
上周,虎嗅旗下虎学研究栏目更新了《中文在人工智能大潮中注定落后吗?》这期节目,节目播出后,我们收到了来自各方面的讨论和质疑,问题主要分两类:
其中一类就是有不少人工智能从业者指出我们对ChatGPT原理理解得不够透彻和准确,再一类就是大家对于“让人工智能说中文真的有那么难吗?”这件事依然有疑惑。
于是节目组经过互相拷打,对这些问题进行了更深入的学习和讨论,形成了下面几个问题和答案,希望能对屏幕前的你有帮助。
在这个AI浪潮里,希望我们都能保持思考和进步。
如果你还没有看过视频,可以点击文章最后的视频号卡片观看。
ChatGPT这样的大语言模型,理解的语言到底是什么?
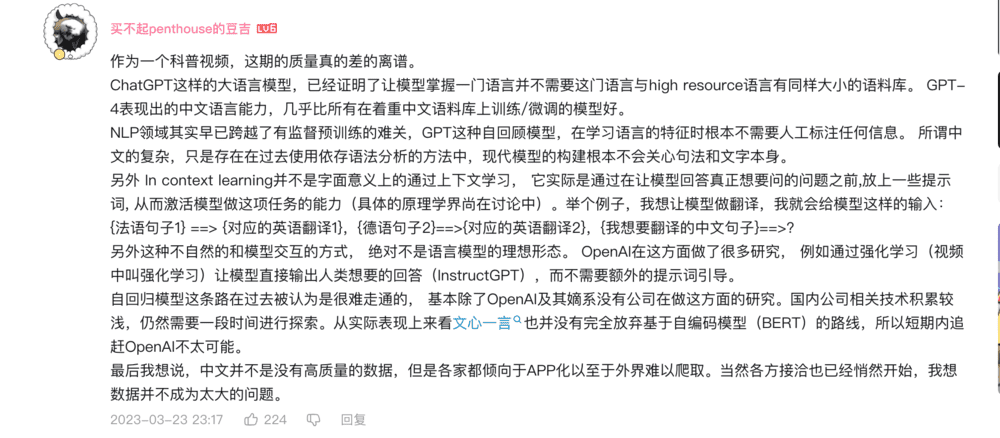
要解释这个问题,或许就需要知道ChatGPT到底是怎么“说话”的。这可以从GPT三个字母的全称,Generative Pre-trained Transfomer(生成型预训练变换器)得到答案。
生成型,意思就是依靠上文,预测下文。而预训练变换器,则意味着它使用了Transfomer架构,也就是通过模仿人类的“注意力机制”,学习词与词之间的关系,并预测下一个单词。而对于ChatGPT来说,它使用的是一种自回归式的生成模式,也就是模型每生成一个字,都会加入到上文中进行下一次预测,这使得模型的学习能力和准确度都有显著提升。
从结果来看,ChatGPT可以和我们用“语言”进行对话,从原理上看,ChatGPT是一个可以通过数学运算预测,完成“接下句”的工作的模型。我们完全可以说ChatGPT不知道它输出的“答案”背后到底是什么意思,但可以输出从“语言”角度上来讲正确的答案。
GPT-4的中文挺好的,是怎么做到的?
GPT-4发布以后,网友把我们视频中举的几个例子,比如说“我看完这本书花了三天了”给GPT-4看,发现它完全可以理解,非常厉害,我们试用了以后也发现,GPT-4在中文理解和输出上也已经有了很强的能力了。
那它是怎么做的?GPT-3的论文里其实有部分解释ChatGPT的“few-shot学习”机制。简单来说,就是“举例子”。
比如我要让AI翻译“上山打老虎”,我会在输入问题的时候,同时给他几个中译英的例子,像这样:
Promot:上山打老虎
example1:天王盖地虎 ---- sky king gay ground tiger
example2:上阵父子兵 ---- go to battlefield together
然后再让AI根据这个上下文进行输出,这个就叫In-contex learning,是OpenAI训练模型的具体手段。具体的原理目前恐怕一时半会儿解释不清楚,但从GPT-3的论文标题《Language Models are Few-Shot Learners》我们就能知道结果很明显:好用。
到了GPT-4,它的多语言理解能力更强了,但这次论文里公开的技术细节很少,而且从某些角度来讲,ChatGPT能做到的,和大家能解释的内容开始逐渐发生偏差,我们也希望能借此机会和更多专业的朋友一起讨论这个问题。
那中文语料不行,影响什么了?
