
本文来自微信公众号:李rumor(ID:leerumorr),首发于2022年12月9日,作者:rumor,题图来自:《终结者3》
卷友们好,我是rumor。
2022年12月1日,在国内微信朋友圈还没刷屏的时候,我就看到ChatGPT发布的消息了,当时迅速看了下博客内容,心想:就这?这不跟DeepMind的Sparrow一样吗?而且设计得还没它好,Sparrow专门设计了一个可控的防攻击机制:
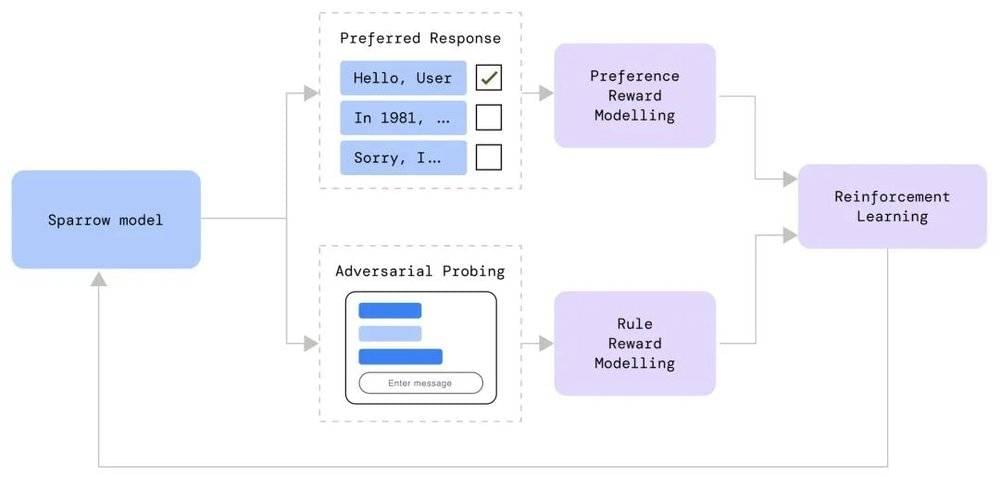
图源:DeepMind
当时也懒得去注册账号,就快速写了篇技术解读完事了。
没想到周末的时候,这个声势越来越浩大,我赶紧跟风去买了个账号聊了一会,那时我的心情变成了:“卧槽?”虽然我能挑出一些刺儿,但这也太牛了。
接下来的两三天里,我的世界都被ChatGPT打满了,看了一堆大家的截图,又看一了堆大佬的解读,再着急地刷了InstructGPT的论文,然后我开始焦虑了。甚至看到ChatGPT这几个字都有点PTSD。
可能跟我的性格有关系,我开始陷入了自我否定,觉得自己这几年都在做啥,我什么时候才能搞个ChatGPT出来。虽然我也知道这不是我一个人的事情,也不是一个部门或者一家公司的事情,而是跟整个互联网行业的价值导向相关。
直到晚上,我才突然想清楚,我焦虑的原因不只是因为“它太好了”,而是“我们可能追不上OpenAI了”。
首先,它的效果除了来自大家公认的数据质量高之外,我觉得还有一点,那就是OpenAI真的把对话的闭环跑起来了。
比如在搜索系统里,用户的大量点击行为可以作为反馈,来不断提升排序模型的效果,而对话系统回答的是文字,自然没法统计点击率。即使加个点赞点踩的功能,也只有很少的人会点,而且对于智能客服、任务型系统来说,用户往往是看心情而不是答案对错。这样就导致大部分系统都是靠一些间接指标,或者定期抽取数据去人工评估对话效果,评估完后的数据,也不一定会被拿来优化模型,可能直接加词表或者配置标准问题就完事了。
OpenAI也没能解决这个用户行为反馈的问题,但他们构造了另一种持续成长的闭环:
优化生成模型—采样用户Prompt—人工标注答案排序——训练更契合当前用户群体的RM——用RM去优化生成模型。
