
已经有多项研究及报告表明,用于人工智能训练的各类数据正在被迅速地消耗并趋于枯竭,而“合成数据”在人工智能的训练中被越来越多使用,且将超过真实数据的占比。
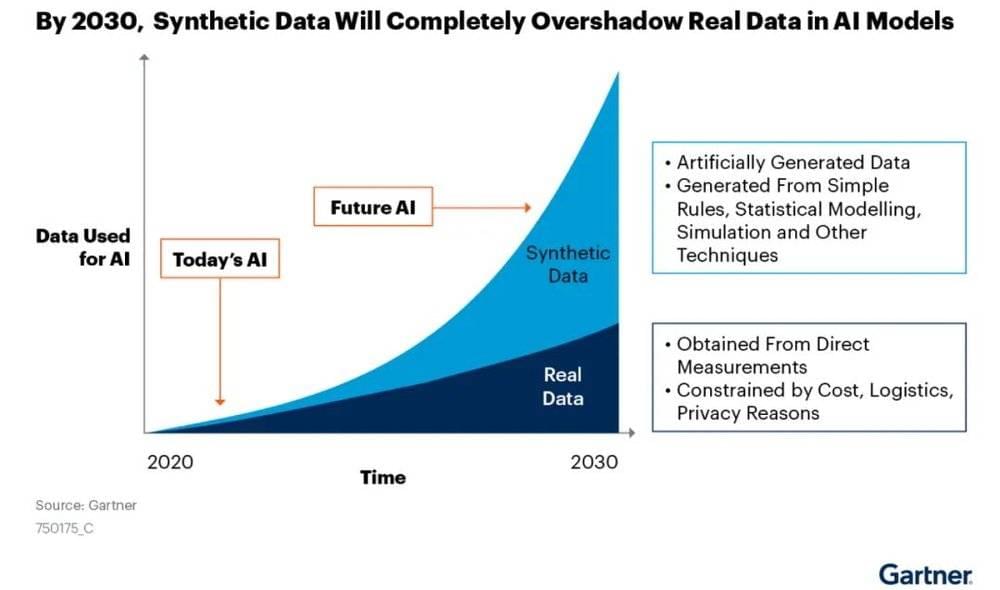
Gartner报告预测,到2030年,合成数据在AI模型中的使用将完全超过真实数据
什么是合成数据
通常认为,合成数据是指基于计算机模拟技术或算法生成的虚拟数据,合成数据的使用往往是为了在训练中进行数据增强。由于其便捷且廉价,在实践中被大量采用,同时,由于其保真度及可控性等问题,也使得合成数据的使用存在大量的争议。
使用合成数据的优劣
合成数据是廉价的。合成数据最初就是为了增强、扩展数据,提高数据集整体质量而使用的。通过各类方法可以在短期内合成大量的数据,以用于人工智能的训练。并且,大多数合成数据在产生时就带有一部分标签,因而可以节省大量的人工标记的成本。
另外,在理论上,合成数据可以填补真实数据中存在的潜在偏差和不平衡性。收集到的真实数据由于收集渠道较少、缺少罕见案例数据等原因无法全面地反映现实世界。使用合成数据可以填补一些真实数据缺少的场景,使得数据集中的数据更加具有多样性。
此外,合成数据在隐私保护方面也表现出了它的优越性。理论上,合成数据可以模拟真实数据集中的特征分布,而不模拟其中的真实个人信息数据。从而实现对真实数据集的个人信息的去标识化。
虽然,合成数据有上述的优点,但是这些优点也伴随着缺点。
考虑到合成数据对真实数据的模拟,是存在一定偏差的。这种偏差在AI模型训练过程中,每次迭代都有可能会被保留下来,并且随着迭代次数的增加而进一步扩大,导致合成数据集和原始真实数据的差距越来越大。最后的结果就是导致AI模型的“崩溃”。
而在隐私保护方面,对真实数据中的个人信息数据过度隐藏,可能会影响AI模型最终的质量。个人信息数据中的特征是包含在了数据集整体的特征分布中的,进而个人信息数据特征是会影响模型最终的生成质量的。而由于生成式模型具有的黑盒部分,研发并不能很好地分离出哪些特征是模型预测生成所必须的。因而在合成数据使用的时候,需要更好地平衡真实性和隐私保护。
合成数据的常见方法
1.基于机械规则的合成
早期使用的扩展数据的方法一般是在原始数据上,基于机械规则产生新的数据。例如,对图片进行各个角度的翻转及不同程度的锐化,以增加某个标签下标签的多样性,提供模型在各种情况下的识别率。由于其便捷且廉价,目前在实际研发中依然被采用。
2.基于概率分布的合成
变分自编码器(VAE)是一种基于深度学习模型实现新样本生成的方法。简单来说,它先学习原始数据的概率分布,再根据概率分布生成看起来很像存在于原始数据集中合成数据。相比于机械规则,这种方法更加具有灵活性。
3.基于博弈提高的合成
生成式对抗网络(GAN)是通过博弈的方式提高合成数据质量的方法。它是由一个生成模型和一个判别模型所组成。生成模型做的是名词解释,需要生成符合定义(概率)的数据。判别模型则做的是选择题或者判断题,对生成模型的答案进行判分,根据判分的结果反馈给生成模型,或者是否最终输出该条合成数据。
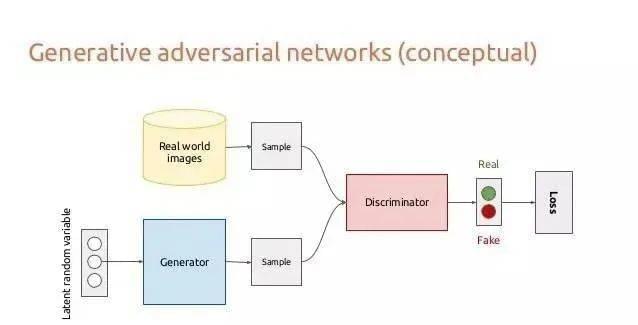
