
本文来自微信公众号:腾讯研究院 (ID:cyberlawrc),首发于《新经济导刊》2022年第4期,作者:曹建峰、陈楚仪,原文标题:《ChatGPT爆火背后,再看合成数据与人工智能的未来》,题图来自:《西部世界》
随着ChatGPT持续火爆,背后的大型语言模型(LLM)和生成式AI技术(Generative AI)日益备受关注。AI领域的新一轮竞赛已然开始,微软、谷歌等已在搜索引擎领域展开角逐,将ChatGPT能力融入搜索服务。
AIGC浪潮下,除了ChatGPT等面向终端用户的应用形态,生成式AI和AIGC技术更广阔的应用空间将是产业互联网领域,基于生成式AI和AIGC技术的合成数据,将成为人工智能技术在各行各业应用普及和能力提升的核心要素,支撑人工智能未来发展。
而且,有研究预测,到2026年ChatGPT等大型语言模型的训练就将耗尽互联网上的可用文本数据,届时将没有新的训练数据可供使用。因此,未来也需要借助合成数据解决ChatGPT等AIGC模型的潜在数据瓶颈,推动进一步发展。
在过去的2022年,AIGC(AI-Generated Contents,人工智能生成内容)无疑是最引人瞩目的科技关键词,从引爆AI作画领域的DALL-E 2、Stable Diffusion等AI模型,到以ChatGPT为代表的接近人类水平的对话机器人,人工智能正加速实现从感知、理解世界到生成、创造世界的跃迁。
以AIGC这一加速扩张的新疆域为标志,AI领域正在迎来下一个时代。多模态AI模型有望成为继移动互联网之后新的技术平台。而且随着AIGC模型的通用化水平和工业化能力的持续提升,其有望带来一场自动化内容生产与交互变革,引起社会的成本结构的重大改变,进而在各行各业引发巨震。
经过了2022年的预热,2023年AIGC领域将迎来更大发展,AIGC将更趋主流,AIGC内容的类型和质量将不断提升,将有更多的企业主动拥抱AIGC,AIGC领域将诞生全新的职业机会(如提示词工程师)。当然,政府对AIGC的监管也将有所加强。[1]
在数据领域,我国出台的《关于构建数据基础制度更好发挥数据要素作用的意见》提出,顺应经济社会数字化转型发展趋势,推动数据要素供给调整优化,提高数据要素供给数量和质量。在强化数据要素优质供给方面,基于AIGC技术的合成数据将能发挥巨大价值,将以更高效率、更低成本、更高质量为数据要素市场“增量扩容”,助力打造面向人工智能未来发展的数据优势。
因此,产业政策需要着力支持、促进AIGC在产业互联网领域的深入应用,培育、打造合成数据、AIGC等未来产业,持续壮大我国发展人工智能、数字经济、产业互联网等新技术新业态新应用的数据优势。
AIGC技术推动合成数据(synthetic data)领域迎来重大进展
随着AIGC技术持续创新发展,基于AIGC算法模型创建、生成合成数据(synthetic data)迎来重大进展,有望解决AI发展应用过程中的数据限制,进一步推动AI技术更广泛的应用。因此,业界非常看好合成数据的发展前景及其对人工智能未来发展的巨大价值。Forrester、埃森哲(Accenture)[2]、Gartner、CB Insights[3]等研究咨询公司都将合成数据列为人工智能未来发展的核心要素,认为合成数据对于人工智能的未来而言是“必选项”和“必需品”。
例如,Forrester将合成数据和强化学习、Transformer网络、联邦学习、因果推理视为实现人工智能2.0的五项关键技术进展,可以解决人工智能1.0所面临的一些限制和挑战,诸如数据、准确性、速度、安全性、可扩展性等。[4]
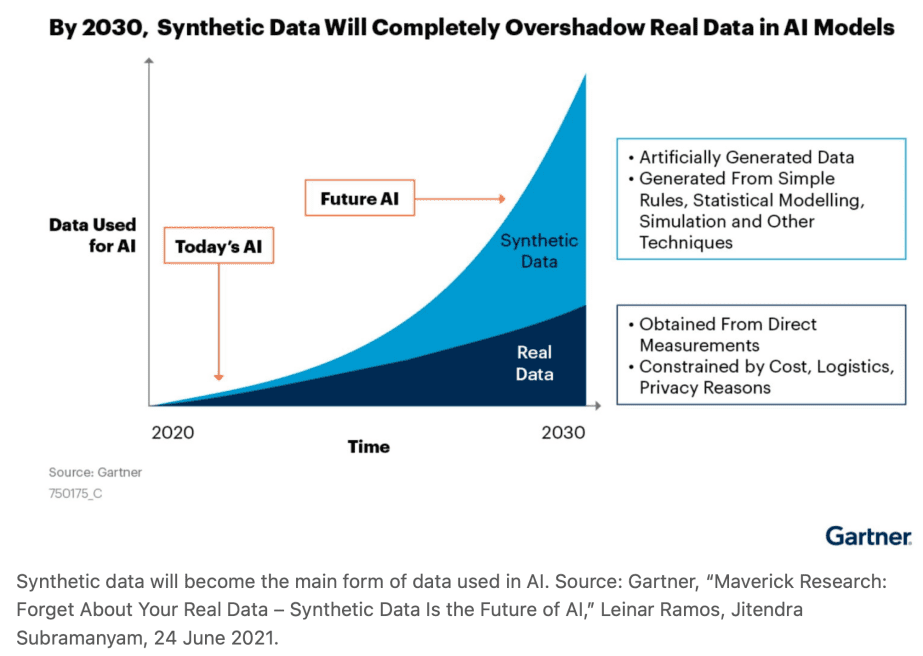
Gartner预测称,到2030年合成数据将彻底取代真实数据,成为AI模型所使用的数据的主要来源。[5]MIT科技评论将AI合成数据列为2022年十大突破性技术之一,称其有望解决AI领域的数据鸿沟问题。[6]数据是人工智能的燃料和驱动力,合成数据将极大拓展人工智能发展应用的数据基础,可以认为,合成数据关乎人工智能的未来。
