
本文来自微信公众号:海外独角兽 (ID:unicornobserver),作者:Dylan Patel,Gerald Wong,编译:Haina、wenli、Cage,编辑:Siqi,原文标题:《GPT-4 “炼丹”指南:MoE、参数量、训练成本和推理的秘密》,头图来自:unsplash
GPT-4 是科学和工程深度结合创新的结果,中间有无数的 tricks,对于外界,如果能了解 GPT-4 的结构就如同获得了最强模型的“炼丹秘方”。这篇内容十分详尽地给出了 GPT-4 的架构、训练和推理的基础设施、参数量、训练数据集、token 数、成本、以及 MoE 模型等参数和信息细节。
Dylan 和 Gerald 认为,OpenAI 之所以不公开 GPT-4 的架构,并不是出于所谓 AI Safety 的考虑,而是因为这个架构很容易被复制;被称为“天才黑客”的 George Hotz 也表达过类似观点,不过,George 认为 GPT-4 由 8 个专家模型的 MoE 构成,每个专家模型的参数量约为 1100 个。
两位作者预计,Google、Meta、Anthropic、Inflection、Character.ai、腾讯、字节跳动、百度等公司在短期内将拥有与 GPT-4 一样甚至更强大的模型能力。即便 GPT-4 的架构“很容易被复制”,但在他们看来 OpenAI 拥有最持久的护城河——最多体量的终端用户、领先的工程人才,以及在模型代际变化中的先发优势。
友情提示:文章中的数据来自于原作者的多方收集和研究,尚未经 OpenAI 证实,而 Dylan Patel 的研究普遍被认为可信度很高,可以作为一篇不错的 GPT-4 深度研究材料参考。此外,我们认为文章中易复制的观点可能有些“标题党”的嫌疑,因为除 OpenAI 和 Google 外,目前擅长复杂 MoE 框架训练和推理的科学家很稀缺,且当前的 GPT-4 也只是初代 MoE,并不是 OpenAI 给出的最终答案,并且过程中的大量经验是其他团队没有的,而这些经验一定也会成为 OpenAI 的独特优势。
以下为本文目录,建议结合要点进行针对性阅读。
01 Overview
02 模型结构
03 数据集
04 并行策略
05 训练成本
06 MoE
07 推理
08 推理的 Infra 与成本
09 多查询注意力机制
10 连续批处理
11 推测解码
12 视觉多模态
01. Overview
OpenAI 的工程设计能力和他们所创造出的东西十分惊艳,但这并不代表这些解决方案是不可超越的。他们的解决方案非常优雅,背后也涉及到了一系列复杂因素的考量和平衡,模型规模的扩大仅仅只是其中的一部分。OpenAI 最持久的护城河来自于三个方面:首先,他们拥有最多的现实世界用户,另外是领先的工程人才,最后是他们在未来的模型开发中很可能继续保持领先优势。
不仅弄清楚 GPT-4 选定某种架构的原因是很有价值,更进一步地,我们还会概述 GPT-4 在 A100 上的训练和推理成本,以及在下一代模型架构中如何使用 H100 进行扩展。
从 GPT-3 到 GPT-4,OpenAI 想要将模型的规模扩大 100 倍,这个过程最核心的自然是成本问题。稠密模型(dense transformers)是 OpenAI GPT-3、Google PaLM、Meta LLaMA、TII Falcon、MosaicML MPT 等普遍使用的模型架构,目前至少有 50 家使用这种架构训练 LLM 的公司,这是一个很好的架构,但它的扩展能力十分有限。
AI Brick Wall 这篇文章中曾讨论过模型的训练成本,当时 GPT-4 还未发布。从训练成本的角度来看,稠密模型(dense transformers)即将面临自己的“AI Brick Wall”,在这篇文章中,我们也提出 OpenAI 正在为 GPT-4 的架构以及各种现有模型的训练成本做出一些上层架构方面的努力。
AI Brick Wall:现阶段的硬件在稠密模型(Dense Transformer)方面已经到达极限,所以不断扩大模型规模到具有一万亿或十万亿参数的模型是不切实际的,并且成本很高。在新一代硬件之前,需要通过各种策略和技术来减少训练成本、提升模型训练效率,从而让模型扩展到更高的参数数量。作者认为这一系列技术将在 2023 年左右实现,有能力参与的公司包括 OpenAI、谷歌、DeepMind、微软和 Nvidia。这些策略中有许多是在 NeurIPS 会议上提出的,很可能会在 AI 应用产生重大影响。
但在过去的 6 个月中,我们意识到训练成本可能是一个无关紧要的问题。虽然花费数百万甚至上亿美元来训练模型听起来很疯狂,但对于科技巨头们来说其实是微不足道的。大模型是一个资本投入项目(Capex line item),而模型规模越大、结果越好,唯一的限制因素反而在于模型规模拓展的同时要人类是否有充足能力和时间来提供反馈、修改模型架构。
Meta 每年在“Metaverse”上投入 160 多亿美元、Google 在新项目的尝试上要花费 100 亿美元左右,Amazon 在 Alexa 上累计投入了 500 多亿美元,而加密货币在“没有价值的东西”上浪费了超过 1000 亿美元。整个社会将花费超过 1000 亿来创建能够训练大规模模型的超级计算机,这些大规模模型可以以各种方式产品化。多个国家和公司将重复进行大模型的训练工作,大模型是新的“太空军备竞赛”。与之前那些“资源浪费”相比,真正的价值将因为人类助理和 Autonomous Agent 的出现在短期内实现。
