
AI视频赛道上,谷歌再次放出王炸级更新!
这个名为Google Lumiere的模型,是一个大规模视频扩散模型,彻底改变了AI视频的游戏规则。
跟其他模型不同,Lumiere凭借最先进的时空U-Net架构,在一次一致的通道中生成整个视频。
具体来说,现有AI生成视频的模型,大多是在生成的简短视频的基础上对其进行时间采样而完成任务。
而谷歌推出的新模型Google Lumiere是通过联合空间和“时间”下采样(downsampling)来实现生成,这样能显著增加生成视频的长度和生成的质量。
 论文地址:https://arxiv.org/abs/2401.12945
论文地址:https://arxiv.org/abs/2401.12945
值得一提的是,这是谷歌团队历时7个月做出的最新成果。
对于这惊人的“谷歌速度”,网友们纷纷表示惊叹——谷歌从来不睡觉啊?
开发者回答:不睡
居然做出了走路、跳舞这样的人体力学视频,我的天,我以为这需要6到12个月才能做出来,AI真的是在以闪电般的速度发展。(我的工作流中需要这个模型。)
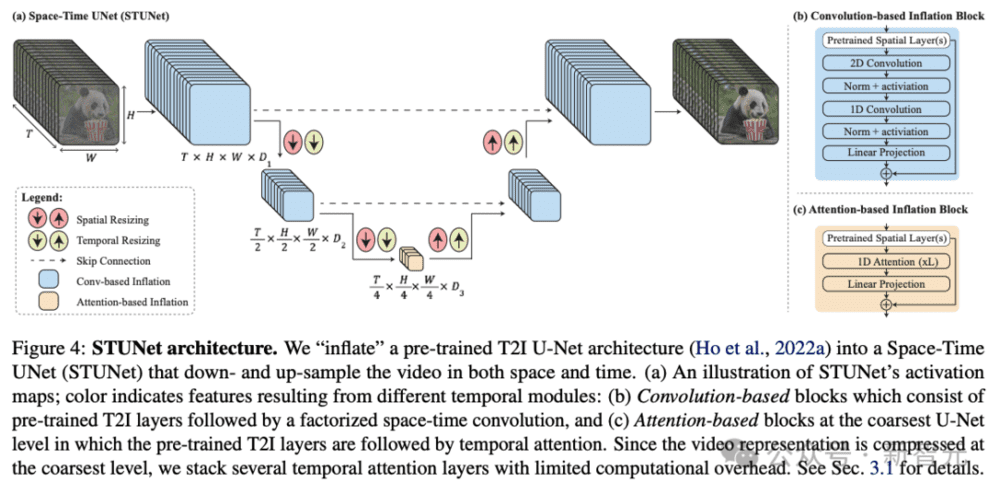
一、全新STUNet架构:时间更长更连贯
为了解决AI生成视频长度不足,运动连贯性和一致性很低,伪影重重等一系列问题,研究人员提出了一个名为Space-Time U-Net(STUNet)的架构。