GAN结构示意图
合成数据的规范使用
为了尽量避免使用合成数据所带来的风险,消弭合成数据带来的偏差和错误。可以考虑从使用目的、训练阶段、数据质量三个维度对合成数据的产生和使用进行规范。
1.根据合成数据使用的目的,来确定应该如何保留真实数据样本的概率分布
虽然合成数据需要依赖于真实数据而产生,但是在真实数据本身存在偏见、错误观点的情况下,合成数据又是为了消弭这种偏见和错误而使用的时候,保留真实数据的概率分布会将真实数据中带有的偏见和错误带给合成数据,这不符合合成数据使用的目的。当合成数据的使用是为了保护个人信息时,则应尽量保留其原始真实数据的概率分布。如果多个目的同时存在时,可以对不同的合成数据集进行标记,并做好数据集的隔离。
2.在合成数据集中适当补充少量的异常值
合成数据在生成时为了追求数据质量,往往会删除掉原始数据中的离群值和异常值。虽然这些离群值和异常值往往在数据标注时也会被删除,但是在现有技术下,它们是模型对现实世界的反馈建模所必不可少的信息。让模型知道什么是异常,它可能拒绝出现异常。异常值的存在可以提高人工智能模型的可靠性。
3.采用数据质量更高的合成数据和性能更高的生成方法
目前,大部分合成数据的产生还是要依赖于真实数据集的,同时,人工智能模型对真实数据的建模或多或少都是有损耗的。因此,合成数据的质量上限取决于原始真实数据的质量,真实数据集质量越高,合成数据集的质量就会越高。
4.限制使用合成数据的训练阶段
生成式模型的训练范式中,一般分为预训练和微调训练。预训练多采用的是无监督学习方法,目的是获得具有更高通用性的基座模型,这个阶段不建议使用合成数据,避免合成数据对模型底层层级造成影响,导致纠正的成本和难度加大。
5.限制使用合成数据的训练轮次
目前的研究表明,多轮使用合成数据训练可能会导致模型性能的退化,甚至崩溃。这种退化是在每轮训练中积累的,那么限制合成数据的训练轮次,仅训练少数几轮,防止合成数据中的“有害数据”进一步扩大污染到整个模型。
6.对合成数据进行一定程度的人工干预和标注
合成数据只是对数据集的增强和扩展,其并不能代替数据标注这一环节。值得一提的是,OpenAI采用的“从人类反馈中进行强化学习”(RLHF)的训练范式,通过人工对合成数据的评价排名的方式,并让模型学习这种排名的判别标准。在使用合成数据进行多轮训练中,模型不仅没有发生“退化”,还增强了对人类语言习惯的模仿能力和价值观对齐。
总之,合成数据的使用已经是不可阻挡的趋势,并且合成数据的使用利大于弊。因此,应该更为客观地看待合成数据,对它的生成和使用要“大胆假设、小心求证”。
作者简介
唐简捷:广东财经大学法律硕士,某知名法律科技公司+法律AI产品合规研究员,曾任国内头部运营商法务主管,善于在法律合规中应用AI技术、测试技术、加密技术,曾参与数字广东粤商通、中盾安信(公安一所)、中国电信、某省厅信息系统等多个数据安全与合规项目。
陈焕:北京市隆安(广州)律师事务所律师、隆安湾区人工智能法律研究中心主任、隆安广州数字经济部副部长、国家工业信息安全发展研究中心《生成式人工智能数据应用合规指南》团体标准起草人。
本文来自微信公众号:AI合规圈(ID:gh_344b08562741),作者:唐简捷、陈焕