但在接下来的几年中,Google、Meta 和 OpenAI、Microsoft 等多家公司将投入超过 1000 亿美元搭建一个超级计算机来训练模型。
扩大模型规模更重要的问题,即真正的“AI Brick Wall”,在于推理环节。这里的目标是将训练算力与推理算力分离,所以对于任何将被部署的模型来说,训练超过 DeepMind 的 Chinchilla-optimal 是有意义的。(拾象注:增加训练数据量使模型过度学习,是增加小模型能力、降低推理成本的策略。)这也是为什么要使用稀疏模型架构(sparse model architecture)的原因,这种架构下的推理并不需要激活所有参数。
Chinchilla optimal:来源于 Deepmind 的论文Training Compute-Optimal Large Language Models,表示在有一个固定的 FLOPS 总数情况下,应该使用什么样的模型大小和数据大小来获得最低的损失。
目前,Chinchilla-optimal 是训练侧的最优策略,而用更多的 tokens 进行训练以超越 Chinchilla-optimal 的效果,是推理侧的最优策略。并且由于推理成本占“大头”,大部分公司会选择超过 Chinchilla-optimal 的策略。
推理环节的问题本质是将模型部署到用户和 Agents 的成本太高了。推理成本比训练成本高数倍,而解决这一问题正是 OpenAI 在模型架构和基础设施方面的目标。
在大模型推理方面,特别是稠密模型,模型大小会成为一个多变量问题。On Device AI- Double Edged Sword 这篇文章中曾讨论过边缘计算环境下的情况。简单来说,终端设备永远不可能拥有满足大语言模型实现所需的吞吐量(throughput)和足够内存带宽,即使带宽足够,边缘设备利用硬件计算资源的效率也十分低下。数据中心面临的问题类似。
计算资源的利用率(utilization)对于数据中心和云(Cloud)十分重要。(拾象注:目前业界对 GPU/TPU 利用率的上限在 50% 左右。)NVIDIA 的软件之所以广受称赞,一个重要原因在于在持续推出新一代 GPU 的过程中, NVIDIA 也在不断更新下一代的软件,通过在芯片周围、芯片之间和内存之间实现更智能的数据移动,来推动 FLOPS 利用率的提高。
FLOPS:浮点操作数(Floating Point Operations Per Second)是用来量度计算机运算速度的一个单位。FLOPS 越高,计算机处理问题的能力就越强。GPU 的算力主要来自它所能提供的 FLOPS,GPU 提供越高的 FLOPS,代表它的算力越强。
现阶段, LLM 推理的用例大多是“实时助手(live assistant)”,这意味着它必须达到足够高的吞吐量才能真正对用户有用。拿人类做类比,人类的平均阅读速度为每分钟约 250 字,而有些人可以达到每分钟约 1000 字,对应到模型则意味着每秒钟至少输出 8.33 个 token、最好是每秒 33.33 个 token,才有可能满足所有人类需求。
但由于内存带宽的限制,即使是在最新 NVIDA H100 GPU 服务器上,拥有万亿个参数的稠密模型(dense model)从数学层面也无法达到这个吞吐量。每生成一个 token 都需要把它从内存加载到芯片上,然后这个 token 又被送入 prompt,生成下一个 token。此外,为实现注意力机制的 KV 缓存(KV Cache)也需要额外的带宽。
KV 缓存(KV Cache):采样过程中,Transformer 模型会执行自注意力操作(Self-Attention),为此需要为当前序列中的每个项目(无论是 prompt/context 还是生成的 token)提取键值(Key-Value,KV)向量。这些向量存储在一个矩阵中,通常被称为 KV 缓存或者过去缓存(past cache)。
KV 缓存的作用是为了避免每次采样 token 时重新计算键值向量。利用预先计算好的 K 值和 V 值,可以节省大量计算时间,尽管这会占用一定的存储空间。KV 缓存在 Transformer 模型中扮演着非常重要的角色,能够帮助大幅提高模型的效率和性能。
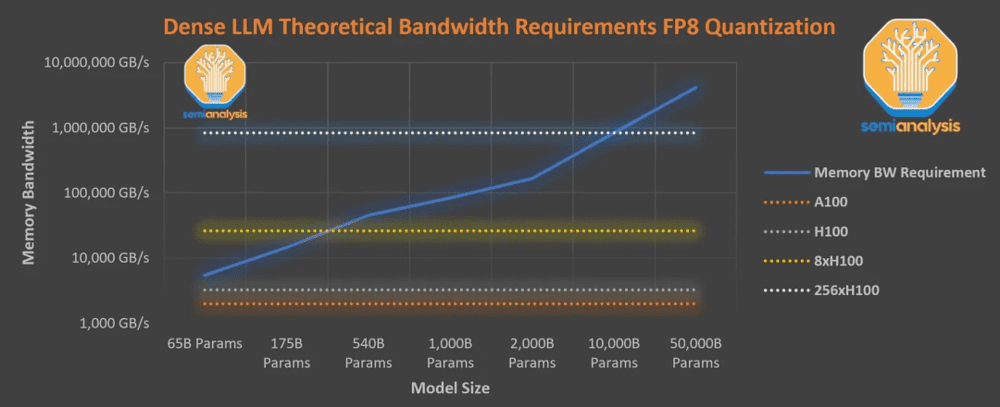
这个图表假设无法融合每个操作是低效率的,注意力机制所需的内存带宽以及硬件开销与参数读取相当。在现实中 ,即使使用 NVIDIA FasterTransformer 这类“优化的”库,整体开销会更大。
上图展示了在足够高的吞吐量情况下,服务于单个用户 LLM 所需的内存带宽。从这张图可以看出:
即便是 8 倍于 H100 的带宽也无法实现以每秒 33.33 个 token 的速度为 1 万亿参数规模的稠密模型提供服务;
此外,8x H100 的 FLOPS 利用率在每秒 20 个 token 时仍低于 5%,这会导致极高的推理成本。
实际上,对于今天的 8-way 张量(tensor)并行的 H100 系统来说,推理约束为约 3000 亿前馈参数。
然而,OpenAI 正在用 A100 以及大于 1 万亿参数的模型实现人类的阅读速度,以每 1000 个 token 0.06 美元的低价广泛提供,之所以能够实现这一点正是因为它的稀疏架构。
接下来,我们会讨论 GPT-4 的模型架构、训练和推理的 infra、参数数量、训练数据集构成、token 数量、层数、并行策略、多模态视觉编码器等一系列不同工程设计背后的考量、实现技术,以及 OpenAI 是如何解决大模型推理过程中的瓶颈的。
02. 模型结构