传统视频模型生成的视频往往会出现奇怪的动作和伪影
该架构能够将视频信号在空间和时间上同时进行下采样和上采样,并在网络的压缩空间时间表征上执行主要计算。
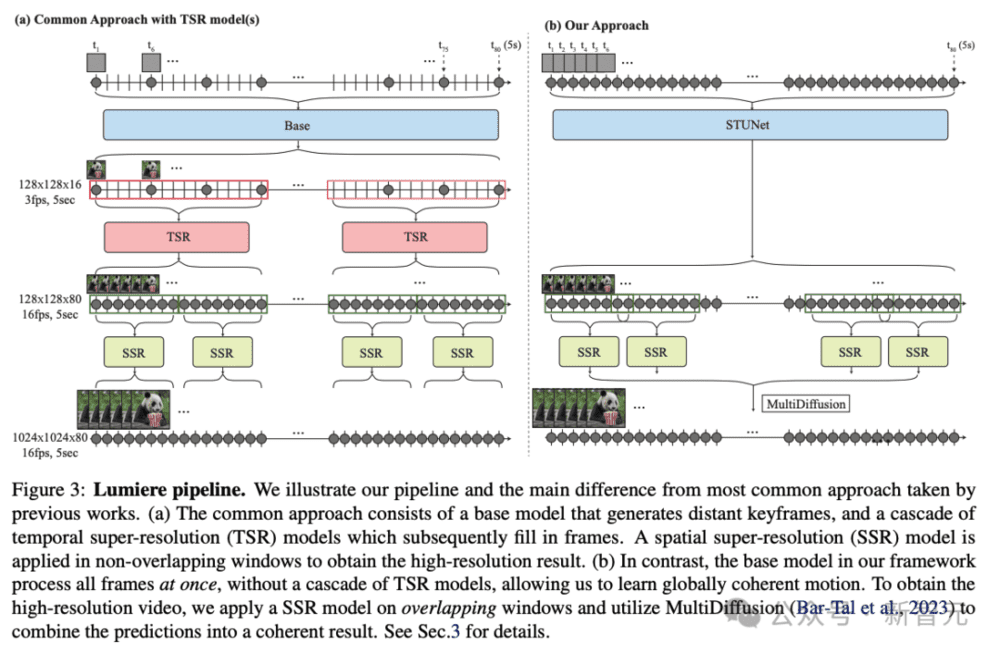
相比之前的文本到视频模型采用级联设计的方式,先由基模型生成关键帧,然后使用一系列时序超分辨率模型在非重叠段内进行插值帧的生成。
STUNet可以学习直接生成全帧率的低分辨率视频。这种设计避免了时序级联结构在生成全局连贯运动时固有的限制。
STUNet架构可以直接生成5秒长的80帧视频,时间长度超过大多数媒体中的平均镜头长度,这可以产生比之前模型更连贯一致的运动。



二、功能丰富,效果拔群
1. 视频编辑/修复
这项功能可以让我们编辑视频,或者在视频中插入对象。
比如这个穿绿底白花裙的女孩,只要选中衣服区域,输入文字修改要求,就能瞬间把她的裙子改成红白条纹裙、金色抹胸裙。

正在跑步的女孩,只要用文字编辑,就可以让她长满鲜花,或者变成木砖风、折纸风、乐高风。

也可以专门针对视频中某一部分的内容进行修改和编辑。

2. 图生视频
Lumiere另外一个非常好用的功能,就是将静止图像转换为动态视频。
输入文字提示,就能让戴珍珠耳环的少女从名画中走出,张嘴笑了起来。

梵高画的《星空》,夜空中的星星和云层真的开始流动了起来。

3. 风格化生成
Lumiere能生成各种指定艺术风格的视频。
只要给出一个指定的风格,再通过文字提示,就能按照类似风格生成非常多的视频。

可以看到,对比参考静图的风格来看,生成视频的风格复现得非常精准。

4. 动作笔刷
通过这个名为Cinemagraphs(又名 Motion Brush)的风格,我们可以选中静图中的特定部分,让它动起来。
选中图中的这团火焰,它就开始熊熊燃烧起来。

