
苹果急了?
据The Information报道,为了加速开发LLM,苹果现在不仅大幅增加了研究经费——每天烧掉数百万美元,还从谷歌挖来了许多工程师。
对此,苹果员工一致认为,他们的Apple GPT大模型能力已经超过了GPT-3.5。
而Siri也要飞升了——只要告诉它,“用最近拍的5张照片创建一个GIF,发给我朋友”,它就会自动执行这一连串操作,行云流水,而我们连手指都不需要点一下。
至于大模型团队的主力,已经被外媒扒出来了——关键角色几乎都来自于谷歌。
这张图,下面要考
生成式AI的大厂之战,苹果必不会缺席。
AI负责人不甘:慢了一步
苹果,本来也有机会成为OpenAI。
四年前,苹果的AI主管John Giannandrea就曾组建了一个团队开发对话式AI,也就是大语言模型。

这一举措当然很有先见之明,但还是晚了一步——去年秋天,OpenAI抢先发布的ChatGPT,已经率先吸引了全世界的注意力。
几位苹果内部工作人员表示,苹果其实并非对大语言模型的繁荣毫无准备,但Giannandrea此前却一再怀疑:AI模型驱动的聊天机器人究竟能有什么用。
现在,苹果显然后悔了——就是花再大代价,也要把大模型做出来。
16人主力,多个团队共同冲刺LLM
这个代价是多大?
Sam Altman曾表示,OpenAI历时数月训练出的地表最强GPT-4,烧了1亿多美元。
相比之下,苹果这个名为Foundational Models的团队虽然只有约16人,但训练模型的预算已经增长到了每天数百万美元。
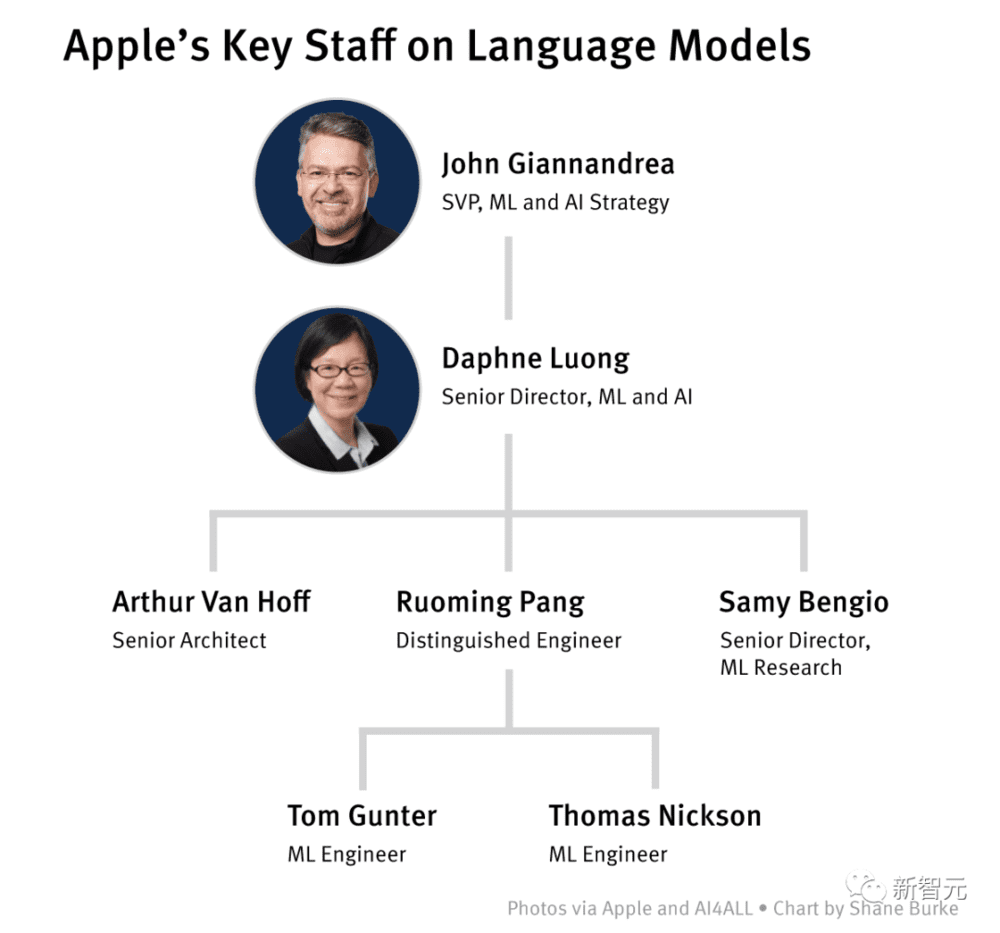
团队由苹果挖来的几名前谷歌工程师组成(还在谷歌时,他们就是Giannandrea的手下),由Ruoming Pang领导,他在谷歌工作了15年后,于2021年选择加入了苹果。

