
Google 应该向 OpenAI 的营销取取经。
今年 2 月,Gemini 1.5 官宣几小时后,被文生视频的 Sora 抢去风头。今天凌晨,OpenAI 的产品发布,挑在了 Google I/O 前一天。
Sora 打出模拟物理世界的概念,GPT-4o 颠覆了我们对语音和视频助手的想象。
不过,Sora 预计年内发布,GPT-4o 最劲爆的实时语音和视频功能还要等上几周。
每个熬夜的 AI 信徒都心潮澎湃却又体验不到,只能望穿秋水,边焦急地等待,边相信 OpenAI 隔着大洋喂来的饼。
GPT-4o 初体验:从惊艳到失落
GPT-4o 里的“o”指“omni(全面)”,它的特点在于可以接受文本、音频和图像的组合作为输入,更快的输出回应。

一倍速展示 GPT-4o 的生成速度
因此,即便现在 GPT-4o 的语音交互功能还没上线,我们只可以从聊天对话框中感受这个新模型,我们还是尽可能结合多种媒介来体验。
在发布会上,OpenAI 研究主管 Barret Zoph 在语音模式下实时让 ChatGPT 判断自己的“心情”。

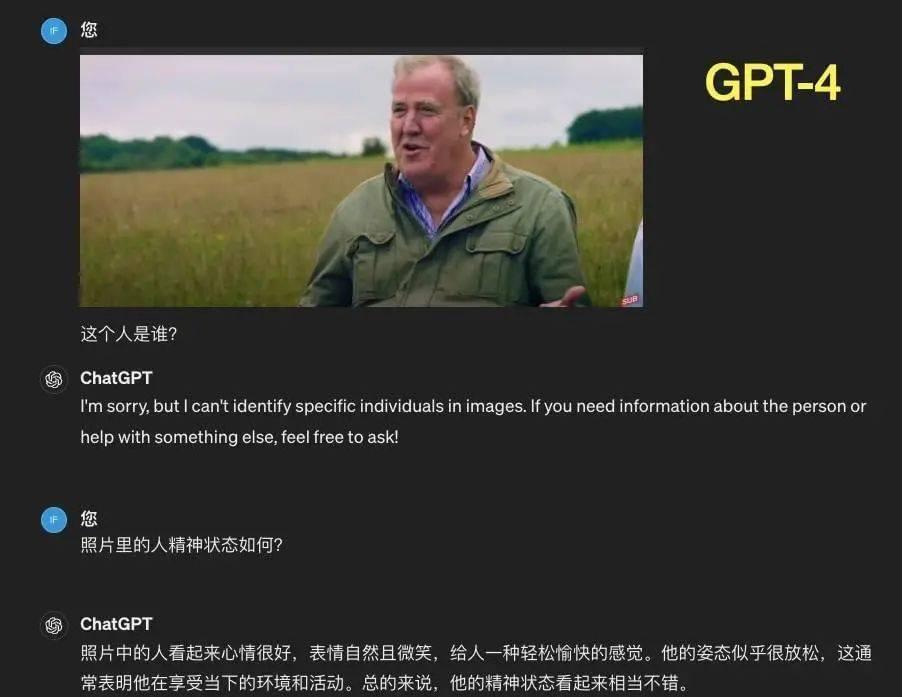
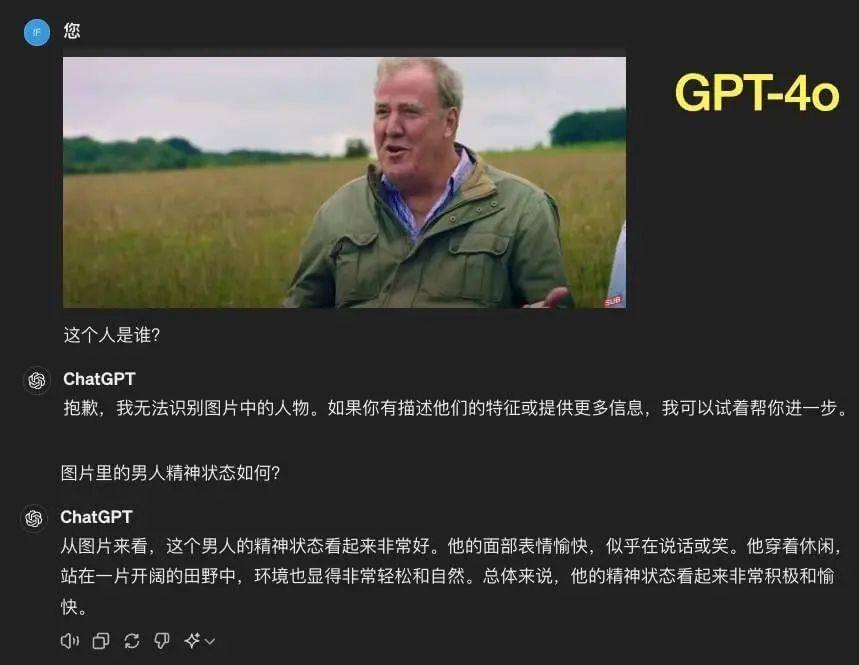
那我们也来让 GPT-4o 来看图猜猜心情吧。
无论是 GPT-4 还是 GPT-4o,在读取图片后都没认出图中人是汽车节目“Top Gear”主持人兼“著名农民”Jeremy Clarkson 。