在概念上,合成数据是计算机模拟(computer simulation)技术或算法创建、生成的自标注信息,可以在数学上或统计学上反映真实世界数据的属性,因此可以作为真实世界数据的替代品,来训练、测试、验证AI模型。简而言之,合成数据是在数字世界中创造的,而非从现实世界收集或测量而来。[7]合成数据拥有很长的历史,在其发展过程中技术不断创新。
例如,游戏引擎、3D图形等模拟技术(simulation technology)可以创建高保真的仿真物体和仿真环境,而结合了AI技术的3D-AI技术则可以极大提升自动化生产3D内容的效率和保真度(fidelity)。得益于生成对抗网络(GAN)、变分自编码器(VAE)、Transformer模型、扩散模型(Diffusion Model)、神经辐射场模型(NeRF)等不断涌现的AI算法,不仅合成数据的种类得到了扩展,而且其质量也不断得到提升。
就目前而言,合成数据大致可分为三类:表格数据/结构化数据,图像、视频、语音等媒体数据,以及文本数据。[8]这几类合成数据在多个领域都有应用。AIGC技术的持续创新,让合成数据迎来新的发展契机,开始迸发出更大的产业发展和商业应用活力。目前主要呈现以下四个方面的发展趋势。
合成数据为AI模型训练开发提供强大助推器,推动实现AI2.0
人工智能的发展应用离不开数据,但真实世界数据面临着难以获取、质量差、标准不统一等诸多问题。为此,计算机模拟技术或算法生成的合成数据,作为真实数据数据的廉价替代品,日益被用于创造精准的AI模型。
合成数据服务商AI.Reverie指出,人工标注一张图片可能需要6美元,但人工合成的话只需要6美分。2019年的一篇论文《合成数据用于深度学习》(synthetic data for deep learning)认为,合成数据是现代深度学习领域冉冉升起的最具前景的通用技术之一,尤其对于依赖于图像、视频等非结构化数据的计算机视觉技术而言;并认为合成数据对于人工智能的未来发展至关重要。[9]
而且,研究表明在AI模型的训练开发上,合成数据相比基于真实物体、事件或人物的数据,可以发挥同样好甚至更好的效果。[10]
总之,合成数据技术可以实现更廉价、更高效地批量生产制造AI模型训练开发所需的海量数据(诸如训练数据、测试数据、验证数据等等),作为对真实数据的替代或补充,将推动人工智能迈向2.0阶段,从本质上扩展AI的应用可能性。
可以说,目前人工智能仍处在1.0阶段(AI1.0),数据是最大掣肘,业界利用真实世界数据训练AI模型面临多方面问题:数据采集、标注费时费力、成本高企;数据质量较难保障;数据多样化不足,难以覆盖长尾、边缘案例,或者特定数据在现实世界中难以采集、不方便获取;数据获取与使用、分享等面临隐私保护挑战和法规限制,等等。这些数据方面的限制在很大程度上阻碍了人工智能更广泛的应用和部署。
合成数据有望解决这些问题,推动人工智能迈向2.0阶段(AI2.0),可以在更大程度上拓展人工智能的应用。在AI2.0阶段,人们不仅可以利用合成数据更高效地训练AI模型,而且可以让AI在合成数据构建的虚拟仿真世界中自我学习、进化,这将极大扩展AI的应用可能性。具体而言,对于人工智能而言,合成数据可以发挥诸多价值:
(1)实现数据增强和数据模拟,解决数据匮乏、数据质量等问题,包括通过合成数据来改善基准测试数据(benchmark data)的质量等;
(2)避免数据隐私/安全/保密问题,利用合成数据训练AI模型可以避免用户隐私问题,这对于金融、医疗等领域而言尤其具有意义;
(3)确保数据多样性,更多反映真实世界,提升AI的公平性,以及纠正历史数据中的偏见,消除算法歧视;
(4)应对长尾、边缘案例,提高AI的准确性、可靠性,因为通过合成数据可以自动创建、生成现实世界中难以或者无法采集的数据场景,更好确保AI模型的准确性;
(5)提升AI模型训练速度和效果。总之,利用合成数据可以更廉价、更高效、更准确、更安全可靠地训练AI模型,进而极大扩展AI的应用可能性,将人工智能推向新的发展阶段。
合成数据助力破解AI“深水区”的数据难题,持续拓展产业互联网应用空间