Ruoming Pang
据知情人士透露,该团队扮演的角色,类似于谷歌和Meta的AI实验室——研究人员负责开发AI模型,其他部门负责把模型应用到产品之中。
除此之外,根据近期的一篇研究论文以及LinkedIn上的员工资料,苹果至少还有两个团队,也在开发语言或图像模型。
其中一个视觉团队,致力于开发能够生成“图像、视频或3D场景”的应用。
另一个团队则在进行多模态AI的长期研究——让模型同时识别和生成图像、视频以及文本。

现在,苹果已经开发了多个模型,正在紧锣密鼓地进行内部测试。
Siri即将大升级
在苹果团队看来,目前最先进的模型Ajax GPT(或称Apple GPT),已经超越了GPT-3.5。
此前我们曾报道过,苹果正在暗中开发“Apple GPT”,欲与OpenAI、谷歌打擂台。
有了如此强大的语言模型加持,苹果旗下的一系列产品当然都会迎来一波大升级。
比如下个命令,Siri就会自动创建出个动图,然后发送给手机里的某个人。
并且,苹果还有一个名为Shortcuts的app,可以让用户手动编程,串起不同app的功能。
预计在明年的新版iOS操作系统中,我们应该就能见到这些功能了。
不过,具体要如何在产品中应用LLM,苹果还没有一个定论。
众所周知,苹果一直都在标榜自己对用户隐私的保护,因此在各类功能的实现上,也更倾向于在设备上离线运行,而不是在云服务器上。
据知情人士透露,“Apple GPT”的参数量已经超过了2000亿。想要运行如此庞大的模型,不仅需要强大的算力,还需要足够的储存空间。
显然,这些要求对于一台小小的iPhone来说,实在有些勉强了。
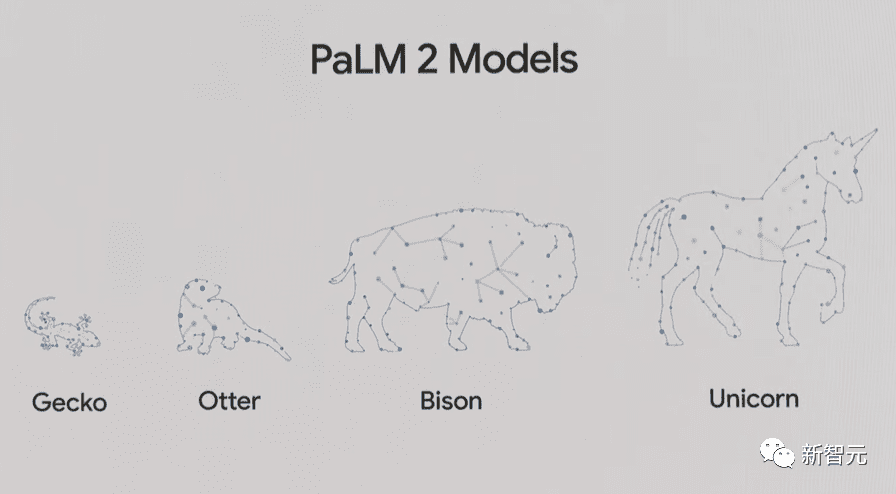
对此,谷歌的PaLM 2倒是开了一个很好的先例——模型被调教成了四种不同的规模,其中的一种就可以在设备上离线使用。
苹果,在变成“另一个谷歌”?
说回团队的事,Giannandrea最初加入苹果,就是为了把更多的AI融进苹果的软件,比如Siri。
在被ChatGPT的辉煌打脸后,他终于打消了对AI聊天机器人的顾虑。
值得庆幸的是,Giannandrea至少有一项决定是明智的——他要让苹果变得更“谷歌”。
因此,苹果的员工被给予了高度的自由和很大的灵活性,来进行各种研究、发表论文。因此,Foundational Models团队才得以存在。
要知道在此前,苹果对此有诸多限制,因而流失了不少人才。