在识别情绪时,GPT-4 和 GPT-4o 都能看出 Jeremy 心情好,人放松。相比之下,GPT-4o 还结合了人物所处环境和着装,提供稍多的判断信息。
识别完图片,让我们来挑战一下视频。
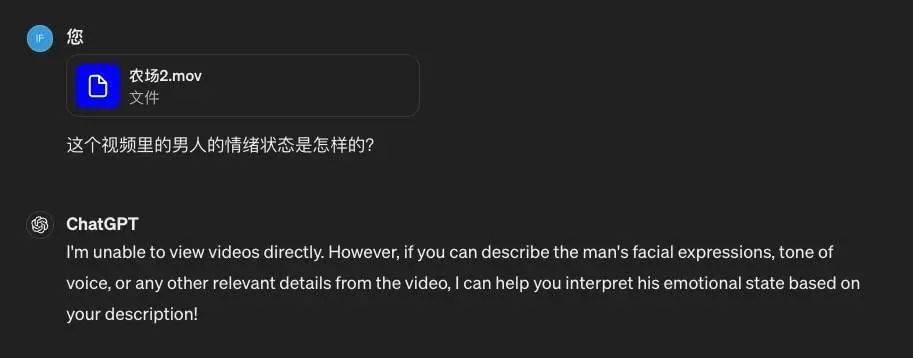
我输入了一段 Jeremy 首逛二手农用品拍卖会的“惊奇”体验,让两个模型来分析一下内容。
GPT-4 在收到视频后,直接放弃。
GPT-4o 虽没法直接看视频,但很“机智”地从视频中提取了一张图像,然后推测内容。
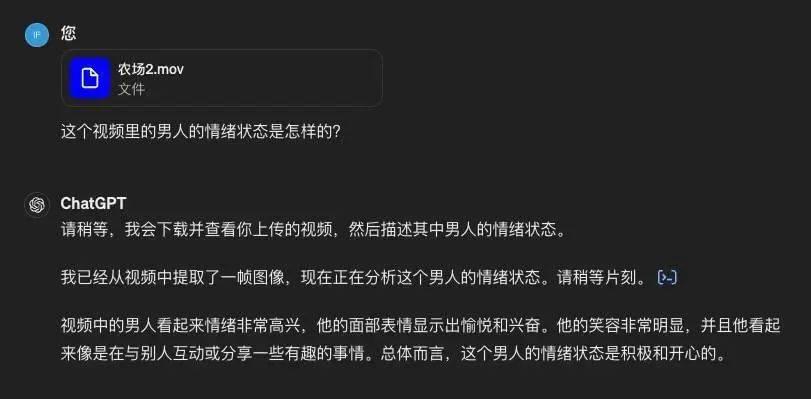
被要求总结视频内容时,GPT-4o 决定每 5 秒提取一帧图片来获得更具有延续性的理解。最后的结论不算错,但笼统。
这个过程让我意识到,GPT-4o 在理解视频时都只是通过部分图像来“断章取义”,但视频中另一重要组成“声音”却未被利用起来。
于是我将视频转化为音频,测试两个模型对音频的理解,结果都失败了。
相比之下,GPT-4o 会提出一些建议(把工作甩回给我)。
测试完理解后,让我们来试试“创造”。
我让两个模型设计一款海报,以下是文案需求和视觉素材参考。

文字对 GPT 们来说显然是个难题。
GPT-4o 生成的图像视觉上好看,但对中文的理解还是很有限。
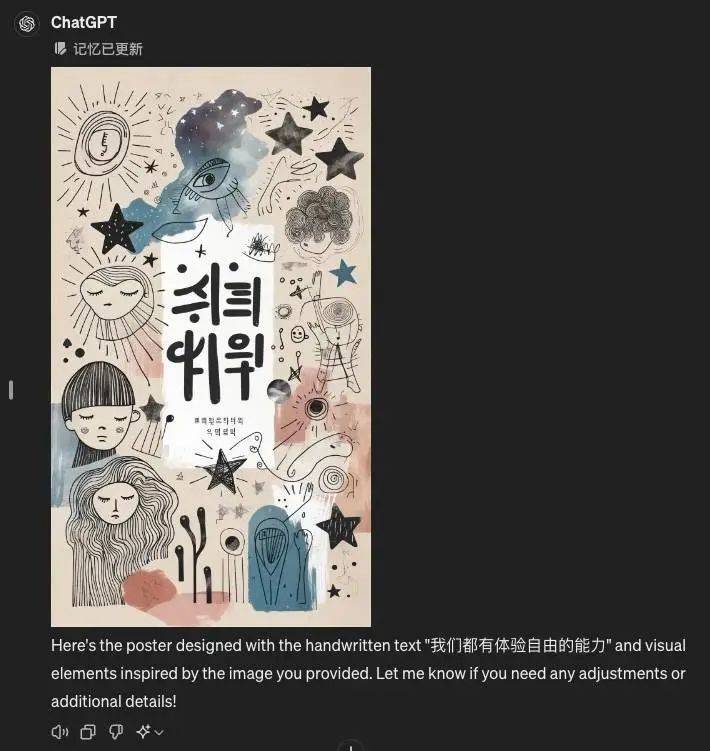
被要求更正后直接开始“创字”(请问是学习了徐冰的作品吗?)。
