捕获能力,都可以与Transformer殊途同归”,即使其并行性与百亿参数超大规模能力和效率仍有待观察。
细心读者可能注意到一个细节,论文对参数矩阵A是这样处理的:虽然A参数也可以是选择性的,但它最终只通过与∆的相互作用(A = exp(∆A)) 来影响模型。因此,∆的选择性足以确保(A,B)的选择性,并且是改进的主要来源。我们假设,除了∆,使A具有选择性将具有类似的性能,简单起见将其省略。
不知道是否笔者理解不到位,原始信息的概率分布是个多维度(甚至高维)的联合概率分布,步长Δ或者skip connection仅仅是修正一个维度(信息层次)的非线性,其他维度的非线性也需要修正。下图是笔者头脑里对论文涉及问题的整体思维模型:
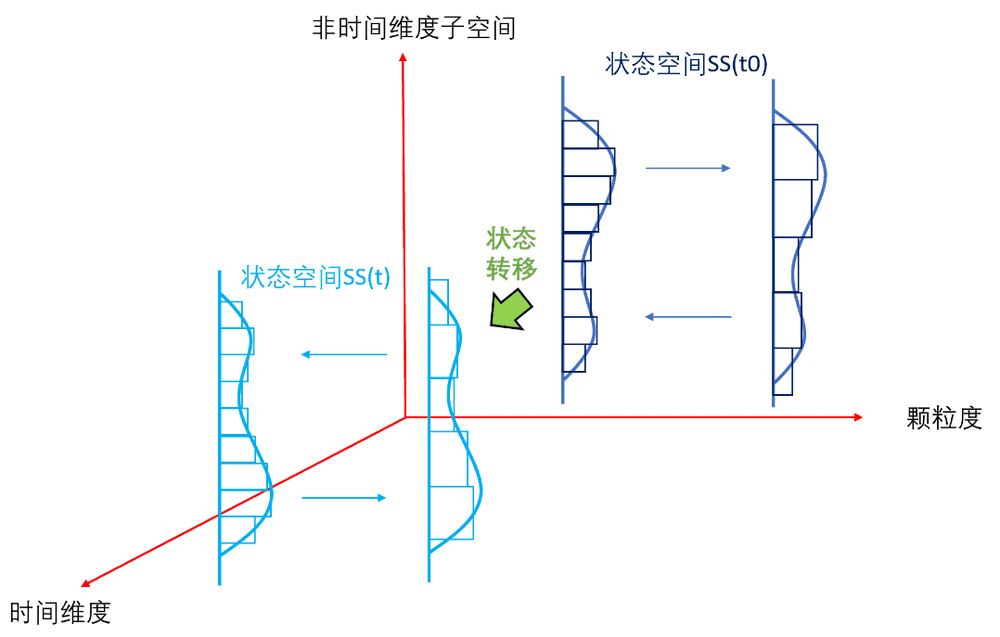
1. 状态空间对事物的表征和刻画:状态空间的高维度,某时刻的信息,即某时刻的事物的能量的概率分布,是众多维度的联合概率分布,各维度都可能具有连续性和非线性,如何用线性系统近似,并尽最大努力消除非线性的影响非常关键;不同层次的潜变量空间,对信息的提取,和粗颗粒度逐层抽象,都需要类似重整化群RG中的反复归一化,以消除“近似非线性处理”对整体概率为1的偏离;
2. 状态空间的动态性:即从时间的维度,研究整个状态空间的变迁。这个变迁是状态空间的大量非时间维度的信息逐层提取,叠加时间这一特殊维度的(状态-时间)序列sequence。不管是高维度低层次的细颗粒度的概率分布的时间变化,还是低维度高层次的粗颗粒度概率分布的时间变化,都是非线性时变系统,用线性时不变(LTI)的模型都是无法很好刻画的。
3. 状态空间时间序列的非马尔可夫性:思考attention的价值,时序数据上的attention注意到了什么?诸如趋势, 周期性, 一次性事件等。非时间维度子空间内的attention,注意到的是范畴内与范畴间的关系, 即某个时刻的状态空间。状态空间的时序,研究的是状态空间的动力学,外在驱动“力”或因素导致的状态的“流动”,即状态空间t时刻与t-n时刻之间的关系,注意到是其时间依赖规律,往往不具备马尔可夫性。
《薛定谔的小板凳与深度学习的后浪》中笔者引用“概率学界学术教父” 钟开莱先生在他的Green, Brown and Probability一书中的论述:“马尔可夫性质意味着,当现在已知时,过去不会对未来产生后效影响;但请注意,由于误解了“现在已知”这句话的确切含义,已经铸成了大错” 。
下面这个“年轻的父母接送孩子上下学”的例子可以帮助理解钟先生这句话:
State t-1 在家 state t 学校 state t+1 公司 : 送娃上学
State t-1 公司 state t 学校 state t+1 在家 :接娃回家
t时刻的隐状态空间表征能力很重要,当状态空间仅仅是“state t 学校”时,无法获知state t+1的状态,因为其还取决于state t-1的状态,而且甚至需要看t-n时刻 ,比如上周末老师布置了t时刻放学后去礼堂看演出。仔细想想,语言自回归,非马尔可夫性其实是常态,事实上时延系统基本都是非马尔可夫的。attention或者状态空间的选择性就非常关键。
Pytorch创始团队负责人硅谷AI大佬Bill Jia认为,现在大模型应该从侧重空间关联转向加强时间关联。笔者觉得Bill 说的空间关联对应笔者上图中“非时间维度子空间”,而时间关联则是对应“状态空间的动态性”以及处理好“非马尔可夫性”。
Mamba论文Time sequence modeling是这个方向的有益探索,具备很强的潜力,而且逻辑上判断也可以适用于多模态。Transformer Decoder基本统一了大语言模型的神经网络架构,切换成新架构将会带来难以估量的成本,包括沉没成本、迁移成本、有风险的机会成本等。笔者觉得Mamba后续可以侧重类似TimeGPT那样的预测泛化场景,给AI4Science带来有益的想象空间。
参考资料:
1.Efficiently Modeling Long Sequences with Structured State Spaces https://arxiv.org/pdf/2111.00396.pdf
2.Mamba: Linear-Time Sequence Modeling with Selective State Spaces https://arxiv.org/ftp/arxiv/papers/2312/2312.00752.pdf
本文来自微信公众号:清熙(ID:qingxitech),作者:王庆法