
如果问当下最强的 AI 助手是哪个?那毋庸置疑,绝对是 ChatGPT。
前不久 ChatGPT 猝不及防地崩了,直接在网上炸出一大批重度用户。靠它完成作业的学生党,一时之间面对论文无从下笔,靠它“续命”的打工人更是连班都不想上了。
今年以来,ChatGPT 每隔一段时间就会“暴毙”,号称其最强平替的 Claude 或许是你最可靠的备选方案。
上下文翻倍,Claude 2.1 大更新
恰巧,近日 Claude 宣布了一波大更新。以往 Claude 能处理的上下文只有 10 万 token(token 是文本处理中的最小单位,如单词或短语),现在 Claude 2.1 Pro 版能处理高达 200K 上下文。
Anthropic 官方表示,200K 上下文约等于 150000 个单词或 500 页文本,这意味着你可以上传代码库、财务报表或长篇文学作品,供 Claude 进行总结、问答、预测趋势、比较和对比多个文档。
那它能处理汉语的能力有多强呢?我们可以以此前饱受争议的 Yi-34B 做个简单说明。同样是发布支持 200K 超长上下文窗口版本, Yi-34B 可以处理约 40 万汉字超长文本输入,约等于一本《儒林外史》的长度。
在语言模型上,长上下文能够提供更精确的用法和含义,有助于消除歧义,帮助模型生成连贯、准确度的文本,比如“苹果”一词出现在“采摘水果”或“新款 iPhone”上,含义就完全迥异。
值得一提的是,在 GPT-4 尚未恢复实时联网功能之前,免费的 Claude 2.0 就已经能够实时访问网页链接并总结网页内容,即使到了现在,也是 GPT-3.5 所不具备的优点。
免费版 Claude 还能读取、分析和总结你上传的文档,哪怕碰上“打钱”的 GPT-4,Claude 处理文档的表现也丝毫不虚。
我们同时给当下网页版的 Claude 和 GPT-4“喂”了一份 90 页的 VR 产业报告,并询问同样的问题。


二者的反应速度没有拉开差距,但免费版 Claude 的回复反而更流畅,且答案的质量也略高,而 GPT-4 的检索功能还会因为分页和视图受到限制,相当不“灵性”。


检索只是“小儿戏”,作为提高学习或工作效率的工具,我们需要的是更“聪明”的模型。当我让它们分析 VR 行业五年后的变化格局,虽然表达的观点都差不多,但 Claude 以富有逻辑的分点作答取胜。