选中图中的烟,火车就开始冒出汩汩浓烟来。

5. 文生视频
当然,Lumiere也可以直接从文本生成详细的视频。
无论是一个在火星基地周围漫步的宇航员。

还是一只戴着太阳镜开着车的狗。

或者飞过一座废弃的庙宇,在遗迹中穿行。

还可以针对视频中缺失的部分进行补充。

三、STUNet架构带来的全新突破
这次,谷歌的研究者采用了跟以往不同的方法,引入了新的T2V扩散框架,该框架可以立即生成视频的完整持续时间。
为了实现这一目标,他们使用了STUNet架构,这个架构可以学习在空间和时间上对信号进行下采样,并且以压缩的时空表征形式,执行大部分计算。
 Lumiere生成的示例结果,包括文本到视频生成(第一行)、图像到视频(第二行)、风格引用生成和视频修复(第三行边界框表示修复掩码区域)
Lumiere生成的示例结果,包括文本到视频生成(第一行)、图像到视频(第二行)、风格引用生成和视频修复(第三行边界框表示修复掩码区域)
采用这种方法,就能够以16fps(或5秒)生成80帧,这比大多数使用单一基础模型的媒体要好。
跟之前的工作相比,产生了更多的全局连贯运动。
令人惊讶的是,这种设计选择被以前的T2V模型忽视了,这些模型遵循惯例,在架构中仅包含空间下采样和上采样操作,并在整个网络中保持固定的时间分辨率。
 使用Lumiere和ImagenVideo进行周期性运动生成视频的代表性示例。研究者应用 Lumiere图像到视频生成,以ImagenVideo生成的视频的第一帧为条件,可视化相应的X-T切片。由于其级联设计和时间超分辨率模块,Imagenvideo难以生成全局连贯的重复运动,而这些模块无法跨时间窗口,一致地解决混叠模糊问题
使用Lumiere和ImagenVideo进行周期性运动生成视频的代表性示例。研究者应用 Lumiere图像到视频生成,以ImagenVideo生成的视频的第一帧为条件,可视化相应的X-T切片。由于其级联设计和时间超分辨率模块,Imagenvideo难以生成全局连贯的重复运动,而这些模块无法跨时间窗口,一致地解决混叠模糊问题
研究人员的框架由基本模型和空间超分辨率(SSR)模型组成。
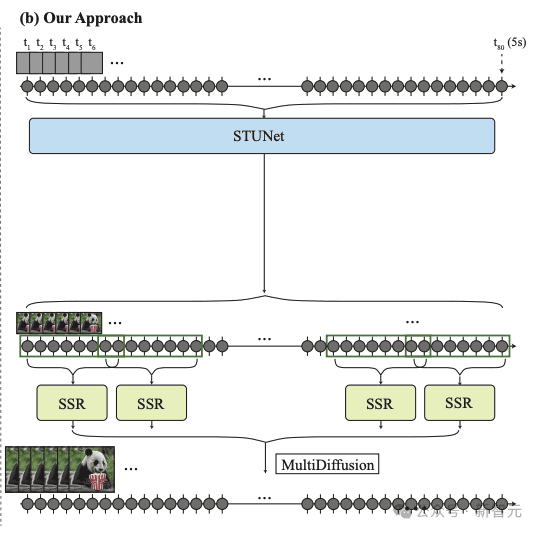
如上图3b所示,研究人员的基础模型以粗略的空间分辨率生成完整的剪辑。
他们的基础模型的输出使用时间感知的SSR模型进行空间上采样,从而产生高分辨率视频。
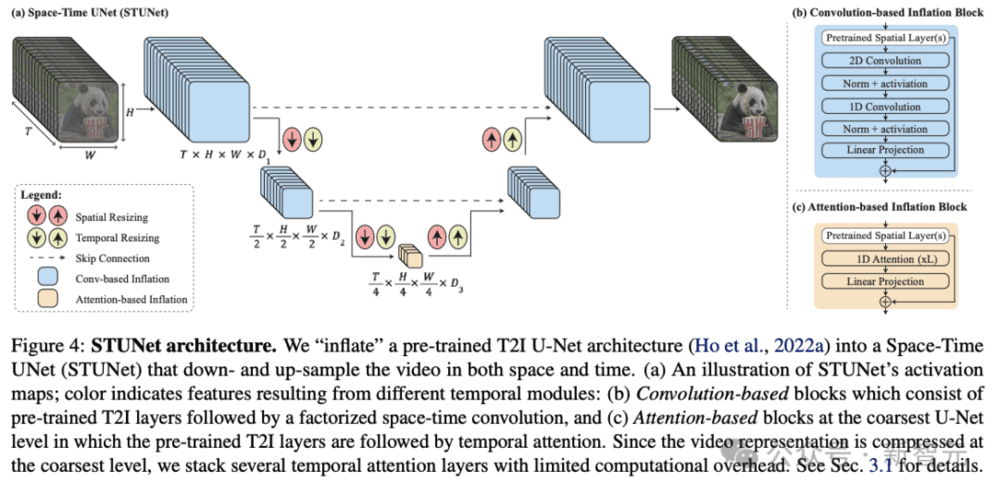
研究人员的架构如上图所示。
他们在T2I架构中交织时间块,并在每个预训练的空间调整大小模块之后插入时间下采样和上采样模块(图4a)。时间块包括时间卷积(图4b)和时间注意力(图4c)。
具体来说,在除了最粗糙的级别之外的所有级别中,他们插入因式分解的时空卷积(图4b),与全3D卷积相比,它允许增加网络中的非线性,同时降低计算成本,并与一维卷积。
由于时间注意力的计算要求与帧数呈二次方关系,因此他们仅在最粗分辨率下合并时间注意力,其中包含视频的时空压缩表示。
在低维特征图上进行操作允许他们以有限的计算开销堆叠多个时间注意力块。
研究人员训练新添加的参数,并保持预训练T2I的权重固定。值得注意的是,常见的膨胀方法确保在初始化时,T2V模型相当于预训练的T2I模型,即生成视频作为独立图像样本的集合。
然而,在研究人员的例子中,由于时间下采样和上采样模块,不可能满足这个属性。
他们凭经验发现,初始化这些模块以使它们执行最近邻下采样和上采样操作会产生一个良好的起点(就损失函数而言)。
四、应用展示
以下是文生视频和图像生视频的示例。
从图像到视频的示例中,最左边的帧是作为条件提供给模型的。