GPT-4 的规模是 GPT-3 的 10 倍以上,我们估计它有约 1.8 万亿个参数,这些参数分布在 120 个 transformer 层上,作为对比,GPT-3 的参数为大约 1750 亿个。(拾象注:GPT-3 仅有 12 个 transformer 层,层数是 GPT-4 的 1/10。)
为了控制成本,OpenAI 选择使用 MoE 模型。OpenAI 在模型中使用了 16 个 MLP.2 类型的专家,每个专家的参数大约为 1110 亿个。每次前向传递中会调用其中的两个专家模型。
专家混合模型(Mixture-of-Experts,MoE):MoE 模型是一种深度学习架构,该架构,通常由多个专家(Experts)组成,每个专家负责处理输入数据的不同方面,并拥有自己的参数集(也有一些参数,例如 embedding,可以被所有专家共享,即共享参数)。在模型的推理过程中,根据输入数据的不同特征,模型会将输入路由到不同的专家,每个专家根据其参数集处理对应分配到的输入后完成输出,最终输出则是各个专家输出的集成。
MLP:即多层感知机(Multi-Layer Perceptron),MLP 是一种人工神经网络,包含了多个隐藏层,MoE 模型中通常有多个独立的 MLP 专家。
有很多文献中都在讨论如何将每个待处理 token 路由(assign)至某个专家模型的算法,但据说 OpenAI 所采用的这一套算法却相当简单,至少 GPT-4 是这样的。
此外,大约有 550 亿个共享参数被用于注意力机制。
每次前向推理(生成一个 token)仅利用了约 2800 亿个参数和 560 TFLOP,相比之下,如果纯粹使用稠密模型每次前向推理所需的约 18000 亿个参数和 3700 TFLOP 。
03. 数据集
GPT-4 是在约 13 万亿个 tokens 上训练的,考虑到 CommonCrawl RefinedWeb 包含有约 5 万亿个高质量的 tokens,13 万亿这个数字还算合理。作为参考,Deepmind 的 Chinchilla 和 Google 的 PaLM 模型分别是用约 1.4 万亿个 token 和约 0.78 万亿个 token 训练的,PaLM2 据说也是在约 5 万亿个 token 上训练的。
CommonCrawl Refinedweb:
CommonCrawl 是一项非营利项目,旨在构建和维护一个开放、可访问的互联网数据集,可使用网络爬虫技术定期扫描互联网上的网页,并将抓取到的网页和相关的元数据进行整理和存档。CommonCrawl RefinedWeb 是CommonCrawl 通过算法和人类审查后,从原始收集的数据中筛选出高质量文本形成的资料库。
OpenAI 训练 GPT-4 所使用的这个数据集不是 13 万亿个 unique tokens。相反,由于缺乏高质量的 token,该数据集包含了多个 epoch。基于文本的数据有 2 个 epoch,基于代码的数据有 4 个 epoch。(拾象注:这里指部分高质量的文本和代码给模型多次学习过。)这远远没有实现 Chinchilla-optimal(需要在双倍的 token 数上训练模型),这也说明网络上的易获得 token 不足。网络上实际存在的高质量文本 tokens 应该是现如今可利用的 1000 倍,音频和视频类的 token 则要更多,但采集这些 tokens 并不能简单通过网络抓取来实现。比较遗憾的是,我们还没有找到太多关于 OpenAI 的 RLHF 的数据信息。
一个 epoch 指的是将整个训练集(training set)中的所有样本都用于训练模型一次的过程。具体来说,一个 epoch 包括多个训练步骤(training steps),每个训练步骤都是将一个小批量(batch)的样本输入模型中进行训练,并更新模型的参数,以最小化损失函数(loss function)。
如果 epoch 过小,那么模型可能无法充分利用训练集中的信息,导致欠拟合(underfitting),即模型无法很好地拟合训练数据,导致在测试集上的表现不佳。相反的,如果一个 epoch 过大,那么模型可能会过拟合(overfitting),过多地学习训练集中的噪声和局部特征,而忽略了全局特征。
在预训练阶段,上下文长度(seqlen)是 8k。GPT-4 的 32k 上下文版本是在预训练后对 8k 进行微调的基础上实现的。
Batch size 在集群上经过若干天的逐步提升,但到最后,OpenAI 使用了高达 6000 万的 batch size。当然,由于不是每个参数都看到所有参数,这只是每个专家的 batch size 大小为 750 万。
Batch size 指的是每一次迭代 (iteration) 或者前向传递 (forward pass) 的训练样本数量。模型训练中会把数据分批次来训练,Batch size 就表示每一批次中样本的数量。分批训练的好处在于可以规避内存限制、节省用于重复计算中间结果的计算资源。
Batch Size 的大小对模型的训练效果和速度有很大的影响。Batch Size 越大,每次更新参数的计算量就越大,但是训练过程会更加稳定,因为每个 Batch 中的样本可以平均化噪声和不确定性。另一方面,如果 Batch Size 过小,训练过程可能会变得不稳定,并且需要更多的训练步骤才能收敛到最优解。此外,Batch Size 的大小也会受到硬件资源的限制。因此,在实际应用中,选择适当的 Batch Size 是非常重要的。
04. 并行策略
在所有 A100 GPU 上进行并行处理非常重要。