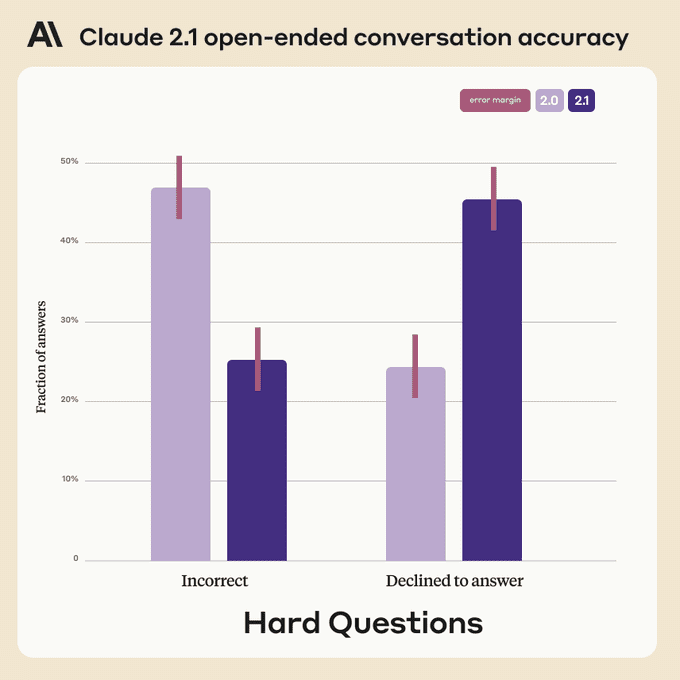
答是能答得上来,能不能答对才是关键。过去一年里,我们目睹不少被大模型“满嘴跑火车”坑了的悲伤案例。Anthropic 称 Claude 2.1 的虚假或幻觉类陈述减少了 2 倍,但它并没有给出明确的数据,以至于英伟达科学家 Jim Fan 发出质疑:“最简单实现 0% 幻觉的解决方案就是拒绝回答每一个问题。”
Anthropic 还设计了很多陷阱问题来检验 Claude 2.1 的诚实度。多轮结果表明,遇到知识的盲区,Claude 2.1 更倾向于不确定的表达,而不是生造似是而非的回答来欺骗用户。
简单点理解就是,假如 Claude 2.1 的知识图谱里没有“广东的省会不是哈尔滨”这样的储备,它会诚恳地说“我不确定广东的省会是不是哈尔滨”,而不是言之凿凿地表示“广东的省会是哈尔滨”。在 Claude 看来,这也是它相较于 ChatGPT 的优点。

Claude Pro 的订阅费用约为 20 美元,使用次数达到免费版的五倍,普通用户可以发送的消息数量将根据消息的长度有所不同。还剩 10 条消息时,Claude 就会发出提醒。
假设你的对话长度约为 200 个英语句子,每句 15~20 个单词,那么你每 8 小时至少能发送 100 条消息。若你上传了像《了不起的盖茨比》这样大的文档,那么在接下来的 8 小时里你可能只能发送 20 条消息。
除了普通用户,Claude 2.1 还贴心地根据开发者的需求,上线了一项名为“工具使用”的测试版功能,允许开发者将 Claude 集成到用户已有的流程、产品和 API 中。

也就是说,Claude 2.1 可以调用开发者自定义的程序函数或使用第三方服务提供的 API 接口,可以向搜索引擎查询信息以回答问题,连接私有数据库,从数据库检索信息。
你可以定义一组工具供 Claude 使用并指定请求。然后 Claude 将决定需要哪种工具来完成任务并代表他们执行操作,比如使用计算器进行复杂的数值推理,将自然语言请求转换为结构化 API 调用等。
Anthropic 也作出了一系列改进来更好地服务 Claude API 的开发者,详情如下:
开发者控制台优化体验和用户界面,使基于 Claude API 的开发更便捷。
更容易测试新的 prompt(输入提示或问题),有利于模型的持续改进。