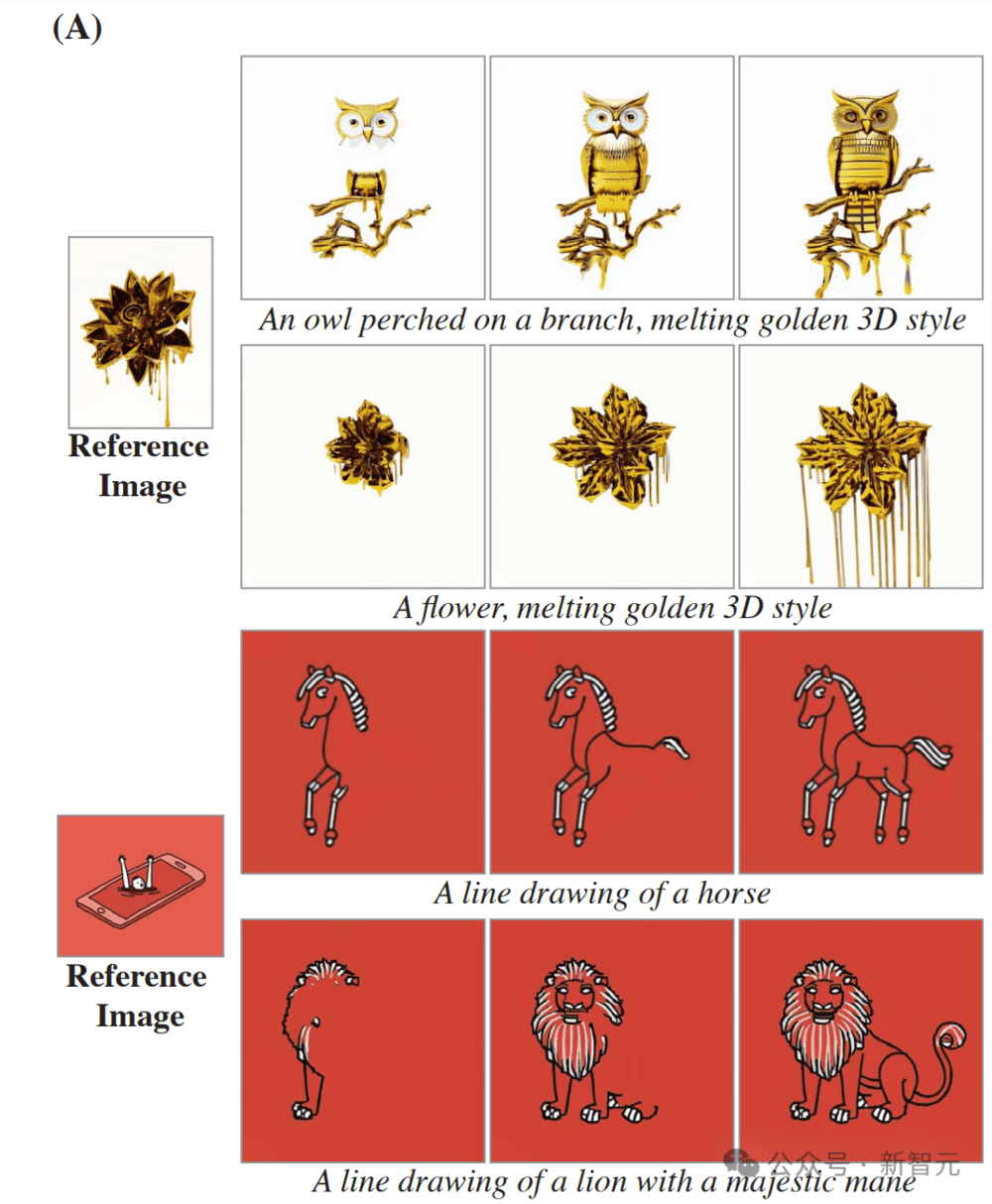
以下是风格化生成的示例。
给定起始风格图像及其相应的一组微调文本到图像权重,就可以在模型空间层的微调权重和预训练权重之间执行线性插值。
