
OpenAI:家人们谁懂,又坐上被告席
有近两个世纪历史的《纽约时报》,正式拿起法律武器硬刚OpenAI。为了更好地训练模型,OpenAI从互联网等渠道获取第三方数据,用于大模型的训练。这些数据就包含了《纽约时报》发表的时事新闻稿。
从去年4月份开始,纽约时报就试图与OpenAI和微软就大模型的知识产权等问题进行谈判,试图与OpenAI达成协议。但在2023年的尾声,美国当地时间12月27日,《纽约时报》正式起诉OpenAI和微软。
《纽约时报》在接近70页的诉状中[1],称ChatGPT几乎能够生成与《纽约时报》作品一模一样的内容,并在诉状中通过图片标注比对的方式,清晰地呈现被告的侵权证据。《纽约时报》指控各被告构成直接和间接的版权侵权、删除《纽约时报》的版权管理信息、构成普通法的不正当竞争、对《纽约时报》的造成商标淡化等,要求被告承担赔偿责任,并对模型中包含纽约时报作品的内容的训练集进行销毁。
《纽约时报》控诉OpenAI的四宗罪
《纽约时报》的起诉状长达70页,本文主要讨论《纽约时报》指控内容的其中4项,帮助你快速了解到底OpenAI惹了哪些事:
1.未经授权,复制、使用《纽约时报》的作品用于模型训练
《纽约时报》在诉状中提出,GPT-2包含15亿个参数,数据训练集包括WebText语料库,《纽约时报》的域名是WebText数据集中占比最多的域名之一。
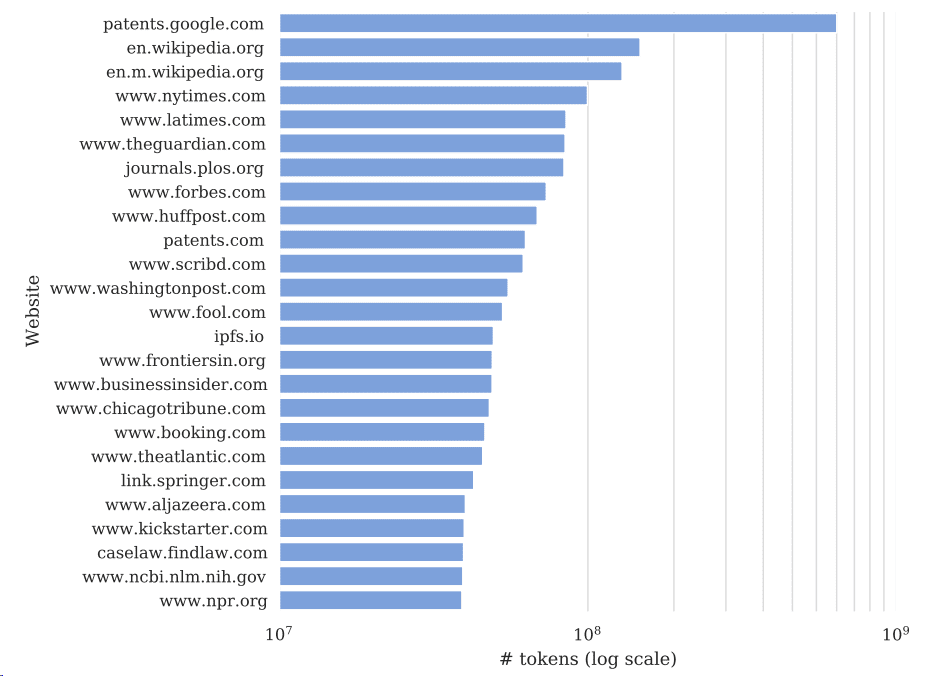
GPT-3包含1750亿个参数,而其中权重最高的模型训练数据集是Common Crawl(一个免费开放的语料库),而《纽约时报》网站内容正是Common Crawl占比最大的数据来源(仅次于谷歌专利和维基百科)。
通过呈现ChatGPT生成内容与《纽约时报》作品的高重合度,《纽约时报》认为ChatGPT必然已经使用过《纽约时报》的作品进行训练,才能够生成数量如此庞大的摘要和报道文本。
2.未经授权,生成与《纽约时报》作品几乎全文相同的内容
《纽约时报》在起诉状中以一篇报道作为证据举例,该报道是关于纽约出租车司机贷款的事件,整个系列报道耗时长达18个月、经历数百次的采访,最终不仅获2019年普利策奖(美国新闻界的最高荣誉奖),更是推动了美国相关法律法规的制定。而ChatGPT却能够在极少提示词的情况下,逐字逐句输出与《纽约时报》报道相同的内容。

(《纽约时报》对“出租车司机贷款”事件的报道与GPT-4生成内容的比对,红色字体表示一致)
这样的例证还有很多,均用来证明OpenAI可以直接向用户生成本应付费订阅的内容,导致《纽约时报》的订阅、广告、许可等收入的减少,严重损害《纽约时报》的权益。
3.ChatGPT产生幻觉,捏造了《纽约时报》的假新闻