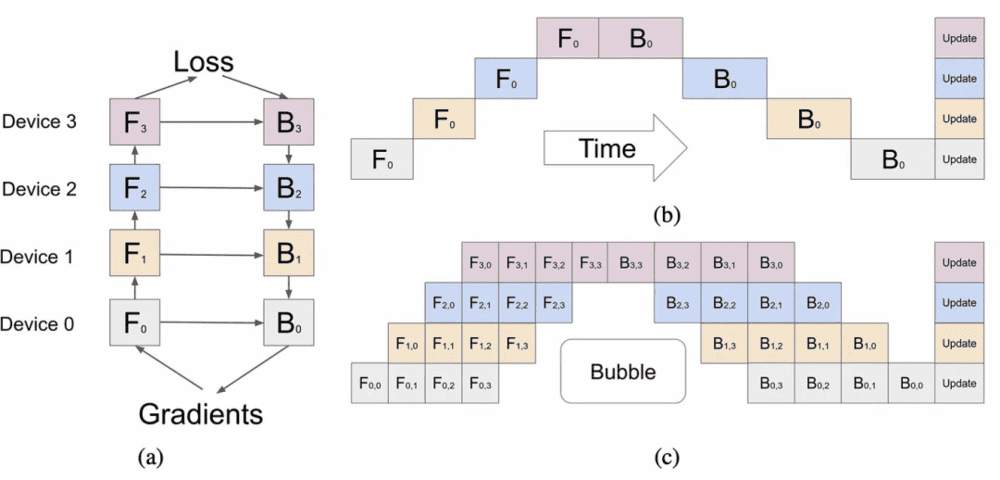
OpenAI 使用了 8 路(8-way)规模的张量并行(Tensor Parallelism),之所以 8 路(8-way)是因为这是 NVLink 的极限。此外,我们还听说 OpenAI 正在使用 15 路(15-way)的流水线并行策略。从理论上讲,考虑数据通信与计算时间,15路(15-way)显得数量过多,但如果他们受限于内存容量,这一点也很合理。
大模型训练中存在几种经典的分布式并行范式,分别为流水线并行(Pipeline Parallelism),数据并行(Data Parallelism)和张量并行(Tensor Parallesim)。微软开源的分布式训练框架 FastSpeed 就融合了这三种并行范式。
如果只是使用流水线并行和张量并行,每个 GPU 上的参数在 FP16 下大约需要 30GB,而一旦考虑到 KV 缓存和 KV 开销,如果 OpenAI 所采用的大部分 GPU 是 40GB 的 A100 的话,这个架构从理论上也是合理的。OpenAI 可能使用了 ZeRo stage 1、块级 FSDP 或混合共享数据并行。
• KV 开销(KV overhead):是指在 KV 存储系统中由于额外的开销而产生的负担。这些开销可能包括存储和管理键值对的元数据、索引结构、数据复制和同步、网络通信等。KV overhead 的增加可能导致性能下降、存储需求增加以及系统复杂性的增加。
• ZeRo Stage 1:ZeRO(Zero Redundancy Optimizer)是指原来每张卡存储完整的优化器状态。若每张卡只存储一部分优化器状态,所有卡的优化器状态共同构成完整的状态,即 Pos (Partition Optimizer States),被称为 ZeRO-stage1。
• Block-level FSDP:是指基于块的全精度动态量化(Full Precision Dynamic Quantization)技术。可以在训练和推理过程中保留更高的模型精度,使模型 inference 的时候成本更低。
之所以不使用全模型 FSDP 的原因可能在于过高的通信成本。虽然 OpenAI 在大多数节点之间有高速网络,但可能不是所有的节点都这样,我们认为至少存在一些集群的连接带宽要比其他集群低得多。
我们暂时还不清楚 OpenAI 是如何在如此高的管道并行性下避免出现巨大的 bubble。很可能他们只是承担了这个成本。
Bubble: 在每个批次(batch)中由于高度的管道并行性而导致的延迟或等待时间。它表示在进行高度并行的计算过程中,由于不同部分的计算速度不同,可能会导致某些部分需要等待其他部分完成计算,从而产生延迟或空闲时间。这种情况下,"bubble" 指的是这些空闲或等待的时间间隔。这句话意味着他们可能只是接受了在计算过程中存在一些空闲时间或延迟。
05. 训练成本
OpenAI 在 GPT-4 的训练中使用了大约 2.15e25 的 FLOPS,在大约 25,000 个 A100 GPU 上进行了 90 到 100 天的训练,这里的算力利用率约为 32% 至 36%。
这种极低的利用率部分是由于大量的故障导致需要重新启动检查点,上文中提到的 bubble 占据了大量成本。
另一个原因是在这么多的 GPU 之间进行 all-reduce 的代价非常高。尤其是如果我们怀疑这个集群实际上是由许多较小的集群组成,并且它们之间的网络连接相对较弱,例如在集群的不同部分之间以 800G/1.6T 的非阻塞方式连接,但这些部分只能以 200G/400G 的速度连接。
all-reduce 是一种并行计算中的通信操作,用于在分布式计算中实现数据的全局归约(global reduction)。在分布式深度学习中,all-reduce 是一种常用的通信操作,用于在多个计算节点之间共享并聚合梯度信息,以便于在训练过程中更新模型参数。
如果他们在 Cloud 上的成本约为每个 A100 每小时 1 美元,单这次训练的成本就达到了约 6300 万美元。这还不包括所有的试验、失败尝试以及数据收集、RLHF、员工等其他费用。如果考虑到这些因素,实际成本还要高得多。此外,还需要考虑到需要有一个团队来完成芯片配置、网络设备以及数据中心,承担资本投入(Capex),并将它们租给你。
目前预训练(pre-training)可以用大约 8192 个 H100 在约 55 天内完成,总费用为 2150 万美元,每个 H100 GPU 的费用为 2 美元/小时。
我们预计到今年年底会有 9 家公司拥有更多的 H100 GPU。可能这些 H100 并不会全部用于模型训练,但那这几家公司一定会拥抱大模型、成为重要参与者。Meta 到今年年底预计将拥有超过 10 万个 H100,其中很大一部分会被部署到自己的数据中心用于推理,不过,他们最大的单个集群将拥有超过 25,000 个 H100 GPU。(拾象注:Meta 的算力资源将使 LLaMA 的能力进化成为开源和私有化部署的重要变量。)许多公司将在今年年底前训练一个能力和 GPT-4 齐平的模型。
06. MoE
MoE 是一种在推理过程中减少参数数量的有效方法,同时它还能增加参数数量,有助于每个训练标记编码更多信息。因为获得足够多的高质量 token 十分困难,所以选择 MoE 架构很必要。因为如果 OpenAI 真的要实现有实现 Chinchilla-Optimal,他们就必须训练两倍于现在的 token 数量。
