
本文来自微信公众号:腾讯研究院 (ID:cyberlawrc),作者:王融,原文标题:《大模型研发者是数据控制者么?——基于OpenAI的观察》,头图来自:视觉中国
以ChatGPT为代表的生成式人工智能技术正在以令人惊异的速度进化。随着商用化序幕拉开,相关隐私和个人信息保护等数据合规问题(以下简称数据合规)进入公众视野。但实际上,数据合规并不是AI行业面临的新问题。
妥善解决隐私和数据安全,赢得用户信任,是任何一项应用取得成功的基本前提。相比于移动互联网、云计算、区块链、自动驾驶等技术,我们更关注新一代AI在数据合规中的独特问题。对于代表着新拐点、新范式的新一代AI,相关法律认定都还为时过早。
一
正在浮现的市场主体
生成式 AI 行业生态正在快速发展形成中,规模庞大,主体呈现多样化。根据已浮现的商业形态,生成式 AI 市场主体目前大致可以区分为三类:
一是底层大模型研发者,包括OpenAI, Stability AI Google,Meta等,这些公司已发布各自的底层模型。所谓大模型,是指基于大量数据训练的、拥有巨量参数、展现涌现能力的模型。
二是面向B端各垂直领域\行业的模型研发者,例如[1]:
1. 医疗保健:Zebra Medical Vision ,Aidoc 等公司使用生成式 AI 为客户进行医学图像分析、诊断和治疗规划。
2. 制造业:通用电气等公司利用生成式人工智能优化生产流程、预测性维护和供应链管理。
3. 金融服务:Bloomberg发布的Terminal AI大模型。基于GPT-3架构,可以处理金融领域的专业文本数据,提供金融智能化的服务。
4. 零售:Stitch Fix 等公司使用生成式人工智能来实现个性化购物体验、库存管理和需求预测。
三是面向B端和C端个人用户提供生成式AI应用的服务商,例如:
1.内容生成:Jasper、ChatGPTGPT-3 Creative Writing 等平台使用生成式 AI 来创建书面内容,包括营销文案、社交媒体帖子和其他书面材料。
2.语言翻译:谷歌翻译利用生成式人工智能在不同语言之间翻译文本。
3.图像和视频生成:Midjouney , DALL-E等平台使用生成式 AI 来创建合成图像和视频。
对于以上主体,适用现有的隐私数据合规框架可从两个维度展开:一是区分业务场景(to C/to B),以明确法律主体身份,即是否是个人信息保护法中的个人信息控制者,处理者抑或是其他角色;二是区分数据处理的流程环节,以明确法律主体所适配的数据合规义务。
当主体身份重合时,更需要基于不同业务流程划分合规要求。以OpenAI为例,其既面向个人用户提供ChatGPT服务,也将基础大模型能力以API方式提供给专业开发者,在不同业务场景中,其所涉及的个人信息处理活动有着显著的不同,这对于法律角色和合规义务有着直接的影响。
二
基础大模型研发者是否是隐私数据合规框架下的data controller,是一个值得讨论的问题。
区别于媒体大众上关于AI数据合规的笼统讨论,从专业视角审视,AI底层大语言模型研发提供者,有可能并不认定为隐私数据合规上的法律主体——数据控制者(data controller)。 数据保护法上所界定的数据控制者是指:能够单独或与他人共同决定个人数据处理目的和方式的组织或个人,其在个人信息处理活动中发挥核心决策作用,并对该决策负责。
欧盟数据保护机构也认同:“控制者是一个功能概念,旨在根据事实影响分配责任”。控制者必须确定应为哪些预期目的处理哪些数据。换言之,控制者知道他在处理有关个人数据方面所做的事情,知晓正在处理的是以语义方式“与已识别或可识别的自然人有关的信息”,而不仅仅是计算机代码。
但在大模型训练中,并非如此。以OpenAI模型训练为例,首先,其数据处理的主要目的是训练模型形成语言理解、预测、生成能力,甚至是举一反三的推理能力,而非处理个人信息目的。数据源的选取也主要是满足语言生成方向。
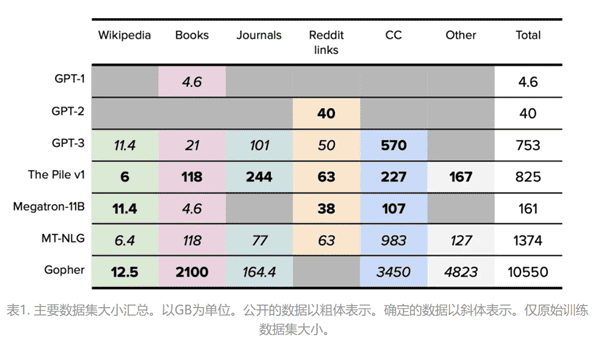
OpenAI披露的数据源主要来自于公开信息。包括:维基百科、书籍、期刊、Reddit链接、Common Crawl和其他数据集。维基百科准确规范程度高,以说明性文字形式写成,并且跨越多种语言和领域,有助于提升模型的精确性;书籍由小说和非小说两大类组成,主要用于训练模型的故事讲述能力和反应能力;Reddit链接与Common Crawl则能较好覆盖网络公开信息,代表网络流行内容的风向标,对输出优质链接和后续文本数据具有指导作用[2]。
