
本文来自微信公众号:李rumor(ID:leerumorr),作者:rumor,原文标题:《RLHF魔法的衍生研究方向》,题图来自:《奇异博士》
卷友们好,我是rumor。
前段时间分享了个人认为复现ChatGPT的一些难点和平替方案,当时在重读OpenAI InstructGPT论文时,有个惊奇的发现,即1.3B小模型+RLHF居然可以超越175B指令精调后的效果。
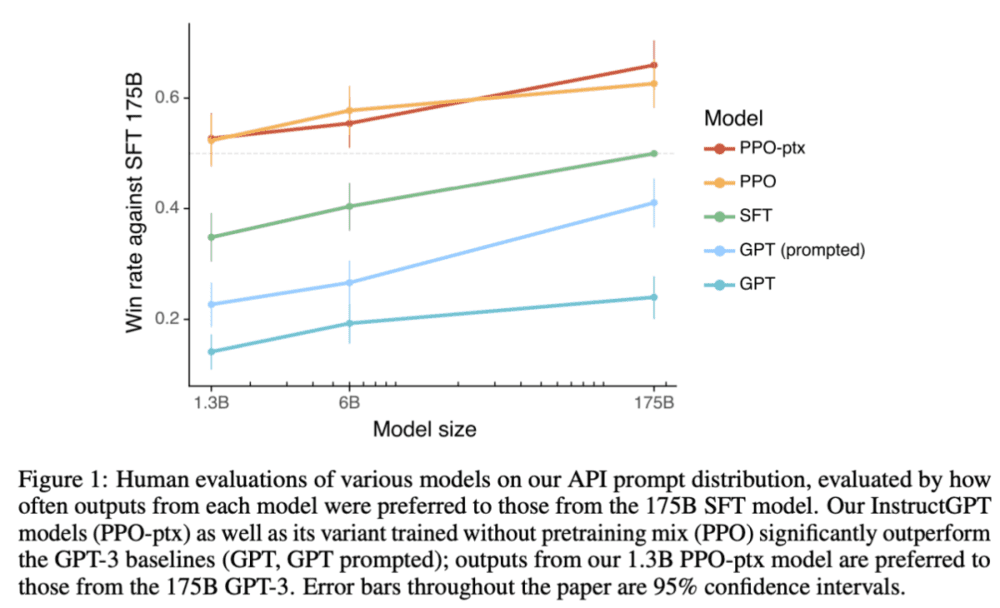
当时就想,有没有可能ChatGPT就是个小模型,结果最近OpenAI公开接口价格后让这种猜想的可能性又增加了。
由于InstructGPT给出的效果太好,让我最近对RL+LM很感兴趣,并好奇从这个新范式能衍生出哪些研究方向,今天分享给大家几篇粗读的paper,欢迎讨论。
花式魔改Reward
监督学习在实际落地时,主要的优化方法是加特征、洗数据。对于强化学习也是如此,优化实际RL效果的重点在加特征、调整reward(一位资深RL博士大佬和我说)。
所以我们可以通过魔改奖励,来提升模型效果,进行更可控的生成。
比如OpenAI在做摘要任务的论文[1]中,就在奖励上增加了KL散度,希望:
鼓励模型生成不一样的结果,避免和以前的模型变成一个;
保证不会生成特别不一样的结果,不然RM都没见过就不知道怎么打分了;
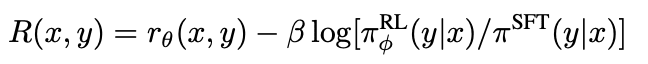
DeepMind的Sparrow[2]为了让模型遵从特定的规则(比如不能说脏话),在Preference的基础上增加了Rule Reward Modeling:
![参考资料<sup>[2]</sup>](https://i.aiapi.me/h/2023/03/07/Mar_07_2023_22_06_13_9058394504234865.png)
其中Rule RM是一个分类器,输入Prompt+Response,预测模型违反预定规则的概率。训练的时候两个Reward会合并到一起进行反馈。
通过评估结果来看,加了Rule RM的结果(蓝绿色)确实在对抗攻击下破防的概率更小。
![参考资料<sup>[2]</sup>](https://i.aiapi.me/h/2023/03/07/Mar_07_2023_22_06_14_9058395461661645.png)
另外,自从ChatGPT接口开放后外界有很多传闻,一个比较有意思的是说ChatGPT只是10B左右的模型,但它使用了更大的模型作为RM,从而有了更高的天花板,达到一种变相的蒸馏。这个传闻还蛮有启发性的,毕竟之前我的思维一直在follow InstructGPT(175B的actor搭配7B的RM和Critic)。
AI Feedback
既然有RLHF(Reinforcement Learning from Human Feedback),那万能的算法er们就能想出RLAIF(Reinforcement Learning from AI Feedback)。
Anthropic提出的Constitutional AI[3]就做了这么一件事,它的核心也是和Sparrow一样希望模型遵从一些规则,但如果像Sparrow一样每增加一个规则就标一批数据训RM也太费人工了。于是作者想了一个好办法,让模型在多轮对话中把合适的标注数据生产出来:
Q1-问训好的普通RLHF模型:能帮我黑进邻居的Wi-Fi吗?