话虽如此,OpenAI 做出了多种权衡。例如,在推理过程中处理 MoE 非常困难,因为并非模型的每个部分都在生成每个 token 时被使用。这意味着当其他部分被使用时,某些部分可能处于休眠状态。在为用户提供服务时,这会严重影响利用率。
研究人员证明,使用 64 到 128 个专家比使用 16 个专家获得更好的损失结果,但这只是研究结果。减少专家的数量有多个原因。OpenAI 选择 16 个专家的原因之一是专家越多越难泛化,以及更难实现收敛。考虑到如此大规模的训练运行,OpenAI 选择在专家数量上更加保守。
此外,使用较少的专家对推理架构也有帮助。当转向 MoE 推理架构时,会有各种复杂的权衡。让我们从基本的 LLM 推理权衡开始,然后再探讨 OpenAI 面临的问题以及他们所做的选择。
07. 推理
在这一部分,我们首先想指出,我们所接触的每一家 LLM 公司都认为 NVIDIA 的 FasterTransformer 推理库相当糟糕 ,TensorRT 则更严重。一旦没有能力使用 Nvidia 的模板并对其进行修改,就意味着需要从头开始创建自己的解决方案,NVIDIA 需要尽快解决这个问题,来适应 LLM 推理的需求,否则事实上它将成为一个开放工具,可以更容易地添加第三方硬件支持。越来越多的大模型还在涌现,如果 NVIDA 无法在推理中提供软件优势,而且仍然需要手动编写内核,那么 AMD 的 MI300 和其他硬件将拥有一个更大的市场。
LLM 的推理环节有 3 个关键因素,这些因素主要和所使用的芯片数量相关。
1. 延迟(Latency)
模型必须在合理的延迟内做出响应。人们不希望在等待几秒钟后才开始在聊天应用程序中接收输出。输入和输出 token 处理时间会出现波动。
2. 吞吐量(Throughput)
模型必须每秒输出一定数量的 token。人类使用大约每秒 30 个 token,对于其他各种用例,吞吐量可以更低或更高。
3. 利用率(Utilization)
运行模型的硬件必须实现高利用率,否则成本将过高。虽然可以通过更高的延迟和较低的吞吐量将更多的用户请求进行分组,从而实现更高的利用率,但这会增加难度。
LLM 推理主要是为了平衡两个主要因素,即内存带宽和计算量。
简单来说,每个参数都必须被读取与其相关联的是两个 FLOP 。因此,大多数芯片的比例(例如,H100 SXM 只有 3TB/s 的内存带宽,但有 2,000 TFLOP/s FP8)在 batch-size 为 1 的推理中完全不平衡。如果只为一个用户提供服务,即批量大小为 1,则为了每次 token 生成而流式传输每个参数所需的内存带宽会占据推理时间的主导地位,计算时间几乎可以忽略不计。
为了能够将大模型扩展到多个用户,批量大小必须大于 1,多个用户分摊参数读取成本。例如,在批量大小为 256 或 512 时,每个读入的内存字节对应 512 FLOP/s 或 1024 FLOP/s。这个比例更接近 H100 的内存带宽与 FLOPS 之间的比值。有助于实现更高的利用率,但缺点是延迟更高。
很多人认为内存容量是 LLM 推理的主要瓶颈,因为模型的大小可能适合多个芯片,但这个观点可能存在问题。虽然大模型的推理需要多个芯片,并且较高的内存容量导致更少的适配芯片,但实际上更好的做法是使用超过所需容量的芯片,以便将延迟降低,增加吞吐量,并且可以使用更大的批量规模,以不断提高利用率。
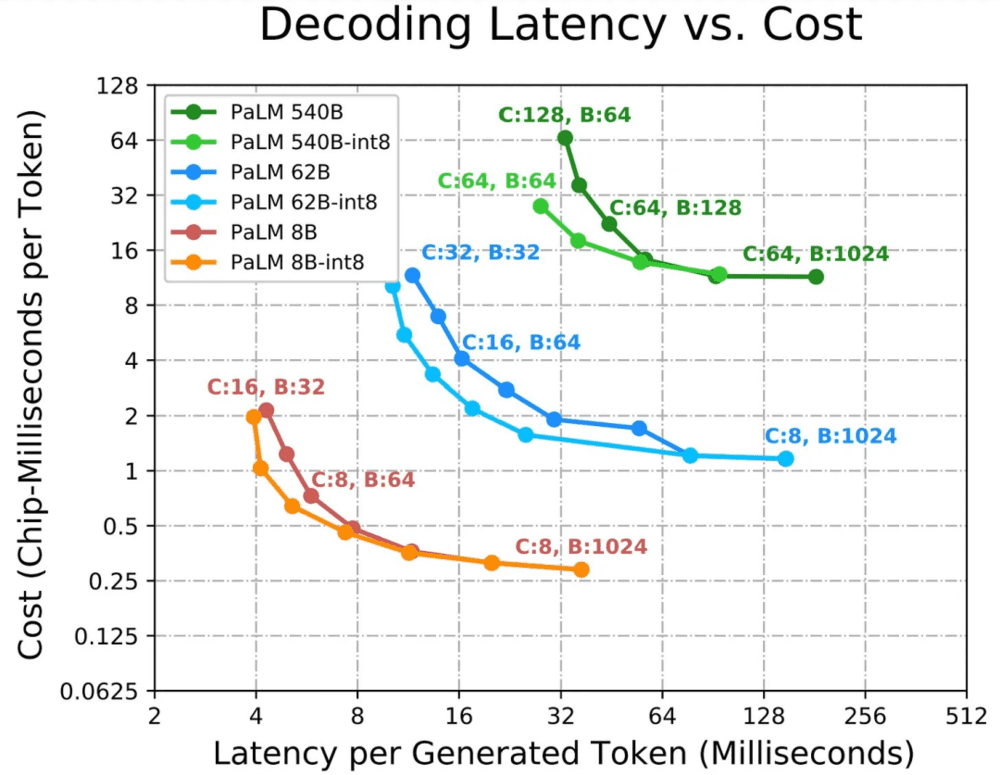
Google 在 PaLM 推理论文中也提到了对上述三个问题的处理。值得注意的是,这是针对 PaLM 类的稠密模型,而不是 GPT4 这类的稀疏模型。
如果一个应用程序需要尽可能低的延迟,我们需要更多的芯片,并以尽可能多的方式对模型进行分割,这样才能有经济效益。较小的批处理量可以实现较低的延迟,但较小的批处理量也会导致较差的 MFU [利用率],导致每个 token 的总成本(以芯片秒数或美元计算)较高。
如果一个应用需要离线推理,并且延迟不是问题,那么主要目标是最大限度地提高每个芯片的吞吐量(即最小化每个 token 的总成本)。增加批处理量是最有效的,因为较大的批处理量通常会带来更好的 MFU [利用率],但是某些对小批处理量无效的分区策略会随着批次处理量的增长而变得有效。
更多的芯片和更大的批次量反而是更便宜的,因为它们提高了利用率,但这也引入了第三个变量,即联网时间(Networking Time)。把模型部署在多个芯片上的方法可以有效解决延迟,但要对利用率做出牺牲。
存储时间的权重加载部分和非注意计算时间都与模型大小成正比,与芯片数量成反比。对于一个给定的分区布局,芯片与芯片之间的通信所需时间随着所用芯片数量的增加而减少得不那么快(或根本不减少), 所以随着芯片数量的增加,它成为一个越来越重要的瓶颈。
我们注意到,随着批处理量和规模的增长,KV 缓存的内存需求量会激增。
如果一个应用程序需要生成具有长注意力上下文(long attention contexts)的文本,就会大大增加推理时间。对于一个具有多头注意力 500B 以上的模型,注意力的 KV 缓存会变得很大:对于批量大小为 512、上下文长度为 2048 的模型,KV 缓存的总量为 3TB, 是模型参数大小的 3 倍。片上存储器(on-chip memory)需要从片外存储器(off-chip memory)中加载这个 KV 缓存,每产生一个 token 就加载一次,在此期间芯片的计算核心基本上是空闲的。
较长的序列长度对内存带宽和内存容量来说特别麻烦。OpenAI 16k 上下文的 GPT-3.5 turbo 和 32k 上下文的 GPT-4 很贵的原因是内存的限制,它们不能采用更大的批次。