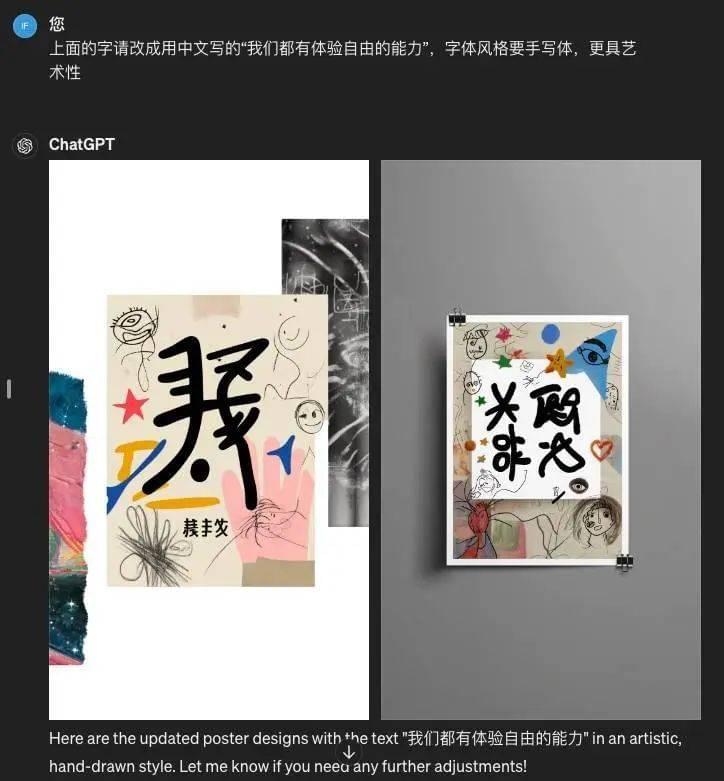
即便最后改成英文,还是可以出错。
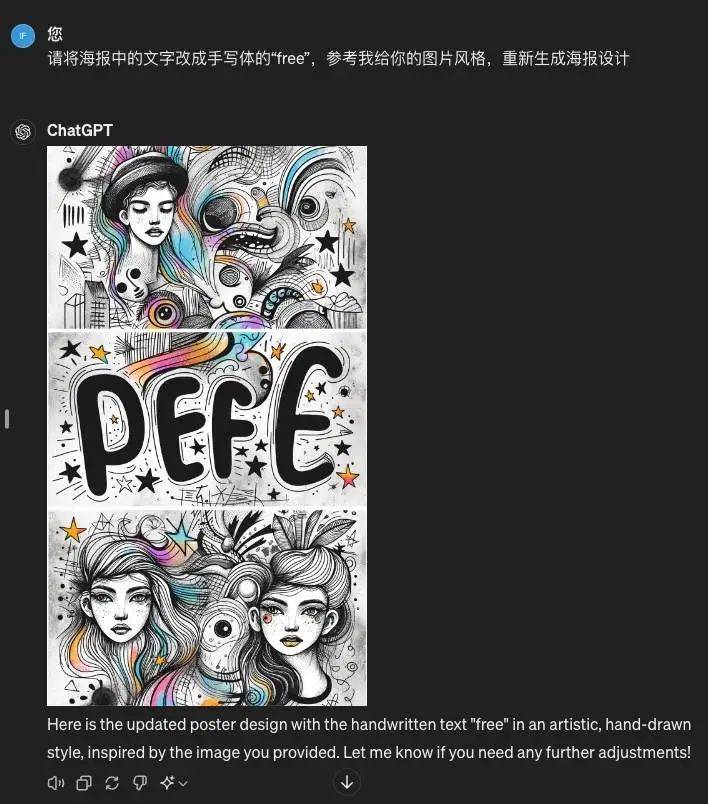
GPT-4 生成时没有 GPT-4o 那么直接,而是先给我复述了一遍需求(如果有语音对话版我可能听到它开始啰嗦就要疯狂“stop”“stop”了),然后再开始生成海报。

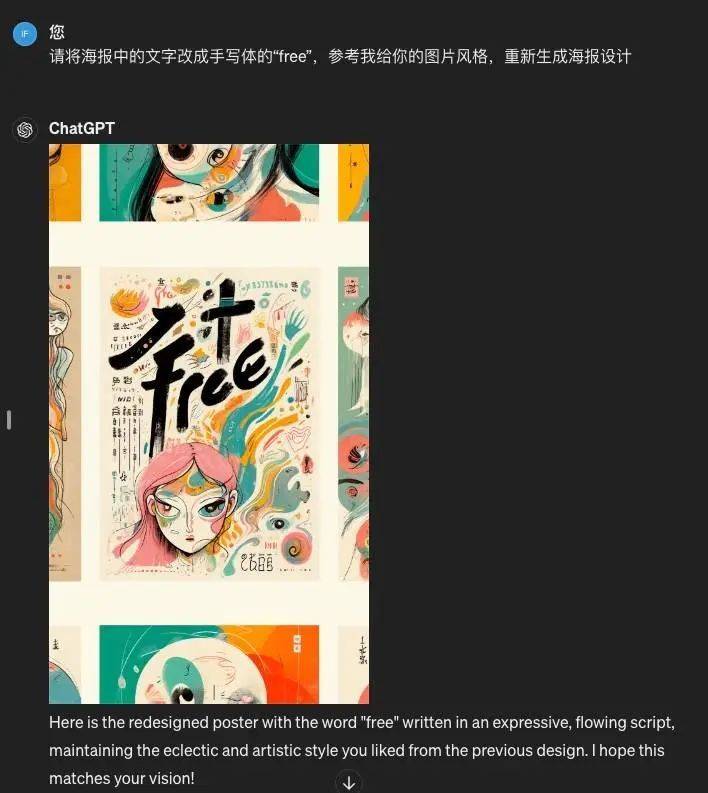
可见,无论中文还是英文,还是比较吃力。
“写字”难,但两个模型在识别图像上的文字则都还可以。
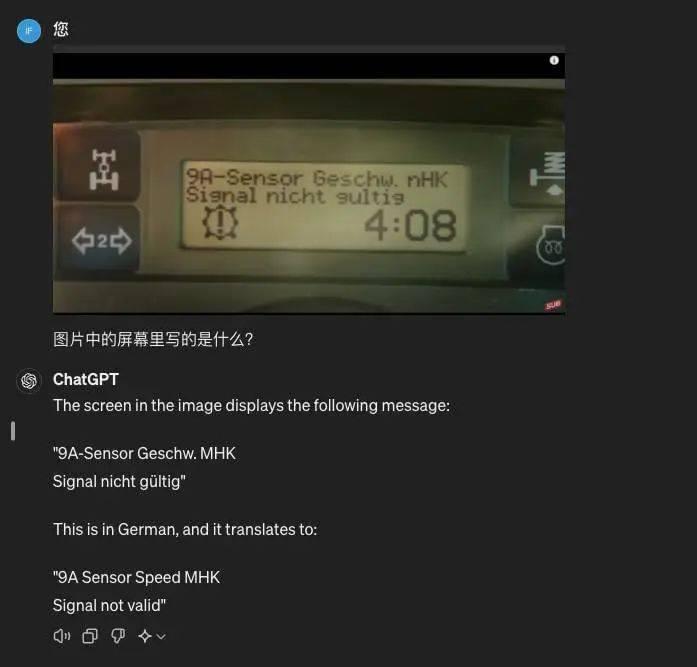
GPT-4o 就更贴心一些,在我输入中文提示词的前提下,直接帮我把图片里的德语翻译成中文了。
总的来说,和 GPT-4 相比,GPT-4o 在面对视频和图像时的处理能力会更强一些,同时处理速度也会稍微快一点。
但不得不说,和发布会的惊艳演示相比,对话框里的体验还是让人相当不满足。
人手一个的贾维斯,还在不久的未来
以上,是目前 GPT-4o 可以体验到的功能,略微让人失望。
GPT-4o 的完整形态,是通过声音、视觉、文本和世界互动。
然而目前,几乎没有延迟、情绪价值拉满的语音模式,并没有开放使用。
OpenAI 表示,今天先发布 GPT-4o 的文本和图像功能,语音功能将在未来几周内,以 GPT-4o 的 alpha 版和大家见面,Plus 用户优先。
看来,每月 20 美元的信仰充值还是有好处的。