合成数据早期主要应用于计算机视觉领域,因为计算机视觉被广泛应用于自动驾驶汽车、机器人、安防、制造业等领域,在这些应用场景中打造AI模型都需要大量的被标注的图像、视频数据。但获取现实数据往往并非易事。
以自动驾驶汽车为例,由于实际道路交通场景千变万化,让自动驾驶汽车通过实际道路测试来穷尽其在道路上可能遇到的每一个场景是不现实的,必须借助于合成数据才能更好地训练、开发自动驾驶系统。为此,自动驾驶企业开发了复杂的仿真引擎来“虚拟地合成”自动驾驶系统训练所需的海量数据,并高效地应对驾驶场景中的“长尾”问题和“边缘案例”。
在安全的、合成的仿真环境中,计算机可以模拟任何人类想象得到的驾驶场景,诸如调节天气状况、添加或移除行人、改变其他车辆的位置等等。可以说,合成数据和仿真技术是自动驾驶的核心支撑技术。最早涌现的一批合成数据创业公司就瞄准的是自动驾驶汽车市场,帮助自动驾驶企业解决其在自动驾驶系统开发过程中所面临的数据和测试难题。
目前,合成数据正迅速向金融、医疗、零售、工业等诸多产业领域拓展应用。合成数据在金融服务领域的探索仍处于早期且不断拓展,并且受到咨询公司、金融巨头和监管机构的关注。
合成数据背后的生成式AI被Gartner评为2022年银行和投资服务领域越来越受欢迎的三项技术之一。[11]生成性AI受欢迎的原因是能够通过合成数据以成本更低、易规模化、隐私保护合规的方式提供接近真实世界的数据。
而在银行和投资服务领域,生成对抗网络(GAN)和自然语言生成(NLG)的应用可以在大多数欺诈检测、交易预测、合成数据生成和风险因素建模的场景中找到。例如,美国运通(America Express)利用GAN创建合成数据来训练、优化其进行欺诈检测的AI模型。谷歌利用AI生成的医疗记录来帮助预测保险诈骗(insurance fraud)。
摩根大通(J.P.Morgan)2021年9月在其官网发布相关研究,提出通过生成合成数据集加快金融服务领域的AI研究和模型开发,来改善服务体验、解决欺诈检测和反洗钱等重要问题。[12]国外金融服务业所产生的大量真实数据因为法律限制(如欧盟的GDPR和美国的CCPA)和隐私保护要求无法使用或使用存在诸多限制。
合成数据创造的新样本具有真实数据的性质,增加真实数据中的罕见样本,以便更有效地训练机器学习算法。一个关键的领域是欺诈检测模型训练。由于欺诈性案件的数量与非欺诈性案件相比较十分稀少,研究人员很难有效地从可用数据中训练模型,导致无法针对欺诈性行为进行建模。然而,合成数据可以生成比实际数据中欺诈案例比例更高的合成数据样本,用于帮助改进模型训练。
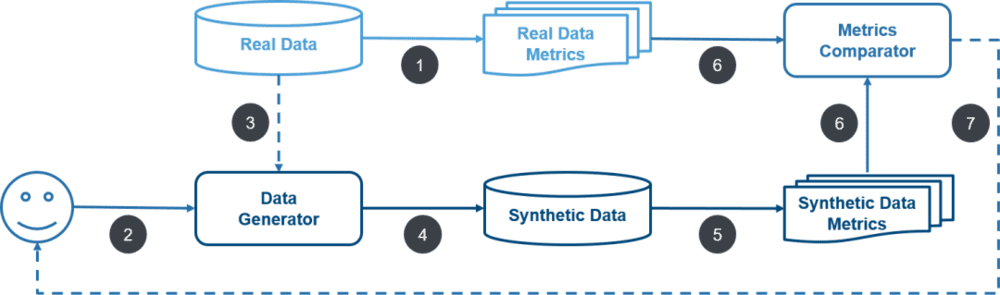
英国金融行为监管局(Financial Conduct Authority,FCA)也积极跟进合成数据作为一项隐私保护技术在金融行业的应用前景。FCA在2022年3月的公开报告中指出,合成数据通过生成统计学上真实(statistically realistic)的但“人造”(artificial)的数据,为数据共享提供更多的机会。技术的应用有利于提供更普及、更高效、更好提升消费者体验的金融服务,目前的应用领域包括:金融犯罪和欺诈预防、信用评分、销售和交易、保险产品定价和索赔管理、资产管理和组合优化等。
值得注意,合成数据也存在通过逆向工程来获取真实数据的风险,对数据隐私保护而言并非完美的解决方案。[13]为此,FCA已经通过公开征求意见来了解业界对合成数据支持创新的潜力和满足企业有效需求的看法以及潜在的限制和风险。
在医疗领域,医疗影像的合成数据正对医疗AI领域的发展产生巨大推动作用。例如,创业企业Curai基于仿真的医疗案例数据训练了一个医疗诊断模型,表明合成的医疗数据同样可以用于支持医疗AI应用的开发。美国生物技术公司Illumina和合成数据创业公司Gretel合作,利用合成的基因组数据来进行医学研究,以避免限制性立法、病人同意等问题,这些问题阻碍医学研究的速度和规模。
另一个典型的例子是将合成数据用于新冠肺炎相关的医学研究。为了对抗新冠肺炎,研究人员需要获取足够的病例数据来开展研究,但出于隐私保护等顾虑,研究人员在获取新冠肺炎相关的病例数据时面临不小的困难。