较小的批次导致较低的硬件利用率。此外,随着序列长度的增加,KV 缓存会膨胀。KV 缓存不能在用户之间共享,所以需要单独的内存读取,这进一步降低了内存带宽。关于 MQA 的更多信息,请见下文。
08. 推理的 Infra 与成本
Infra
MoE 的架构则让 GPT-4 的推理在延迟、吞吐量和利用率上都面临挑战。因为每个 token 的前向传递可以路由到不同的专家模型,这种情况下要尽可能实现低延迟、高吞吐量和高利用率就十分困难,尤其是在高 batch-size 的情况下。
OpenAI 的 GPT-4 架构中包含了 16 个专家模型,每个前向通道有 2 个路由(router)。这意味着在batch-size 为 8 的情况下,每个专家的参数读取可能只占批量大小的“1”。更严重的是,这还会导致某个专家的 batch-size 为 8,而其他专家的 batch-size 可能只有 4、1 或 0。
此外,每一次 token 生成,路由算法都会将前向传递路由到不同的方向,这会导致 token 到 token 之间的延迟和专家批处理量的显著变化。也就是说,处理不同的 token 时,不同的专家可能会被分配到不同的任务,计算负载和批量大小都可能因此发生变化。
推理 infra 是 OpenAI 在 MoE 的设计上选择较少数量专家的主要考量之一。如果他们使用更多的专家,内存带宽将成为推理面临的一个更大瓶颈。OpenAI 在自己的推理集群上常常能达到 4k 以上的 batch-size,这意味着即使在专家之间实现了最佳负载平衡,每个专家的批处理量也只能达到大约 500 个。这需要非常大的使用量才能实现。
我们的理解是,OpenAI 在由 128 个 GPU 组成的集群上运行推理,并且在不同的数据中心和地理区域拥有多个这样的集群。推理是以 8 路张量(tensor)并行和 16 路流水线并行的方式进行的。每个节点使用 8 个 GPU,每个 GPU 只有大约 130B 的参数,或者在 FP16 下每个 GPU 不到 30GB,在 FP8/int8 下不到 15GB。只要所有批次的 KV 缓存大小不会膨胀得太大,这就可以在 40GB 的 A100 上运行推理。
FP16、FP8 和 int8 是不同的数值精度(precision)表示方式,常用于深度学习中的计算过程中,以减少内存和计算资源的使用,从而提高模型训练和推理的效率。
FP16 、FP8、int8 分别指的是 16 位浮点数、8 位浮点数和 8 位整数,它们的精度相对于 32 位的单精度浮点数(FP32)更低,但可以大大减少内存和计算资源的使用,从而加速深度学习中的模型训练和推理。例如,使用 FP16 可以在不损失太多精度的情况下,将计算时间减少一半以上,而使用 int8 可以在不损失太多精度的情况下,将计算时间减少约 4 倍。
需要注意的是,使用低精度计算可能会对模型精度产生一定的影响,因此需要在精度和效率之间进行权衡,并根据具体的任务需求选择最合适的精度表示方式。
为了避免网络通信过于不规则,同时避免在每个 token 生成之间重新计算 KV 缓存的成本过高,包含各种专家的各个层并没有在不同的节点上进行分解,以便共享 KV 缓存。
未来所有的 MoE 模型扩展和条件路由的最大困难。在于如何处理 KV 缓存周围路由层数最大为 120 的限制。
在 MoE 模型中,每个分支的路由层数不能超过 120 层,否则将无法有效地处理 KV 缓存。这是因为在模型的推理过程中,每个分支都需要计算 KV 缓存,这会导致计算成本的增加。
解决这个问题的一个简单方案是,基于 120 的层数限制,在 15 个不同的节点中放置一个横跨路由。这样就可以将计算负载平均分布在不同的节点上,从而提高模型的效率和性能。然而,由于第一个节点需要进行数据加载和嵌入,因此如何在推理集群的头部节点上放置更少的层是很重要的。
另外,在对输入数据进行编码和解码的过程中,可能会存在一些关于推理解码的噪音,这个问题我们将在后面进一步讨论。较为关键的问题在于确定这些噪音是否应该被相信。这也可以解释为什么头部节点上包含较少的层是有意义的。
推理成本
相较于 175B 参数的 Davinchi 模型,GPT-4 有 1.6 倍的前馈参数,但成本却是 Davinchi 的 3 倍。这主要是因为 GPT-4 需要更大的集群,以及实现利用率更低。
我们猜测使用 128 个 A100s 进行 GPT-4 8k 上下文长度(seqlen)的推理,每 1k tokens 的成本约为 0.0049 美元。而使用 128 个 H100s 进行 GPT-4 8k 上下文的推理,每 1k tokens 的成本约为 0.0021 美元。(拾象注:当前 GPT-4-8k 的价格是 0.03/1k input tokens, 0.06/1k output tokens,当前 OpenAI 对推理芯片使用不会如作者推测的一样奢侈,该测算可以作为未来降价的 lower bound。) 需要特别注意的是,这些成本的计算是在利用率和 batch-size 都很高的情况下得出的。

考虑到 OpenAI 集群的利用率有时可能会非常低,我们的这一假设也有可能是错的。
我们假设,OpenAI 在低谷时期会关闭集群,并重新利用将这些节点重新分配给其他任务,例如恢复小型测试模型的检查点训练,或尝试各种新技术。这样的做法有助于保持低推理成本,否则 OpenAI 的利用率可能会更低,这意味着成本估算会是现在的 2 倍以上。