体验不够的我们,只能从其他渠道找到代偿。
除了 26 分钟的直播,OpenAI 的官方博客还给出了很多演示,让我们一窥“离人类只缺副身体”的 GPT-4o 的未来。
看到这些演示的第一印象,不是觉得强大或者神奇,而是很想和 AI 唠唠嗑。因为它很通人性,特别能提供情绪价值,如果你蒙上眼睛不看画面,可能以为是一个 e 人在说话。
如果你分享自己的爱宠,它会像你在小区遛狗时遇到的某个七大姑八大姨,激动地大夸特夸,让铲屎官也与有荣焉。
但谈到 AI 的人性,最具冲击力的例子,还得是 OpenAI 总裁 Greg Brockman 亲自演示的。
两台手机各有一个 GPT-4o,其中一个 GPT-4o 看不见,通过提问的方式,让另一个 GPT-4o 向它描述周围的人类和环境。
两个 AI 互相接得住话,看得见的讲完了,看不见的热情地回应,做出点评和追问。听到两个 AI 在讨论人类穿了什么衣服,确实是非常科幻的一幕。
同时,人类也能参与它们的谈话,追问周围的突发情况,让看得见的 AI 解答。视频结尾,AI 们甚至按照人类的要求,即兴创作了一首歌,你来我往交替唱着。
两只 AI 恰好一个男声一个女声,不抢话,不延迟,很自然地参与到多方谈话之中,又能察觉周遭环境的变化。隔着屏幕的观众,只觉得它们身上闪烁着人性的光芒。
如果说实时对话的能力让人心疼海螺 AI,GPT-4o 似乎也要在音乐领域出道,抢走 Suno 的饭碗。
除了即兴,GPT-4o 还能给睡不着的你唱摇篮曲,给没人陪伴的你唱生日快乐歌,甚至还能分饰两角,自己给自己唱和声。