让开发者像在沙盒环境中迭代试错不同的 prompt。
可以为不同的项目创建多个 prompt 并快速切换。
prompt 的修改会自动保存下来,方便回溯。
支持生成代码集成到 SDK 中,应用到实际项目中。
此外,Claude 2.1 还引入了“系统提示”功能,这是一种向 Claude 提供上下文和指令的方式,能够让 Claude 在角色扮演时更稳定地维持人设,同时对话中又不失个性和创造力。当然,不同于简单 Prompt 的应用,该功能主要是面向开发者和高级用户设计的,是在 API 接口使用的,而不是在网页端使用。
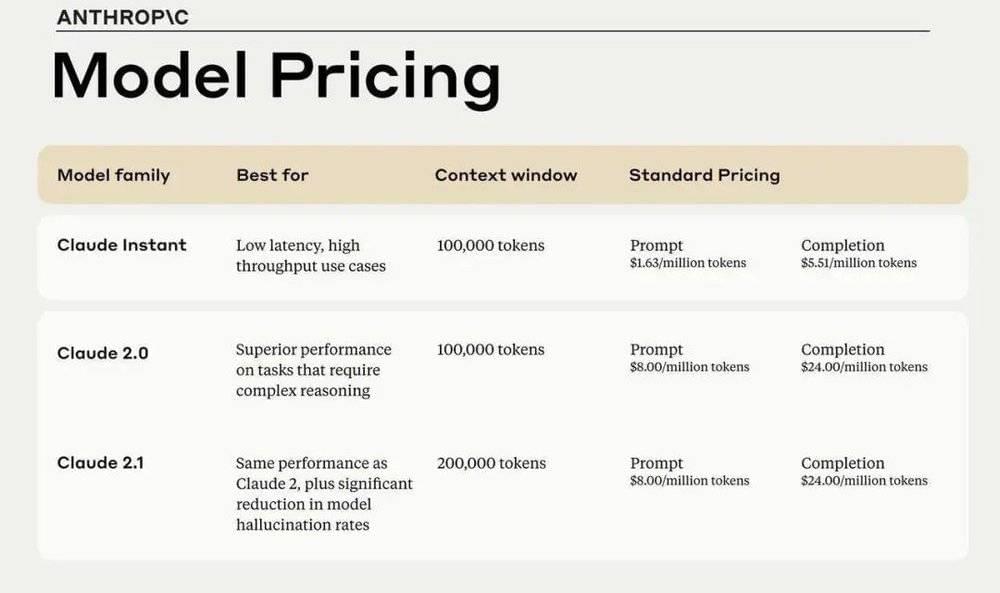
和 Claude 2.0 一样,Claude 2.1 每输入 100 万 token 需要花费 8 美元,比 GPT-4 Turbo 便宜了 2 美元,输出为 24 美元,比 GPT-4 Turbo 便宜了 6 美元。适用于低延迟、高吞吐量的 Claude Instant 版本每输入 100 万 token 需要收费 1.63 美元,输出为 5.51 美元。
ChatGPT 杀手还是平替?
就目前而言,虽然 Claude 2.1 表现很强悍,但仍只能充当 ChatGPT 宕机的替代品,想要颠覆 ChatGPT 还有很长的路要走。打个不太严谨的比方,Claude 2.1 就像是丐版的 GPT-4。

以 Claude 2.1 Pro 最擅长的 200K 为例,尽管 Claude 2.1 Pro 理论处理能力上要比 128K 的 GPT-4 Turbo 更强,但实际结果显示,在需要回忆和准确理解上下文的能力上,Claude 2.1 Pro 还是远逊色于 GPT-4 Turbo。
OpenAI 开发者大会之后,网友 Greg Kamradt 曾对 GPT-4-128K 的上下文回忆能力进行了测试。通过使用 Paul Graham(美国著名程序员) 的 218 篇文章凑够了 128K 的文本量,他在这些文章的不同位置(从文章顶端 0% 到底部 100%)随机插入一个事实语句:“在阳光明媚的日子里,在多洛雷斯公园吃三明治是在旧金山的最佳活动。”
然后他让 GPT-4 Turbo 模型检索这个事实语句,并回答有关这个事实语句的相关问题,最后采用业界常用的 LangChain AI 评估方法对给出的答案进行评估。