在原始视频中,我们指出中文语料差,导致语言模型在学习中文表达的时候遇到了很多的困难。但评论里其实也有朋友用GPT-4的例子说,有了前面提到的in-context learning机制,其实现在的大语言模型在掌握一门新语言的时候,不需要这门语言的庞大语料库了。
在和一些从业者聊过后,也有朋友表示,不同语言对于AI来说都是数据,在大算力和深度学习面前,没有什么太大的区别。
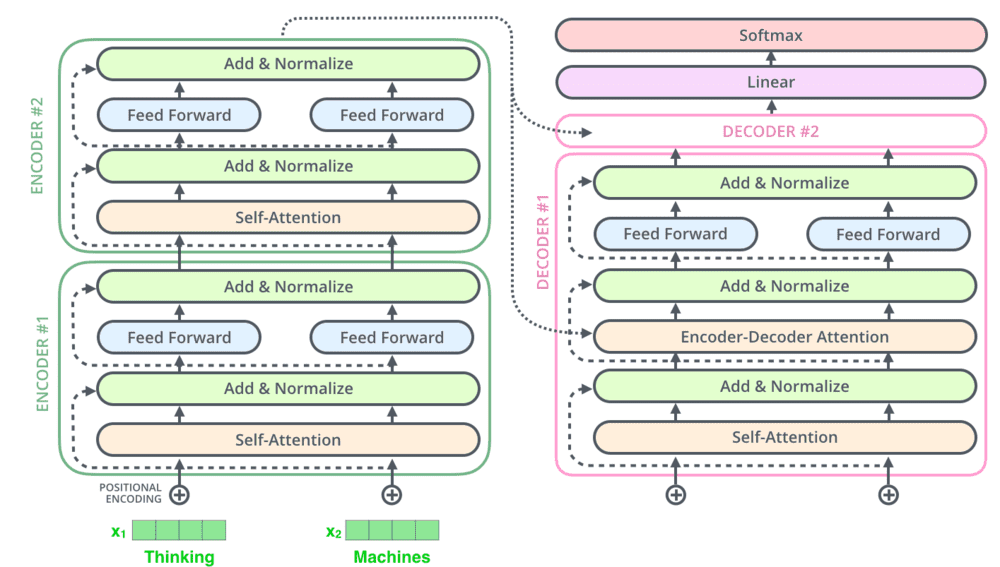
但我们可以了解一下ChatGPT本身选取语料的办法,根据论文显示,GPT-3模型用到的Token(NLP研究对于词语的一个单位)数量高达499B,也就是4990亿个。而GPT-4到底用了多少外文语料,OpenAI目前还没有公开。
虽然说名师出高徒,但臭皮匠的数量足够,外加正确的学习方法,还是能出高徒的。
那如果我们用文言文训练呢?
在视频的评论区里很多人提出了这个有趣的问题!还有人说“文言文是不是人类最后的堡垒”,那我们火星文是不是也有机会……
如果你理解了前面我们对于ChatGPT原理和训练过程的介绍,就会知道其实文言文可能对于数据模型来说,只是“要不要练,怎么练”的过程。
如果我们想要一个会说文言文的AI,可能需要给他喂足够多的文言文语料,这背后带来更多的工作,比如说文献数字化、分类、提取……
人工智能是个烧钱的生意,或许目前我们还不太需要一个会说文言文的AI?
谁知道呢。
那如何让AI说好中文?
正如我们刚才所说,目前国内已经公开的大语言模型,其实只有文心一言一个,而文心一言其实也没有公开具体的训练和参数细节。但从公开的信息可以知道,文心一言用的也是Transfomer架构,但只是更偏向谷歌BERT的技术思路,而非ChatGPT的思路(说的不对的话请百度的同学后台私信我)。
那既然如此,或许我们可以照猫画虎,通过ChatGPT和BERT的公开信息,梳理一个”工作表“——到底需要做什么,才能让AI说好中文。
首先是语料,语料就仿佛是土壤,有好的土壤自然就有好的基础。或许我们需要一些除了维基百科之外的中文语料集来进行训练,同时或许也可以像OpenAI一样,先使用英文语料,再教会它翻译。
其次就是训练方式方法,技术路线各家有各家的不同,但具体采用什么样的技术手段,一定会直接影响产品的最终表现。
最后就是钱和时间。时间很简单,谁学说话不得花时间呢,其次就是钱。据估算,GPT-3训练一次的成本是500万美元,而整体成本更是突破数亿美元。
这些都是白花花的银子。
AI用英语训练,对多元文化的影响是什么?
这似乎是一个不太被目前所讨论的问题,但正如好莱坞对全球文化的影响,如果人工智能真的会像一些人预期那样席卷全球,那么这基于英语的训练数据,是否会影响文化的多元性呢?
在OpenAI公布的论文里我们可以知道,ChatGPT在进行RLHF(基于人工反馈的强化学习)时,寻找了40个承包商(contractor)进行”打标签“(labeling),这些承包商是什么背景的,我们暂时不得而知。
又考虑到目前Transfomer和神经网络的黑箱特性,这些人工干涉的部分会对最终的模型产生什么影响,实际上是暂时不明确的。但从以往人工智能的实例来看,偏见普遍存在,而通过参数调整解决这个偏见,还是个难题。
大语言模型会影响语言本身吗?
早上看到一个笑话:
有的公司在训练有意识的AI;
有的公司在训练无意识的工人。
(via 夏之空)
现在各种”AI使用指南“正在如同雨后春笋般冒出来,从实际效果来看,至少可以确定的是,用ChatGPT学习外语绝对是可行的,像是翻译、润色、理解,这些都是大语言模型所擅长的。
但也有人担心了,如果我们过度依赖大语言模型,我们会不会又从训练AI的人,变成被AI训练的人呢?如果AI底层有一些问题,那我们是否会受到影响呢?
未来会怎么样?
就在我写这篇稿子的时候,著名安全机构生命未来研究所(Future of Life Institute,FLI)发布了一封公开信,信中呼吁全球所有机构暂停训练比GPT-4更强大的AI至少六个月,并利用这六个月时间制定AI安全协议。
目前这个公开信已经有1125名知名人士签字,包括伊隆·马斯克和史蒂夫·沃兹尼亚克。
因为速度实在是太快了……就好像在人工智能的牌桌上,大家手里都是大王小王一样。
正如公开信中所说,AI系统在一般任务上已经具备了与人类竞争的能力,那下一步是否就要取代人类了呢?
我还是引用一下公开信的结尾吧,欢迎大家留言讨论:
Let's enjoy a long AI summer, not rush unprepared into a fall.
让我们享受一场漫长的AI夏天,而不是毫无准备地冲向深秋。(手工翻译,未使用AI)