为此,美国国立卫生研究院(NIH)和Syntegra、MDClone等合成数据服务商合作,基于其Covid-19病人病历数据库“全国新冠合作群组”(National COVID Cohort Collaborative,N3C)中超过500万个新冠阳性个体的病例数据,合成了不具有可识别性的替代数据,即合成的Covid-19数据。合成数据精确地复制了原始数据集的统计特征,但与原始数据不存在任何关联,可以被世界范围内的研究人员自由分享和使用,用于开展研究发现、疾病治疗、疫苗开发等方面的工作。
在零售领域,创业公司Caper可以基于一个商品的几张图片,利用3D模拟技术创建含有上千个图片的合成数据集,进而支持智慧零售店。在工业领域,FORD利用游戏引擎和GAN来创造合成数据训练AI模型。此外,合成数据还可帮助应对算法歧视等AI伦理问题,支持打造更公平、可信的AI模型,因为合成数据可以帮助消除AI数据集中的偏见因素,支持构建更具包容性的、代表性的高质量数据集。
合成数据产业加快成为数据要素市场新赛道,科技大厂和创新企业抢先布局
合成数据对人工智能未来发展的巨大价值使其加速成为AI领域的一个新产业赛道。一方面,国外的主流科技公司纷纷瞄准合成数据领域加大投入与布局。英伟达[14]是典型代表,其元宇宙平台Omniverse拥有合成数据能力omniverse replicator;omniverse replicator作为Omniverse平台的一部分,是为AI算法训练生成具有物理属性的合成数据的技术引擎,有两项代表性应用。
一是在Omniverse平台中创建用于机器人训练的虚拟环境Issac SIM平台[15],在这个虚拟环境中训练的机器人之后可以直接应用于现实世界,即这个机器人可以将在虚拟世界中的训练结果同步到现实世界的机器人身上,叠加人工智能的算法,实现机器人的大规模应用。
二是drive SIM平台[16],提供丰富的模拟场景,用于自动驾驶算法训练和验证,如物体识别、车道保持、泊车等自动驾驶汽车应用。Omniverse的这两项合成数据应用可以显著加速机器人和自动驾驶的开发进程。
微软的Azure云服务则推出了airSIM平台,可以创建高保真的(high fidelity)的3D虚拟环境来训练、测试AI驱动的自主飞行器;[17]微软还开发了可以生成合成和聚合数据集的开源工具Synthetic Data Showcase,并创建了合成人脸数据库,和国际移民组织(IOM)合作打击人口贩卖。
亚马逊在多个场景探索合成数据的应用,例如使用合成数据来训练、调试其虚拟助手Alexa,以避免用户隐私问题;其合成数据技术Wordforge工具可以用来创建合成场景(synthetic scenes);在2022年的亚马逊re:MARS大会上,其数据标注服务SageMaker Ground Truth推出了合成数据能力,可以自动生成标注的合成图片数据,即该工具可以就特定物体创建不同位置和不同灯光条件的图片,以及不同比例和其他变化的图片。
Meta(原Facebook)也着力于为其人工智能业务增强合成数据能力,2021年11月收购了合成数据创业公司AI.Reverie。
另一方面,合成数据作为AI领域的新型产业,相关创新创业方兴未艾,合成数据创业公司不断涌现,合成数据领域的投资并购持续升温,开始涌现了合成数据即服务(synthetic data as a service,SDaaS)这一发展前景十分广阔的全新商业模式。[18]
据国外研究者统计,目前全球合成数据创业企业已达100家。[19]比较知名、有影响力的包括AI.Reverie、datagen、sky engine、mostly.ai、synthesis AI、gretel.ai、one view、innodata、cvedia等等。在过去的18个月,公众视野中已知的合成数据公司融资总额达到3.28亿美元,比2020年高出2.75亿美元。
合成数据的创业赛道主要涵盖非结构化数据(图片、视频、语音等)、结构化数据(表格等)、测试数据(test data)、开源服务等几大方向。其中,非结构化合成数据持续保持强劲发展势头,这主要得益于以下几个因素:
第一,计算机视觉应用场景相对成熟;
第二,有游戏引擎(game engines)、图像建模软件、AIGC技术的支撑;
第三,自动驾驶汽车、零售、电子游戏等快速发展的产业对合成数据有较高需求。
目前结构化数据合成和测试数据合成正在迅猛发展,尤其是合成的测试数据更少受到数据隐私立法的限制,所以开始受到业界青睐。此外,合成数据开源服务也在快速发展,例如synthetic data vault、synner、synthea、synthetig等。

市场规模方面,根据Cognilytica的数据,合成数据市场规模在2021年大概是1.1亿美元,到2027年将达到11.5亿美元。Grand View Research预测,AI训练数据市场规模到2030年将超过86亿美元。Gartner预测,到2024年用于训练AI的数据中有60%将是合成数据,到2030年AI模型使用的绝大部分数据将是人工智能合成的。可以预见,合成数据作为数据要素市场的新增量,在创造巨大商业价值的同时,也有望解决人工智能和数字经济的数据供给问题。
合成数据加速构建AI赋能数实融合的大型虚拟世界
合成数据指向的终极应用形态是借助游戏引擎、3D图形、AIGC技术构建的数实融合的大型虚拟世界。大型虚拟世界对于人工智能的核心价值在于,为测试、开发新的人工智能应用,提供了一个安全、可靠、高效以及最重要的是——低成本的、可重复利用的环境。展望未来,可以从三个方面来理解基于合成数据构建的大型虚拟世界为什么成为AI数实融合的关键场景。
第一,大型虚拟世界可以提供人工智能开发所需的数据和场景,为AI应用开发提供“加速度”。
游戏开发者、发行者已经意识到了这一机遇,即为AI系统设计游戏般的虚拟世界。例如,《星际争霸》、《我的世界》等游戏是人工智能的理想的测试场地,3A游戏场景资产也是生成性AI工具的重要潜在应用。
第二,大型虚拟世界为各行各业训练开发AI提供了试验田。
这个方面的一个典型例子就是用于自动驾驶算法测试的虚拟仿真平台。谷歌、英伟达、腾讯等国内外科技公司都在大力布局自动驾驶仿真业务,即提供一个仿真的合成世界来训练、测试自动驾驶算法。在国内,腾讯自动驾驶实验室开发的自动驾驶仿真平台TAD Sim,可以让自动驾驶算法在城市级别的虚拟仿真世界中进行测试和学习,极大降低了自动驾驶汽车的研发成本。
在国外,自动驾驶企业Waabi希望主要通过虚拟仿真而非实际道路测试来训练其自动驾驶系统,构建了Waabi World这一用于自动驾驶系统的大型虚拟世界,其核心即是合成数据和合成场景。Waabi World不仅可以接近实时地模拟汽车的传感器,而且模拟的环境可以和人工智能之间可以相互做出反应。这是非常重要的,因为自动驾驶汽车不仅需要感知世界,还需要安全地采取行动。大型虚拟世界提供了这样一个安全有效且可重复使用的试验田。
第三,在大型虚拟世界中通过AI连通虚拟与现实,实现AI数实融合。
在大型虚拟世界,如游戏虚拟世界或者其他的仿真的3D合成世界(simulated synthetic world)中训练AI虚拟机器人,让其自我学习、进化,然后部署到现实世界中,产生现实的价值。
此外,大型虚拟世界对强化学习和其他AI算法也具有巨大价值,例如,游戏世界是开展AI强化学习和多智能体协作的最佳载体;也可以在大型虚拟世界中利用虚拟人开发更宜居的建筑设计;大型虚拟世界如果可以仿真物理现象,就可进行虚拟化学实验,相比人类利用真实的化学药品开展实验,软件可以利用虚拟的化学药品更高效、更安全、更大规模地开展化学实验。
总之,大型虚拟世界对于支持人工智能研究开发、促进数实融合的巨大可能性,值得持续深挖和不断探索。
参考资料来源
[1]https://www.fastcompany.com/90827749/where-is-generative-ai-headed-in-2023.
[2]https://www.accenture.com/_acnmedia/Thought-Leadership-Assets/PDF-5/Accenture-Meet-Me-in-the-Metaverse-Full-Report.pdf.