那么多公司都发布过对话模型,但大部分都是toy阶段,而OpenAI坚持了下来,并且在一年的时间里,经过数次迭代从InstructGPT[1]进化到了ChatGPT。而且随着用户量(已经在2023年1月破亿)和消息量的上涨,他们会更好地拟合人类的Prompt分布。
这就是令我焦虑甚至有点害怕的地方,还有一个词可以概括这个可能会发生的现象,那就是马太效应。

对于AI来说,算力、模型都不是壁垒,数据才是。用ChatGPT的人越多,它的效果就越好,从而吸引更多用户。并且在这个迭代过程中,我们现在说的各种问题都会迎刃而解,无非是哪个版本发布而已。(连我都知道加个搜索引擎API能提升知识问答表现,OpenAI会不知道吗?手动狗头。)
这就是令我真正焦虑的地方。以往的BERT、大模型都没关系,无非是拿开源框架、开源数据、几张卡和人力训练几个月而已。但这次OpenAI在数据和用户数量上都形成了很强的壁垒,我仔细看了下InstructGPT的论文,虽然只有十万左右的Prompt,但雇了40人的外包团队,标注文档就写了16页[2],每个任务除了问最终答案外,还会问许多其他问题:
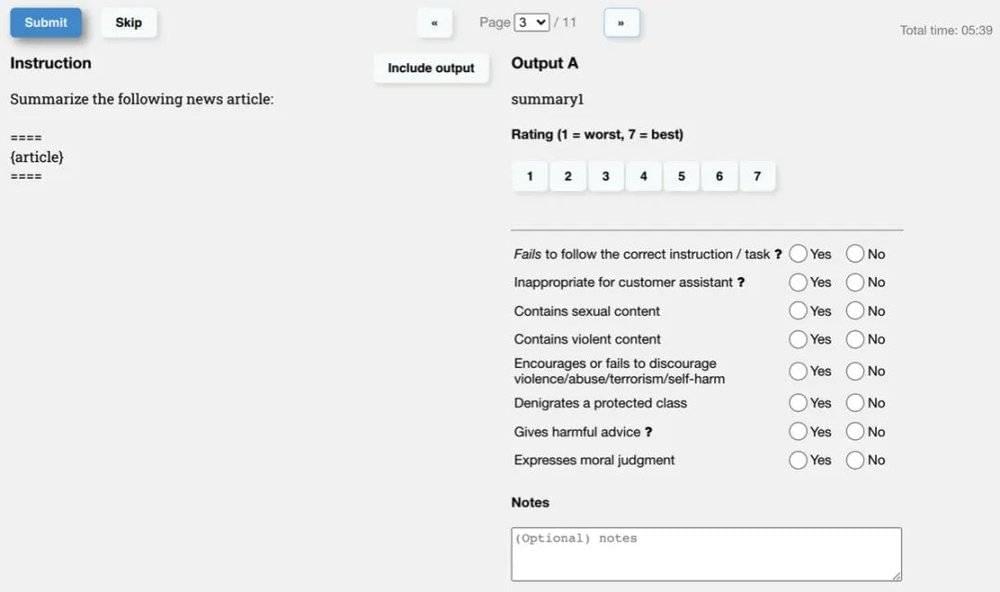
图源:InstructGPT标注文档
这,还只是他们年初时候的情况。
如果真到了商用智能助理/RPA那一步,用户是选择高价但真能提效的产品,还是低价却只有70-80%执行准确率的产品?
以上,就是我最近的一些担忧,如有不同意见欢迎留言讨论。大家也别被我带的那么焦虑,我只是设想了最坏的情况,虽然商业世界不乏垄断,但更多行业还是几个巨头或者一堆小厂并存的状态。
OpenAI是一个强大的公司,它一次次地把事情从0做到1,除了算法创新和构造数据的认真外,他们研究团队的视野、决心也都值得我们学习。
参考资料:
[1]Aligning Language Models to Follow Instructions: https://openai.com/blog/instruction-following/
[2]InstructGPT标注文档: https://docs.google.com/document/u/1/d/1MJCqDNjzD04UbcnVZ-LmeXJ04-TKEICDAepXyMCBUb8/
作者介绍:我是朋克又极客的AI算法小姐姐rumor,北航本硕,NLP算法工程师,谷歌开发者专家
本文来自微信公众号:李rumor(ID:leerumorr),作者:rumor