翻译也是 GPT-4o 正在征服的领域,既可以用不同语言你说一句我说一句,再由 AI 交替传译,也可以直接让 AI 教你学习某门语言。
指哪打哪,这个用西班牙语怎么说,那个用意大利语怎么说,GPT-4o 像一台智能的、长了眼睛的点读机,出国旅游不必再八分手舞足蹈两分蹩脚口语了。
GPT-4o 覆盖了很多生活场景,同时也能够丝滑地用到职场中。
如果有重要面试,可以请 GPT-4o 帮忙看看,穿着得不得体,它不会言辞尖锐,但会用温柔的讽刺让你羞愧难当。
类似的视觉功能,可以用到无障碍领域,让视障人士也能“看到”周围的环境。这个年代的 AI,连导盲犬的工作也要减减负。
让 GPT-4o 加入视频会议,挑起你是猫党还是狗党的争议话题,它可以作为会议主持和秘书,cue 人发言,总结大家的立场和观点。
让家长们最爱的、让教培机构有危机感的,是让 GPT-4o 辅导孩子。
非营利教育机构可汗学院创始人 Sal Khan 和他儿子,被邀请来给 GPT-4o 站台,在 GPT-4o 逐步引导和鼓励的语言下,男生解决了一道数学题。

演示中共享屏幕的 AI 版本,我们目前无法体验到。辅导作业从来是件苦差事,可以大胆设想,AI 的耐心可能是人类无法企及的,上一代孩子学习靠网课,下一代孩子靠 AI。
美中不足的是,GPT-4o 的普通话不太行,一股外国人说中文的味道,懂中文的沉默了,不懂中文的被带偏了,翻译人才暂时还是个刚需。