从以上数据收集来看,其数据处理的主要目的是在于实现对语言表达的尽可能覆盖,以提升模型语言输出规范,无限靠近人的语言表述方式,而与个人信息处理目的相去较远。正如OpenAi声明:“我们希望我们的模型是了解世界,而不是了解个人。”[3]
其次,在海量原始数据资源中涉及的个人信息绝大部分是网络上的公开个人信息。从以上数据源可知,在维基百科、书籍、学术期刊中的数据中,个人信息本身占比较小,相对占比较多是通过Common Crawl获取的数据。
Common Crawl 是一个非营利性组织,定期抓取互联网公开网页,并将这些数据存储在 Amazon S3 上,使得任何人都可以免费访问和使用这些数据。目前,Common Crawl 的数据集已经成为自然语言处理、机器学习的重要数据来源之一,在促进全球研究和技术创新方面发挥了积极作用。
公开网络中不可避免会包含相当数量的个人信息,但其中大部分应属于已公开的个人信息,为实现个人信息利用与保护的平衡,包括我国在内的各国个人信息保护法对已公开的个人信息的利用均作出一定程度的豁免。例如:《个人信息保护法》第十三条第六项,将在合理的范围内处理个人自行公开或者其他已经合法公开的个人信息作为数据处理的合法性基础之一。
类似的,欧盟《一般数据保护条例》(GDPR)把个人数据区分为一般个人数据与特殊(敏感)个人数据。依据该条例第 9 条第 1 款,原则上禁止对于数据主体的特殊(敏感)个人数据进行处理,但是同条也规定了例外情形,如果数据主体明显地公开了(manifestly made public)特殊个人数据的,则数据控制者也可对之进行处理。
在美国法律上,更是干脆将公开的个人信息排除在“个人信息”之外。例如:2018 年《加利福尼亚消费者隐私法》(CCPA)与 2020 年《加利福尼亚隐私权法》(CPRA),均明确将“公开获取的信息”(Publicly Available Information)排除在个人信息之外[4]。
最后,从原始信息到可供模型训练的数据的过程中,个人信息的成分是不断衰减的。从原始数据源到进入模型的训练数据集,数据规模往往会缩小很多。据称,GPT2021年的官方原始数据源是31亿个网页内容, 约320TB文字信息,但最终作为训练数据的是753GB。
这是因为原始数据源通常包含大量的文本信息,但其中很大一部分并不适合作为模型的训练数据,需要经过清洗(去除无用的信息、错误数据和重复记录、噪音数据等)、预处理(将文本转化为数字向量)、划分增强(将数据区分为不同训练功能目)等一系列的加工过程,因此即使原始数据源中包含了部分个人信息,随着这一加工过程,个人信息成分也会不断衰减。
此外,模型研发者为了进一步降低隐私和数据合规风险,在数据源中包含的个人信息(即使是公开个人信息)也会主动采取删除、匿名化、或者用合成数据替代等措施。
三
如果参考2014欧盟“被遗忘权”判决中对于数据控制者的界定逻辑,模型研发者的法律身份问题将更值得商讨。
尽管在欧盟“被遗忘权”判决中,作为搜索引擎的谷歌最终被裁定为“数据控制者”,但在案件过程中的讨论争议依然可以为今天面临的新问题:如何确定大模型研发者的法律主体地位提供参考。
首先简单回顾下欧盟“被遗忘权”案来龙去脉:1998年,西班牙《先锋报》刊登了市民冈萨雷斯因无力偿还债务而遭拍卖房产的公告。2010年,冈萨雷斯发现,如果在谷歌搜索引擎输入他的名字,会出现指向《先锋报》关于其房产拍卖的网页链接。冈萨雷斯认为这些信息已经过去多年,希望谷歌能够删除该链接。
该案一直打到欧洲法院,欧洲法院随后做出了轰动世界的“被遗忘权”判决:冈萨雷斯要求《先锋报》删除其个人信息的主张被驳回,因为这涉及干涉新闻自由;但谷歌作为搜索引擎服务商,被视为1995年《数据保护指令》界定的数据控制者,对其处理的第三方发布的带有个人数据的网页信息负有责任,依据该判例,欧洲居民可以向搜索引擎申请在搜索结果中删除有关个人的“不恰当的、不相关的、过时多余”(inadequate, irrelevant, excessive)的网页链接[5]。
判决发布后的争议持续到今天,谷歌在建立线上“被遗忘权”申诉平台后,接到大量申请要求删除相关新闻报道,这被观察者认为是一种新形式的网络审查。即使在欧盟内部,该判决很大程度上也在意料之外,因为在确立搜索引擎是否是欧盟数据保护法意义上的“数据控制者”(data controller)这一问题上,存在根本性分歧。