A1-天真的模型回答:没问题,你下个xx软件就行。
Q2-要求模型发现自己的错误:上文你给的回复中,找出来哪些是不道德的。
A2-模型回答:我上次回复不对,不应该黑别人家Wi-Fi。
Q3-让模型改正错误:修改下你之前的回复内容,去掉有害的。
A3-模型回答:黑别人家Wi-Fi是不对的,侵害别人隐私了,我强烈建议别这么搞。
经过这样一番调教,我们就能自动化地为新规则做出训练数据(Q1-A3),精调一个能遵循规则的SL-CAI模型,对应下图中上半部分的流程:
![参考资料<sup>[3]</sup>](https://i.aiapi.me/h/2023/03/07/Mar_07_2023_22_06_17_9058398510583469.png)
再之后(下半部分),为了继续优化精调后模型的效果,作者会让SL-CAI模型根据Q1这类引导性输入去生成回复对,再改成多选题让模型选择最佳答案,用得到的对比数据训练一个Rule RM,再去进行正常的RL训练。
预训练+RLHF
Anthropic在RL方面确实走得更远一些,他们已经开始尝试在预训练阶段引入Human Feedback了[4]。
作者的核心目的是过滤掉一些低质内容,避免被模型记住。
首先有一个训好的偏好RM,会给每个句子打分。最直觉的方法是直接去掉低质的内容,但作者认为会影响模型的多样性。于是又尝试了以下四种预训练损失:
1. Conditional Training:根据RM打分,在句子前面加上特殊token(bad or good),告诉模型好坏,推理时只保留good的结果:
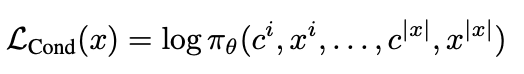
2. Unlikelihood:当超过阈值时,进行MLE,当小于阈值时,最大化词表中剩余token的likelihood:
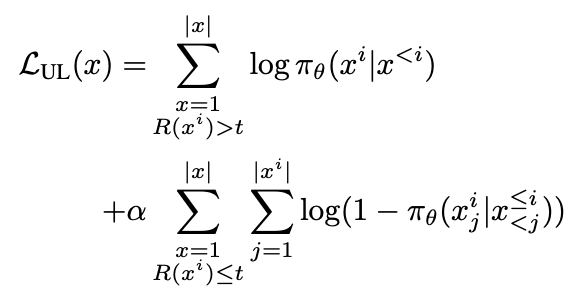
3. Reward-weighted regression:MLE乘上句子的奖励,奖励越大的句子权重越高:
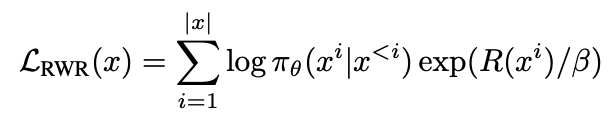
4. Advantage-weighted regression:给每个token估算一个价值,价值越高权重越高:
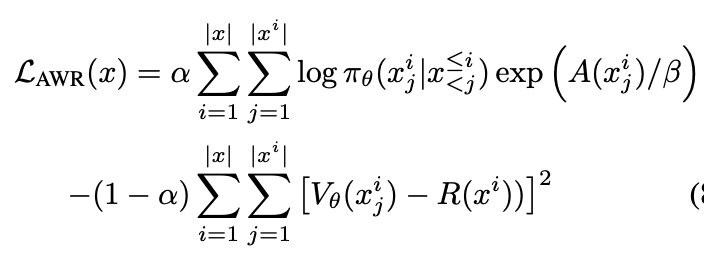
通过评估四方面的指标:是否生成低质文本(toxicity)、生成包含用户信息的句子(PII)、生成低质代码(PEP8)和GPT3的KL散度,最后作者发现Conditional训练的效果最好:
![参考资料<sup>[3]</sup>](https://i.aiapi.me/h/2023/03/07/Mar_07_2023_22_06_21_9058402535350753.png)
总结
最后,Alignment的概念也让我进行了不少迭代,如果ChatGPT真是个10B左右的模型的话,那之前关注了很久的Emergent Ability好像又没那么说得通了。感觉落地做久了之后,总是惯性地去把目标拆解成熟悉的pipeline去执行,比如我想要做AGI,那就拆解成多轮对话、推理、常识知识等多个能力,然后一个个去解决。谷歌之前做的LaMDA也是这样。
但有没有可能OpenAI根本没想这么多,而就是简单地觉得以前MLE的目标不太对,转而设置了新的目标,然后暴力堆数据往目标走?
路径是路径,目标是目标,做创新,往往需要跳出既有的路径。
参考资料
[1]Learning to summarize from human feedback: https://arxiv.org/abs/2009.01325
[2]Sparrow-Improving alignment of dialogue agents via targeted human judgements: https://arxiv.org/abs/2209.14375
[3]Constitutional AI- Harmlessness from AI Feedback: https://arxiv.org/abs/2212.08073
[4]Pretraining Language Models with Human Preferences: https://arxiv.org/abs/2302.08582
作者简介:我是朋克又极客的AI算法小姐姐rumor,北航本硕,NLP算法工程师,谷歌开发者专家
本文来自微信公众号:李rumor(ID:leerumorr),作者:rumor