研究者展示了(A)矢量艺术风格和(B)写实风格的结果。
这证明了,Lumiere能够为每种空间风格创造性地匹配不同的运动(帧从左到右显示)。
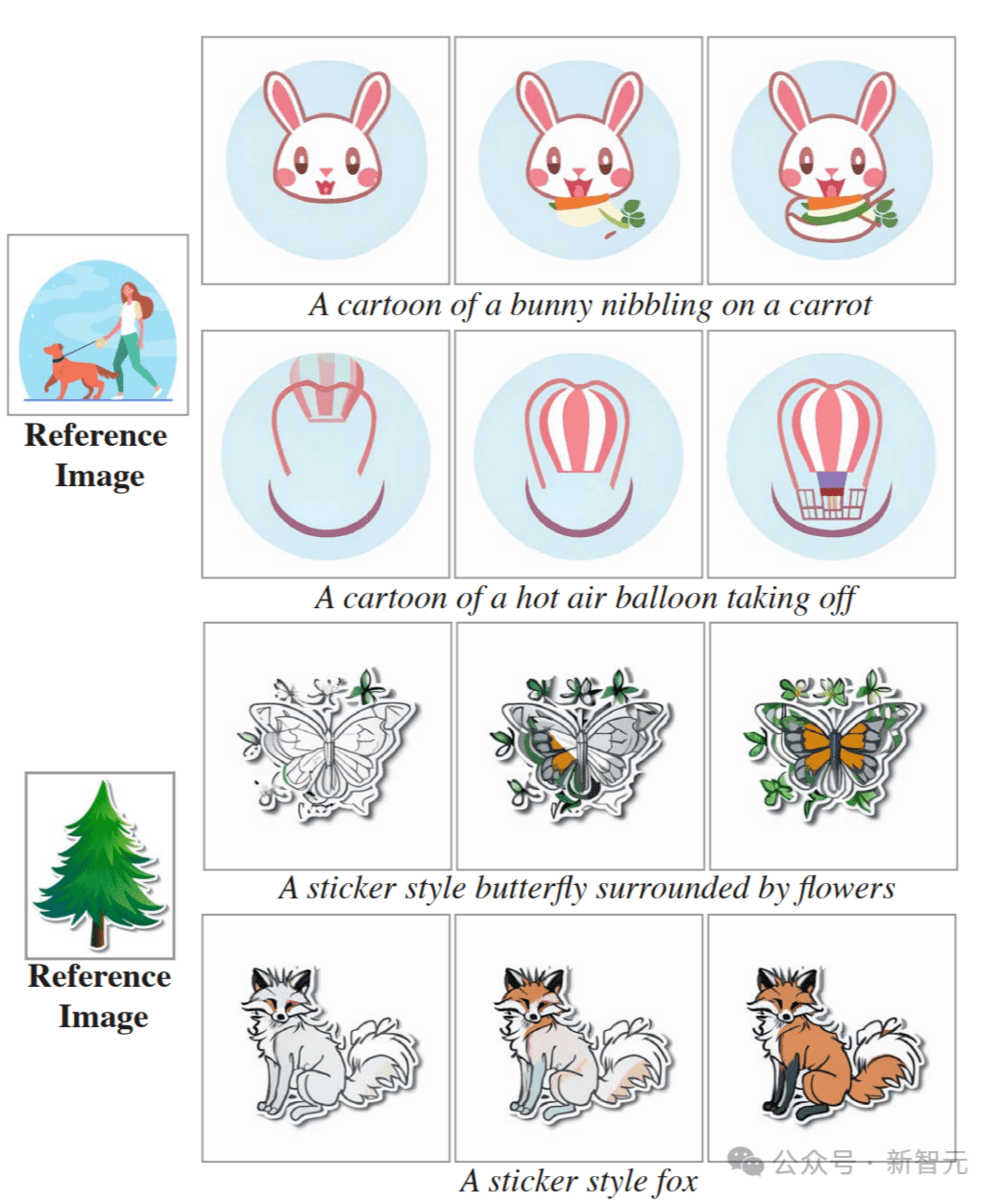