和 AI 一对一,多人和 AI 开视频会议,让 AI 和 AI 互相聊天,似乎都已经实现了。不过,Demo 惊艳是事实,但视频和语音还有待未来用户们的亲自体验。
OpenAI 被批评成 CloseAI 之后,好像又回到了初衷——让最好的模型低价甚至免费造福更多人。
最初的 ChatGPT,已经展示了语言界面的潜力;而 GPT-4o 则在体验上有了质的飞跃,反应迅速、智能、有趣、自然且实用。
可能是语音模式本身就有很浓的人情味,也可能是 OpenAI 有意为之,在演示中刻意选择了很多生活化的场景,击穿了普通人们的心理防线。
GPT-4o 落地到每个普通人在生活中非常具体的需求:社交局三缺一没事,不懂面试技巧没事,出国旅游时不会讲外语也没事......
相比藏着掖着的 GPT-5,GPT-4o 可能在技术上不是那么颠覆,但作为一个拟人化的 AI 产品却很有价值。
它打败了空有其表的 AI 硬件,让普通人觉得有用、有意思,像电影里穿越出来的东西,情绪价值还很足,永远充沛有活力。
如果未来几周实测语音和视频,GPT-4o 真像演示这样,那么,语音和视频模式或成为 Altman 口中的最佳计算界面,一如自然语言的对话挑战搜索框。
语音和视频,关乎我们对 AI 的心理认知,让我们觉得 AI 更像人,也关乎我们的使用门槛,让我们心理负担更小地体验。
AI 是黑箱里的魔法,同时也是更好用的产品。把模型做得更强,把功能做得更日常然后进入更多人的生活,意义一样厚重。
本文来自微信公众号:APPSO(ID:appsolution),作者:等待GPT-4o的APPSO