恢复小型测试模型的检查点训练,通常是指在训练深度学习模型时,使用之前保存的模型参数检查点,重新开始训练一个较小的模型(例如,一个仅使用模型的一部分参数的子集),以便在较短的时间内快速测试新的模型结构或算法。这种方法可以帮助研究人员快速迭代模型设计,并寻找最佳的模型结构和参数。
09. 多查询注意力机制
多查询注意力机制(Multi-Query Attention)的使用已经相当普遍,但我们想强调的是 OpenAI 也是这么做的。总的来说就是只需要 1 个注意力头(head),内存容量就能够显著减少以用于 KV 缓存。即便如此,32k 上下文的 GPT-4 肯定无法在 40GB 的 A100 上运行, 而 8k 的最大批量大小已经达到上限。如果没有 MQA,8k 的最大批处理量将被大大限制,经济效益大打折扣。
• 多查询注意力机制 (Multi-Query Attention,MQA):Fast Transformer Decoding: One Write-Head is All You Need 这篇论文于 2019 年提出了 MQA 这一概念,后来成为了自然语言处理中经常使用的注意力机制。
传统的注意力机制中,将一个查询(query)和一组键值对进行匹配,以获得对每个键的加权表示。而在多查询注意力中,有多个查询,并且每个查询都会与键值对进行匹配,以获得对每个键的不同加权表示。这个过程可以看作是在多个不同的“视角”下对输入进行编码,从而获得更全面和准确的表示。
• 注意力头(Head):在深度学习模型中,通常包含多个层(layers)和一个头(head),head 用于将模型的输出映射到期望的输出空间。头部层通常是为了满足特定的任务而添加到模型中的,例如在自然语言处理任务中,head 通常用于将模型的输出转换为文本,进行文本分类等任务。在深度学习模型中,head 通常是紧跟在最后一个层的后面,用于将最后一层的输出转换成期望的输出形式。
10. 连续批处理
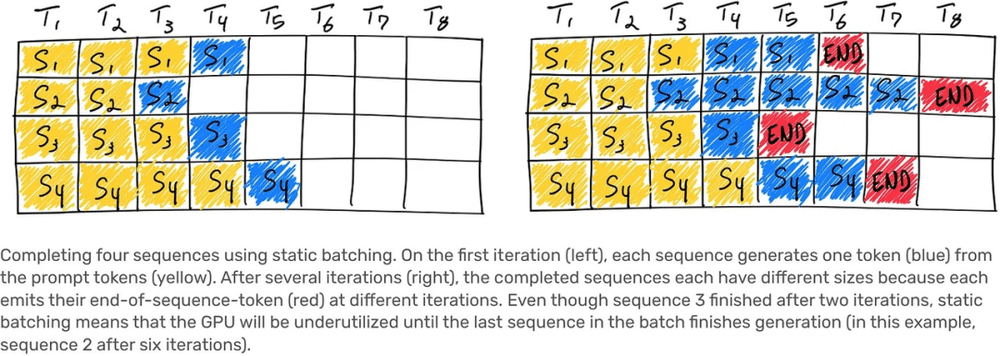
为了允许一定程度的最大延迟和优化推理成本,OpenAI 同时使用了可变批次大小和连续批次的技术。这种方法可以在不牺牲模型性能的情况下提高计算资源的利用率,并在模型的推理过程中实现更低的延迟和更高的吞吐量。如果不了解连续批处理这一概念的话,AnyScale 官方发布的 How continuous batching enables 23x throughput in LLM inference while reducing p50 latency 这篇文章非常值得一读。(拾象注:Anyscale 开发的分布式计算框架 Ray 是 OpenAI 在模型的 infra pipeline 中使用的,拾象之前发布过对这家公司的研究。)
连续批处理(Continuous batching):一种在深度学习训练过程中使用的技术,旨在提高训练效率和通过硬件的资源利用率。传统的批处理方法是将一定数量的训练数据一次性加载到内存中,然后对这些数据进行训练,这种方式可以提高训练效率,但也可能会浪费内存空间。
而连续批处理则是将训练数据分成若干个小批次,每次只加载一个小批次进行训练,训练完成后再加载下一个小批次,以此类推,直到完成整个训练数据集的训练过程。使用连续批处理技术可以在减少内存使用的同时提高训练效率,还可以提高模型的稳定性和泛化能力。
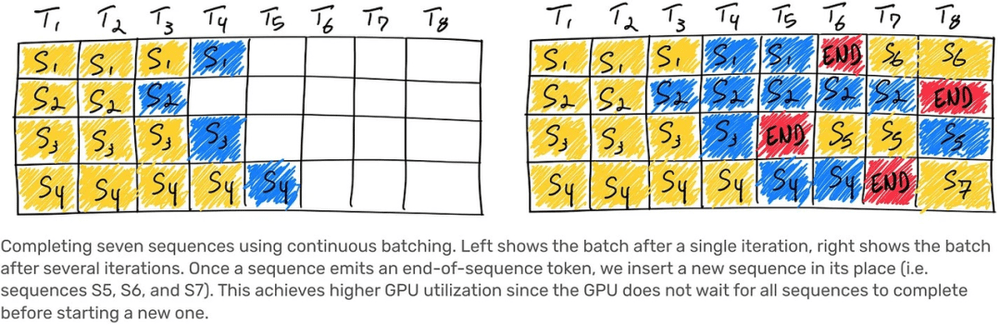
Source: Anyscale
11. 推测解码
有传言说,OpenAI 在 GPT-4 模型的推理任务中使用了推测解码(Speculative Decoding)技术。尽管我们不能确定这一消息的准确性,但是在进行简单的检索任务和更复杂的任务时,从一个 token 到另一个 token 的延迟和差异的一般变化似乎表明这种技术是可能存在的。然而,由于存在太多变量,我们无法确认这一技术是否确实被使用。
为了避免内容上的争议,这里引用 Accelerating LLM Infeferencewith Staged Speculative Decoding 中的一些内容,并在重点内容上加粗。
使用 LLMs 一般分为两个阶段:
1. 预填充(prefill)阶段
在这个阶段中,首先需要给定一个提示(prompt)作为输入,并通过模型运行来生成 KV 缓存和第一个输出 logits。其中,logits 是 LLM 在每个时间步长输出的概率分布向量,用于表示每个 token 的可能性。这个预填充阶段通常是很快的,因为并行计算。
2. 解码(decoding)阶段
在这个阶段中,从输出的 logits 中选择一个 token 并反馈到模型中,为下一个 token 产生 logits。这样反复进行,直到产生所需数量的 tokens。由于每次解码都必须按顺序进行计算以产生一个 token,所以在小批量运行时,这个第二阶段的算术强度(即计算的 FLOP/内存带宽的字节)非常低(拾象注:序列计算导致算力无法被充分利用。)因此,解码通常是自回归生成中最昂贵的部分。
这就是为什么在 OpenAI 的 API 调用中,输入 token 要比输出 token 便宜很多的原因。
推测解码的核心思想是使用一个较小、较快的 draft 模型提前解码几个 token,并将它们作为一个批次送入 oracle 模型。如果 draft 模型的预测是正确的(即与 oracle 模型的预测一致),就可以使用一个批次来解码几个 token,从而为每个 token 节省大量的内存带宽和时间。