以下是使用Lumiere进行视频修复的示例。
对于每个输入视频(每个帧的左上角),研究者都使用了Lumiere对视频的掩码区域进行了动画处理。


以下为动态图像的示例。
仅给定输入图像和掩码(左),研究者的方法会生成一个视频,其中标记区域是动态的,其余部分保持静态(右)。
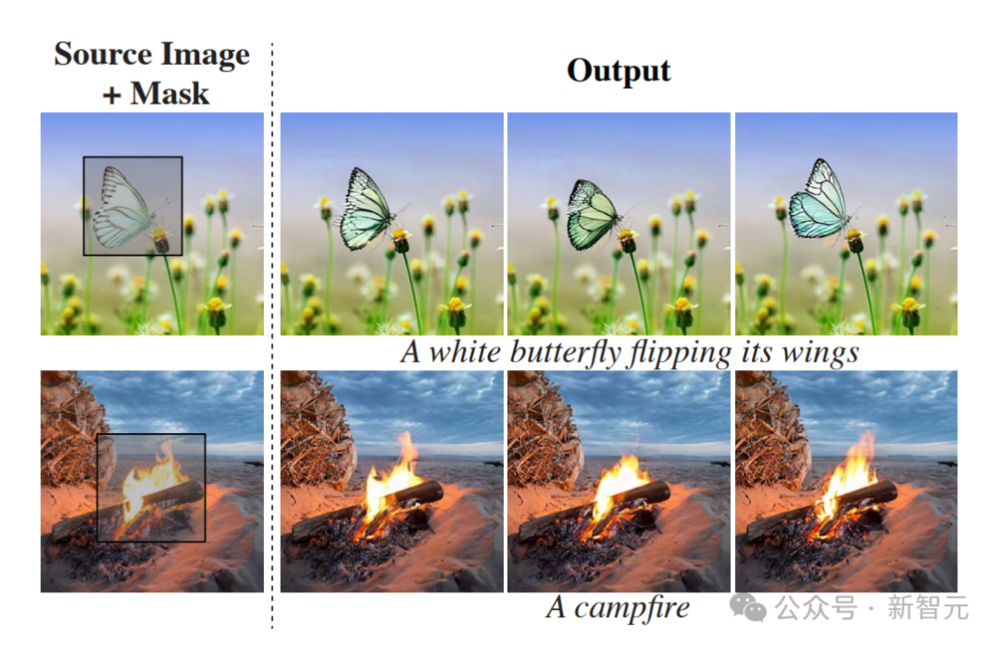
以下是通过SDEdit进行视频生视频的示例。
Lumiere基本模型可以生成全帧率视频,无需TSR级联,从而为下游应用程序提供更直观的界面。
研究者通过使用SDEdit来演示此属性,从而实现一致的视频风格化。在第一行显示给定输入视频的几个帧,下面几行显示相应的编辑帧。