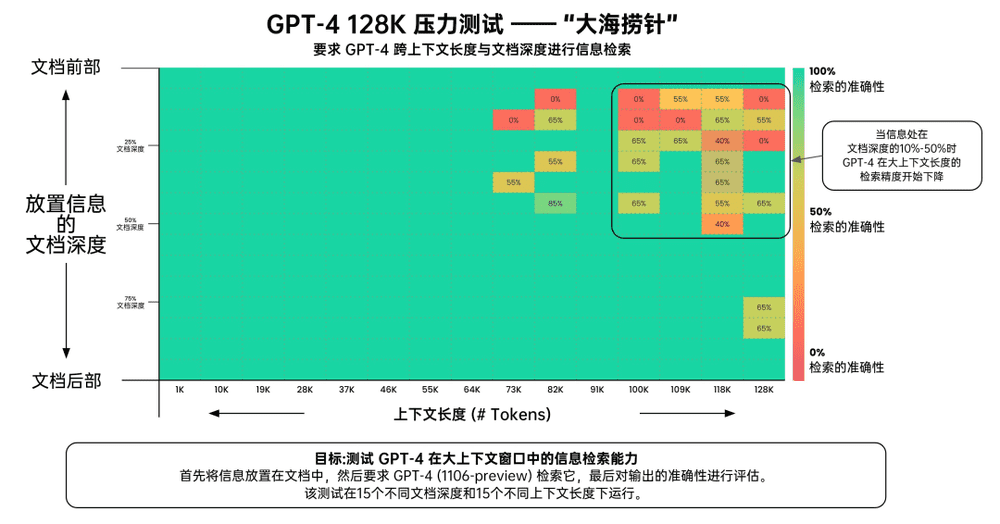
绿色代表更高的检索准确度,红色则代表更低的检索准确度 图片来自:@LatentSpace2000
评估结果如上图,GPT-4 Turbo 可以在 73K token 长度内保持较高的记忆准确率。倘若信息位于文档开头,无论上下文有多长,它总能检索到。只有当需要回忆的信息位于文档的 10%~50% 区间时,GPT-4 Turbo 的准确率才开始下降。
作为对比,该网友还提前要到了 Claude 2.1 Pro 的内测资格,并同样做了“大海捞针”的测试。从评估的结果来看,在长达 20 万 token(大约 470 页)的文档中,和 GPT-4 Turbo 一样,Claude 2.1 Pro 文档前部的信息比后部的回忆效果差一些。
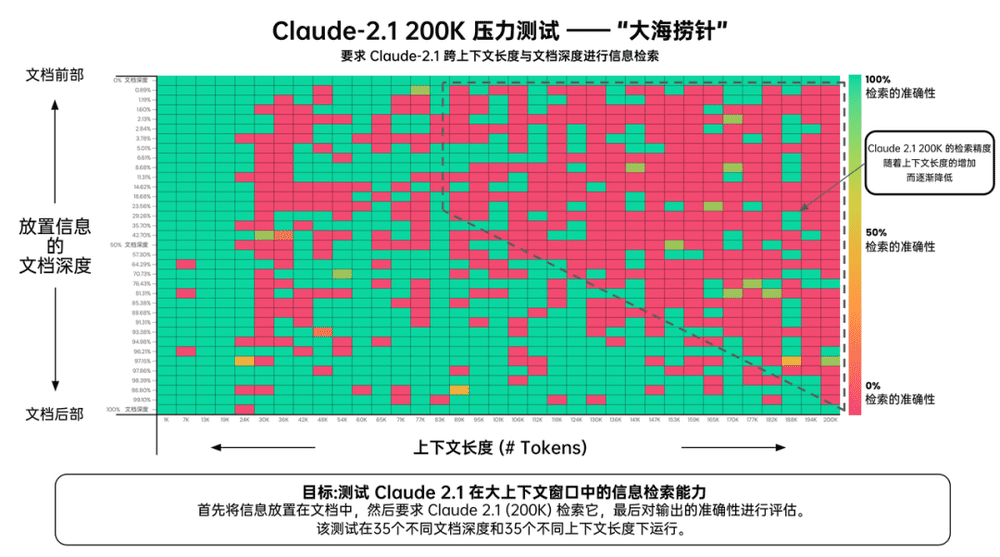
绿色代表更高的检索准确度,红色则代表更低的检索准确度
但 Claude 2.1 Pro 上下文长度效果较好的区间是在 24K 之前,远低于 GPT-4 Turbo 的 73K。超过 24K 后,Claude 2.1 Pro 记忆性能就开始明显下降,90K 后,效果变得更差,出错率更是大幅度上升。
可以看到的是,随着上下文长度的增加,GPT-4 Turbo 和 Claude 2.1 Pro 检测的准确度都在逐渐降低。尽管 Claude 2.1 Pro 的测试覆盖了更宽的上下文长度,但相比更实用的准确度,GPT-4 Turbo 还是 Claude 2.1 Pro 需要追赶的对象。
Claude 或许是免费版中最强的大模型之一。如果你是文字工作者,当 ChatGPT 崩溃,堪比 GPT-3.8 的 Claude 能够解决你的燃眉之急,甚至表现得要更好。
但个性化的 GPTs、轻松生图的 DALL·E 3,语音交流等功能依然是 ChatGPT 不可多得的护城河。在强大的 GPT-4 Turbo 面前,升级后的 Claude 2.1 Pro 版本也得败下阵来。
最后放上 Claude 的体验链接:https://claude.ai/login,若 ChatGPT 再次崩了,放轻松,起码你还有 Claude。
本文来自微信公众号:APPSO (ID:appsolution),作者:莫崇宇