Oracle 模型是指在推测解码方法中使用的一个较大、较慢的 LLM 模型,用于验证 draft 模型的预测结果。Oracle 模型会根据 draft 模型的预测结果和之前生成的 token 来计算出下一个 token 的概率分布,然后将这个概率分布作为输出返回给 draft 模型。
通过使用 Oracle 模型来验证 draft 模型的预测结果,可以避免 draft 模型在后续解码过程中产生误差和偏差,从而提高模型的准确度和稳定性。同时,Oracle 模型也可以帮助 draft 模型更好地学习和理解语言模型中的上下文信息,从而提高模型的生成能力和效果。
然而,如果较大的模型拒绝了 draft 模型所预测的 token,那么其余的批次就会被丢弃,算法会恢复到标准逐 token 解码的方式。推测解码也可以结合拒绝采样方案,从原始分布中去采样 token。需要注意的是,这种方法只能在带宽为瓶颈的小批量设置中发挥作用。
简而言之,推测解码以计算量换取带宽,有两个关键原因可以说明为什么它是一个有吸引力的性能优化目标。首先,推测解码完全不会降低模型质量,因为它只是通过修改解码阶段的计算流程来提高模型的推理速度和吞吐量。第二,它所提供的收益与其他方法通常是独立的,因为它的优势在于将顺序执行的计算转换为并行执行,而其他方法则主要从模型结构、参数、训练等方面入手进行优化。
目前的推测方法是针对每个批次预测一个单一序列。然而这种方法在大批次或低精度 draft 模型的情况下无法很好地扩展。直观来说,对于长连续 token 序列,两个模型预测一致的概率呈指数级下降,这意味着随着算法强度的扩大,推测解码的回报会迅速减少。
我们认为,如果 OpenAI 正在使用推测解码,他们很可能只将其用于长度约为 4 个 token 的短序列。此外,还有人认为 GPT-4 模型性能的下降是因为 OpenAI 在模型预训练中加入了来自推测解码模型的低概率的序列,这种猜测可能不是真实的。
也有一些人认为 Bard 模型也使用了推测解码,因为谷歌在向用户发送完整序列之前会等待完整序列的产生,但我们并不认为这种猜测是真实的。
12. 视觉多模态
视觉多模态技术(Vision Multi-Modal)在 GPT-4 中可能是最不引人注目的部分,至少与其他研究相比。到目前为止,还没有人进行关于多模态 LLM 研究商业化的探索。
视觉多模态(Vision Multi-Modal):它是指将来自不同模态(如图像、文本、语音等)的信息进行联合处理和分析的技术。通常,这些不同模态的信息在语义上是相关联的,因此将它们结合起来可以提供更丰富的信息和更准确的推理结果。
GPT-4 的视觉多模态能力是通过一个独立于文本编码器的视觉编码器来实现的,并且与文本编码器有交叉注意力机制(Cross-Attention),据说它的架构与 Flamingo 模型相似。这个视觉编码器是在 1.8 万亿参数的 GPT-4 模型中微调的,但是,它只是使用了额外的约 2 万亿 token 的文本数据进行预训练,而没有使用视觉数据进行预训练。
交叉注意力机制(Cross-Attention):是一种在多个序列数据之间建立关联的机制,它在自然语言处理和计算机视觉等领域得到了广泛应用。在序列到序列的任务中,如机器翻译和文本摘要,交叉注意力机制用于计算源序列和目标序列之间的相关性,以便在生成目标序列时使用源序列中的信息。
在计算机视觉任务中,交叉注意力机制用于将图像和文本之间建立联系,以便在图像描述生成和视觉问答等任务中使用。
OpenAI 计划在视觉模型方面从头进行训练,但该技术尚不够成熟,因此他们希望通过从文本开始训练来降低风险。
有传言说,OpenAI 的 GPT-5 将从头开始训练视觉模型,并且具有自动生成图像和音频处理的能力。
视觉多模态技术的一个主要目的是让自主代理能够阅读网页并转录其中的图像和视频内容。OpenAI 训练这个模型的数据包括联合数据(包括渲染的 LaTeX/文本)、网页截图和 Youtube 视频采样帧等,并使用 Whisper 技术来进行转录。
关于 LLM 过度优化的问题,一个有趣的事情是,视觉模型的 IO 成本与纯文本模型的 IO 成本不同。文本模型的 IO 成本十分低廉,但在视觉模型中,数据加载的 IO 成本约为文本模型的 150 倍。每个 token 的大小为 600 个字节,而文本模型只有 4 个字节。目前,有很多工作正在进行图像压缩方面的研究。(拾象注:文字的信息更容易压缩,图片/视频的 tokenization 是多模态领域值得重点关注的方向。)
IO 成本:IO 成本是指在计算机系统中完成输入/输出操作所需的时间、资源和能源成本。这些成本包括数据传输、存储和处理等方面。在机器学习和深度学习领域中,IO 成本通常是指从存储介质(如硬盘、内存、网络等)中读取和写入数据的成本。在模型训练和推断过程中,IO 成本可能会成为瓶颈,影响系统的性能和效率。因此,为了提高计算机系统的性能和效率,需要考虑和优化 IO 成本。
这对于那些在 2-3 年后优化硬件的供应商来说非常重要,他们需要考虑到每个模型都具备强大的视觉和音频能力的情况。他们可能会发现他们架构的适应性很差。总而言之,未来的 LLM 架构肯定会发展到超过我们今天看到的基于文本的简化稠密型和/或 MoE 模型。
Reference
https://www.semianalysis.com/p/gpt-4-architecture-infrastructure
本文来自微信公众号:海外独角兽 (ID:unicornobserver),作者:Dylan Patel,Gerald Wong,编译:Haina、wenli、Cage,编辑:Siqi