[3]https://www.cbinsights.com/research/report/ai-trends-2022/.
[4]https://www.techrepublic.com/article/aws-ibm-google-and-microsoft-are-taking-ai-from-1-0-to-2-0-according-to-forrester/.
[5]https://www.gartner.com/en/newsroom/press-releases/2022-06-22-is-synthetic-data-the-future-of-ai.
[6]https://www.technologyreview.com/2022/02/23/1044965/ai-synthetic-data-2/.
[7]https://blogs.nvidia.com/blog/2021/06/08/what-is-synthetic-data/.
[8]https://medium.com/@adrialsina/is-synthetic-data-the-future-of-ai-exploring-enterprise-use-cases-eb0f7152fe9e.
[9]https://arxiv.org/pdf/1909.11512.pdf.
[10]https://news.mit.edu/2022/synthetic-data-ai-improvements-1103.
[11]https://www.gartner.com/en/newsroom/press-releases/2022-05-24-gartner-identifies-three-technology-trends-gaining-tr.
[12]https://www.jpmorgan.com/technology/technology-blog/synthetic-data-for-real-insights.
[13]https://www.fca.org.uk/publication/call-for-input/synthetic-data-to-support-financial-services-innovation.pdf.
[14]https://nvidianews.nvidia.com/news/nvidia-announces-omniverse-replicator-synthetic-data-generation-engine-for-training-ais.
[15]https://developer.nvidia.com/isaac-sim.
[16]https://blogs.nvidia.com/blog/2021/11/09/drive-sim-replicator-synthetic-data-generation/.
[17]https://news.microsoft.com/innovation-stories/microsoft-launches-project-airsim-an-end-to-end-platform-to-accelerate-autonomous-flight.
[18]https://www.washingtonpost.com/business/ais-next-big-thing-is-fake-data/2022/06/27/d1a2e4f0-f5d6-11ec-81db-ac07a394a86b_story.html.
[19]https://elise-deux.medium.com/everything-that-happened-in-the-synthetic-data-space-in-2022-c5d6cb5aaf06.
本文来自微信公众号:腾讯研究院 (ID:cyberlawrc),作者:曹建峰、陈楚仪,首发于国务院发展研究中心主管的《新经济导刊》2022年第4期,原标题为《AIGC浪潮下,合成数据关乎人工智能的未来》