幻觉(Hallucinations)通常指的是大模型捏造的、非真实存在或不准确的信息。对于用户而言,有时候往往难以辨别模型生成的内容是否包含虚假信息(这也是笔者在以往反复强调,必须对AI生成内容进行核验的原因)。《纽约时报》就在诉状中举了一个例子:
向ChatGPT提问:《纽约时报》在这篇文章中提到的15 种最有益心脏健康的食物是什么,同时附上《纽约时报》该篇文章的链接。
而Bing Chat(由微软开发的模型,现已更名为Copilot)在回答中提到“红酒(适量)”,但实际上,《纽约时报》的该文章并没有提到红酒对心脏有益。相反,《纽约时报》曾在另一篇报道中指出红酒不利于心脏健康。

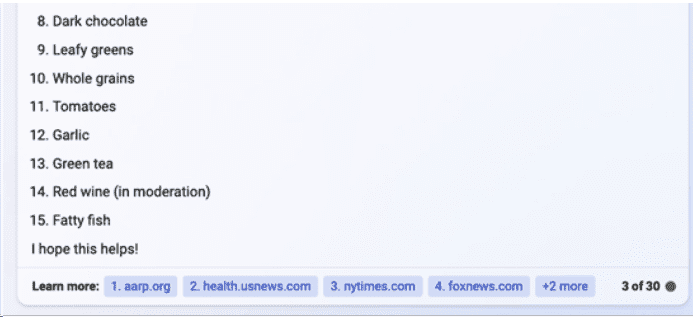
(Bing Chat的回答中包含“红酒(适量)”)
不仅如此,《纽约时报》还指出,ChatGPT捏造了一篇《纽约时报》从未发布过的题为《研究发现橙汁与非霍奇金淋巴瘤之间可能存在联系》的文章。在被要求提供《纽约时报》关于Covid-19大流行病的报道时,ChatGPT的应用程序接口返回了一个捏造的标题和一条实际不存在的报道超链接。
4.微软和OpenAI构成对《纽约时报》的不正当竞争
《纽约时报》根据普通法,指控被告构成不正当竞争,主要有以下几点理由:
(1)《纽约时报》的报道多为突发新闻,需为新闻报道花费高昂成本;
(2)被告生成与《纽约时报》发布作品相同或近似的内容,被告的大模型与《纽约时报》的作品形成直接竞争关系。同时,被告在模型输出《纽约时报》作品内容时删除特定的文章链接,剥夺《纽约时报》可能获得的广告、推广等收入,使《纽约时报》的权益遭受实际损失。
(3)被告使用《纽约时报》的内容来训练、开发与《纽约时报》相同类型信息文本的模型,与《纽约时报》进行内容和用户的流量争夺,也是对《纽约时报》的搭便车行为。
这题我做过:与我国大众点评诉百度地图案的比较分析
AI模型研发商们,已经不是第一次被控构成不正当竞争了。
在艺术家诉Stability、Midjourney和DeviantArt集体诉讼中,原告亦主张被告构成不正当竞争。在国内,笔神作文也曾在去年发文控诉学而思爬取其作文库数据,疑似用于学而思作文AI助手的模型开发,称学而思构成不正当竞争(据了解,随后双方就该事件达成和解)。
但本案也让笔者想到早些年国内的大众点评诉百度地图不正当竞争案[2]。
在大众点评诉百度地图案中,大众点评认为,百度根据垂直搜索技术来抓取大众点评的信息,并在百度地图页面直接呈现其抓取的大众点评网的信息,构成了不正当竞争。相比而言,《纽约时报》一案中,OpenAI使用训练数据的行为与垂直搜索技术有一定相似性,更是因为使用了大模型而可以进一步,检索、整合、总结用户想要的内容。
因此,举轻以明重,大众点评诉百度地图案的审判思路,或许仍可以给中国法律背景下,大模型是否构成不正当竞争一定的启发。借鉴大众点评诉百度地图案的判决思路,笔者分析如下:
1.原被告是否具有竞争关系?