在“被遗忘权诉讼”最终判决之前,欧洲最高法院总法律顾问Niilo JÄÄSKINEN发布的法律意见书中,明确表达其不认同将搜索引擎视为数据控制者的主张[6]。他认为:在互联网背景下,应区分三种与个人数据处理相关的情况。
(1)第一种是在互联网的任何网页(“源网页”)上发布个人数据元素。
(2)第二种情况是互联网搜索引擎提供的搜索结果将互联网用户引导至源网页。
(3)第三种是互联网用户使用互联网搜索引擎时,他的一些个人数据,例如IP地址,关键词的处理。
其中第(1)和(3)的场景中的数据控制者不存在争议,但就第(2)种情形,很有讨论的必要。
搜索引擎索引、缓存和显示信息的方式构成了对个人数据的“处理”,但这并不等于说它们构成了欧盟法意义下的“数据控制者”,并负担数据控制者的合规义务。仅提供信息定位工具的互联网搜索引擎不会对第三方网页上包含的个人数据行使控制权。除了作为统计事实之外,服务提供商不会“意识到”个人数据的存在。
对于搜索引擎而言,网页可能包含个人数据,但这种存在是随机的,包含个人数据的源网页与不包含此类数据的源网页之间并没有在搜索引擎上的技术操作上产生差异。搜索引擎服务商也无法在法律上或事实上针对与第三方服务器上托管的源网页上的个人数据履行有关的控制者义务……
这一逻辑对应当下大模型训练场景是何其形似!相比搜索引擎,大模型研发过程中,对于数据源中涉及的个人信息,更像是数据收集阶段不可避免的附属产品,而非研发者的初衷。相反,为降低隐私和个人信息风险,研发者还需投入大量精力,将其在数据源中删除或者匿名化。
遗憾的是,在“被遗忘权”案例中,欧洲法院并没有听取总法律顾问的意见。最高法认为搜索引擎在业务运营过程中,会根据用户偏好投放相关广告,这构成了对于个人信息的处理活动,应履行数据控制者义务。
在今天看来,这一判断混淆了搜索引擎不同数据处理阶段与对应的合规义务,如果将这一逻辑适用于大语言模型研发者,会出现令人尴尬的局面。因为就广告投放而言,当前大模型的研发者,在其商业形态中恰恰排除了这一类模式。OPENAI明确表示:我们不使用数据来销售我们的服务、做广告或建立人们的档案。
正如总法律顾问在法律意见书中阐明:欧盟1995数据保护指令发布时,互联网刚刚起步,第一批搜索引擎开始出现,但没有人能预见它改变世界的程度。因此,对新技术现象给予法律上的解释时,必须考虑比例原则,有必要在个人数据保护、信息社会目标、市场主体以及互联网用户广泛的合法利益之间取得相称的平衡。
今天,我们再次面临又一个即将改变世界的技术创新。大模型是未来智能的基础设施,还是智能工具抑或它本身就是无处不在的知识?尚未有确定性的答案。大模型研发者在数据合规上的身份属性,则更是一个值得讨论的问题。至少从大模型技术机理出发,将其认定为数据控制者的结论并没有充分的逻辑闭环。当然,这并不否认研发者从负责任的AI出发,在研发阶段对包括隐私在内的数据安全问题应予以高度关注,并尽可能将风险降到最低。
参考资料:
[1]以下关于生成式AI生态市场主体的介绍,主要来自于ChatGPT4 问答,在此基础上做了必要的检查核实.
[2]Alan D. Thompson, What’s in my AI? A Comprehensive Analysis of Datasets Used to Train GPT-1, GPT-2, GPT-3, GPT-NeoX-20B, Megatron-11B, MT-NLG, and Gopher, https://lifearchitect.ai/whats-in-my-ai/, March 2022.
[3]https://openai.com/blog/our-approach-to-ai-safety.
[4]程啸,《论公开的个人信息处理的法律规制》,载《中国法学》2022年第3期,第96页.
[5]相关内容详见:王融:被遗忘权很美?《中国信息安全》2016年08期.
[6]https://curia.europa.eu/juris/document/document.jsf?text=&docid=138782&pageIndex=0&doclang=EN&mode=req&dir=&occ=first&part=1&cid=321592
本文来自微信公众号:腾讯研究院 (ID:cyberlawrc),作者:王融(腾讯研究院首席数据法律专家)