五、与Gen-2和Pika等模型的对比和评估
1. 定性评估
研究人员在下图中展示了他们的模型和基线之间的定性比较。

研究人员观察到Gen-2和Pika表现出较高的每帧视觉质量,然而,它们的输出的特点是运动量非常有限,通常会产生接近静态的视频。
ImagenVideo产生合理的运动量,但整体视觉质量较低。AnimateDiff和ZeroScope表现出明显的运动,但也容易出现视觉伪影。
此外,它们生成的视频持续时间较短,分别为2秒和3.6秒。
相比之下,研究人员的方法生成的5秒视频具有更高的运动幅度,同时保持时间一致性和整体质量。
2. 定量评估
研究人员在UCF101上定量评估了他们的零样本文本到视频生成方法。
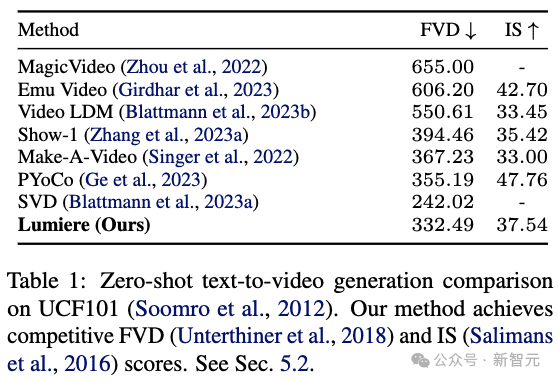
上表1展示了他们的方法和之前工作的区别(FVD)和初始分数(IS)。
研究人员的系统取得了具有竞争力的FVD和IS分数。然而,正如之前的工作中所讨论的,这些指标并不能准确地反映人类的感知,并且可能会受到低级细节以及参考UCF101数据和T2V训练数据之间的分布变化。
此外,该协议仅使用生成视频中的16帧,因此无法捕获长期运动。
3. 用户研究
研究人员采用了之前的工作中使用的两种强制选择(2AFC)协议。
在该协议中,向参与者展示了一对随机选择的视频:一个由研究人员的模型生成,另一个由一种基线方法生成。然后,参与者被要求选择他们认为在视觉质量和动作方面更好的视频。
此外,他们还被要求选择与目标文本提示更准确匹配的视频。研究人员利用 Amazon Mechanical Turk(AMT)平台收集了约400个用户对每个基线和问题的判断。
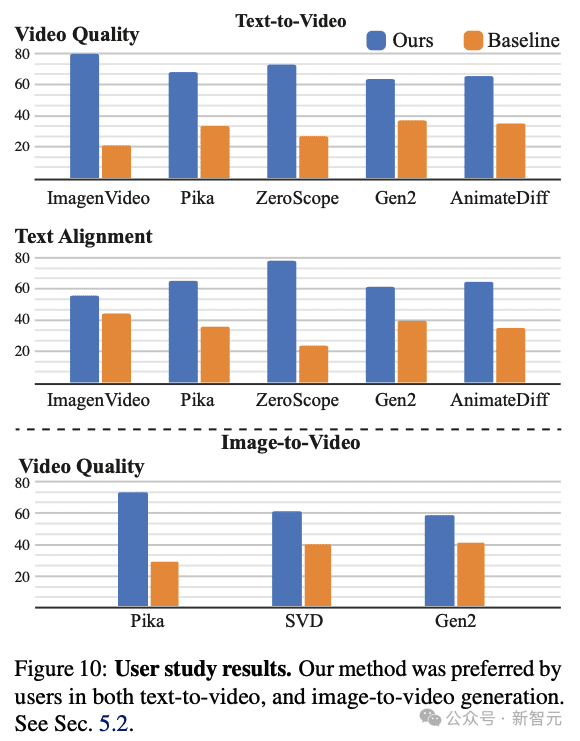
如上图所示,研究人员的方法比所有基线都更受用户青睐,并且与文本提示联系更加紧密。
请注意,ZeroScope和AnimateDiff分别仅生成3.6秒和2秒的视频,因此在与它们进行比较时,研究人员会修剪视频以匹配其持续时间。
研究人员进一步进行了一项用户研究,将他们的图像到视频模型与Pika、Stable Video Diffusion(SVD)和Gen-2进行比较。
请注意,SVD图像到视频模型不以文本为条件,因此研究人员将调查重点放在视频质量上。如上图所示,与基线相比,研究人员的方法更受用户青睐。
参考资料:https://arxiv.org/abs/2401.12945
本文来自微信公众号:新智元 (ID:AI_era),作者:新智元