苹果变得更“谷歌”的另一个原因是,2018年Giannandrea加入苹果后,挖来了不少谷歌的骨干工程师和研究者。
另外,他还在苹果内部大力推介谷歌的云服务(包括谷歌开发的TPU芯片)来训练Siri和其他产品的模型。
大牛,是从谷歌挖的
苹果的这支队伍里,可谓人才济济。
Foundational Models的前身,是一个由荷兰计算机科学家Arthur Van Hoff领导的团队。

Van Hoff是Sun Microsystems团队的早期成员,就是这个大名鼎鼎的团队,在上世纪90年代创建了Java。
2019年,Van Hoff加入苹果,当时他负责开发新版Siri(内部代号为Blackbird),但苹果放弃了这个版本。后来,他带领团队开始主攻LLM。
起初,这个团队只有少数几名员工。最出名的是两位来自牛津大学的英国研究员,Tom Gunter和Thomas Nickson,他们负责NLP。

Tom Gunter

Thomas Nickson
2021年,Ruoming Pang加入了苹果,来帮忙训练LLM。
与其他研究员不同,他被特批留在纽约,苹果希望在那里建立一个机器学习团队的前哨站。
Ruoming Pang凭借自己在神经网络方面的研究,赢得了业内广泛的关注。比如神经网络如何与移动电话处理器一起工作,如何使用并行式计算来训练神经网络。

几个月后,苹果挖来前谷歌AI高管Daphne Luong,来监督Van Hoff的团队和Samy Bengio的团队。后者也是苹果在2021年从谷歌挖来的。

Samy Bengio
后来,团队内部似乎发生了一些变动,Pang接管了Foundational Models团队。而Van Hoff在今年开始无限期休假。
不过,根据最新的LinkedIn资料,Van Hoff已于今年8月离职。

Arthur van Hoff
而另外一位曾经的苹果多模态研究团队负责人Jon Shlens,则是在“苹果—谷歌”之间反复横跳。
2012年,Shlens加入谷歌出任高级研究科学家,一做就是11年6个月。
2021年底,他跳槽到了苹果,负责长期开展以多模态学习为重点的机器学习研究。
不到2年时间,Shlens又回到了谷歌。
根据The Information的分析,他在Google DeepMind负责的新团队,和谷歌即将推出的具有多模态功能的Gemini模型,也有着千丝万缕的联系。

Jon Shlens
服务器,也首选谷歌
苹果之所以会招来Pang,也是公司内部越来越清晰地意识到:LLM在机器学习中,很重要。
知情者爆料,在OpenAI于2020年6月发布GPT-3后,苹果机器学习组的员工们就闹起来了,要求公司调拨更多资金,来让他们训练模型。
据悉,为了节省成本,苹果高管历来都是鼓励工程师们使用更便宜的谷歌云计算服务,而不是亚马逊云计算服务。
因为谷歌是Safari浏览器的默认搜索引擎合作商,所以谷歌云服务给苹果的报价也会更低。
当然,合作归合作,苹果从没停止过从谷歌和Meta的AI队伍中挖人。
据统计,自AXLearn于7月上传以来,已有至少十二名加入苹果机器学习团队的成员在GitHub上为项目做出了贡献。其中7人以前曾在谷歌或Meta工作过。
苹果,也会“开源”了?
有趣的是,在Ruoming Pang的影响下,Foundational Models团队竟然在今年7月的时候,悄悄把训练Ajax GPT用的机器学习框架AXLearn给传到了GitHub上。
基于谷歌开源框架JAX以及加速线性代数XLA的AXLearn,可以用于快速训练机器学习模型,并且针对谷歌的TPU进行了优化。

项目地址:https://github.com/apple/axlearn
具体来说,AXLearn采用面向对象的方法来解决构建、迭代和维护模型时出现的软件工程挑战。用户能够从可重复使用的构建模块中组合模型,并与其他库(如Flax和Hugging Face transformers等)集成。
AXLearn除了支持在数千个加速器训练上对具有数百亿参数的模型进行训练外,还支持包括自然语言处理、计算机视觉和语音识别等广泛的应用场景,并包含了训练SOTA模型所需的基线配置。
如果说,我们把苹果的Ajax GPT比作是一座“房子”,那么AXLearn就是“蓝图”,而JAX则是用于绘制这些蓝图的“笔和纸”。但是,苹果并没有公开训练模型所用的数据,也就是“建筑材料”。
当下我们并不清楚苹果公开发布AXLearn的原因,但通常来说是希望其他工程师也可以对其进行改进。
参考资料:https://www.theinformation.com/articles/apple-boosts-spending-to-develop-conversational-ai?rc=epv9gi
本文来自微信公众号:新智元 (ID:AI_era),作者:编辑:Aeneas 好困