在大众点评诉百度地图案中,法院指出,对于竞争关系的判定不应局限于相同行业、相同领域或相同业态模式等固化的要素范围,而应从经营主体具体实施的经营行为出发加以考量。因此,就大模型开发者与不同的经营者主体而言,只要双方存在争夺相同的用户群体,就可能被认定为存在竞争关系。
2.被告是否构成对原告的市场替代?
在《纽约时报》一案中,被告可以直接生成原告的付费订阅内容,且生成内容几乎与原告作品一致,导致用户无需订阅即可查看《纽约时报》的内容,引发原告的用户的订阅收入、广告收入等的减少。因此,被告可能对原告构成市场替代。
3.被告的行为是否具有不正当性?
(1)大模型的爬取、生成内容是否超出必要限度?
在《纽约时报》案中,OpenAI等公司开发的大模型生成与权利人作品几乎一致的内容,未主动附上原作品链接,则可能超出必要限度。
(2)模型在生成内容中直接输出相关新闻报道或文章,是否具有积极效应?是否违反比例原则?
在用户体验方面,不得不承认的是,用户直接向AI产品提问,即可快速获得想要的内容,甚至可以要求其进行分析、概括等,对提升用户体验方面存在一定的积极作用。但同样不得忽视大模型因幻觉杜撰虚假内容而引发的可能对消费者权益造成的损害。
因此,如果以大众点评诉百度地图案来类比《纽约时报》诉OpenAI案,OpenAI构成不正当竞争的可能性较高。
AI生死战:本案为何如此重要?
这起被称为里程碑的诉讼,已经不仅仅是《纽约时报》和OpenAI之间的版权大战那么简单,案件的结果将势必对整个AI行业的发展方向产生深远影响。
如果法院支持《纽约时报》,必定会引发更多新闻出版商对OpenAI提起类似的诉讼,除了面临巨额赔偿,大模型进行数据训练将变得举步维艰,因为要在信息的汪洋大海中一一获得著作权人的“合法授权”极其困难,而数据训练是大模型的“活水之源”“立足之本”,“戴着镣铐跳舞”必将限制了AI发展的步伐。
相反,如果OpenAI胜诉,这无疑将极大鼓励了AI技术研发“大胆干”,但可能也意味着倚赖内容为生的版权商们,将萌生极其强烈的不安全感,冒死爆肝、熬夜秃头创作出来的内容,通过几行提示词就被AI“复制粘贴”出来,这必然也是对传统版权保护法律制度的挑战。
众所周知,AI法律圈内还在对Stable Diffusion案争论不休。传统的知产三法和反法,在新的科技浪潮下何去何从。那句唐顾问常常挂在嘴边的“著**法已死”,是过于激进剧烈情绪宣泄,还是AI冲击之下的真实写照?人机如何共享共荣、大模型数据训练的合法边界在哪?这些问题还有待我们探索。
参考资料:
[1]https://nytco-assets.nytimes.com/2023/12/NYT_Complaint_Dec2023.pdf
[2]上海知识产权法院,(2016)沪73民终242号,北京百度网讯科技有限公司与上海汉涛信息咨询有限公司其他不正当竞争纠纷二审民事判决书
作者简介:
李琪瑶律师,华南理工大学法律硕士研究生,英语专业八级。现为北京市隆安(广州)律师事务所律师,隆安湾区人工智能法律研究中心研究员。李琪瑶律师具有上市公司法务及知识产权代理机构经验,专注于知识产权领域理论研究与实务。
李霏律师,广东警官学院法学学士,现为北京市隆安(广州)律师事务所律师、隆安湾区人工智能法律研究中心研究员。李霏律师服务过多个文化广电旅游体育部门、博物馆以及互联网文化传媒企业,兼具“商业法律+刑事风控”工作思维,擅长企业舆情危机防范及处置,致力于以法律方式实现客户商业目的。
本文来自微信公众号:AI合规圈(ID:gh_344b08562741),作者:李琪瑶、李霏