
本文来自微信公众号:机器之心 (ID:almosthuman2014),编辑:蛋酱、陈萍,原文标题:《MusicLM来了!谷歌出手解决文本生成音乐问题,却因copy风险不敢公开发布》,题图来自:视觉中国
谷歌继续向音乐领域发起挑战!近日,谷歌发布的 MusicLM 模型简直是生成音乐界的小能手,会的乐曲五花八门,你能想到的,它都会满足。
MusicLM 不是第一个生成歌曲的 AI 系统。其他更早的尝试包括 Riffusion,这是一种通过可视化来创作音乐的 AI,以及 Dance Diffusion,谷歌自己也发布过 AudioML,OpenAI 则推出过 Jukebox。
虽然生成音乐的 AI 系统早已被开发出来,但由于技术限制和训练数据有限,还没有人能够创作出曲子特别复杂或保真度特别高的歌曲。不过,MusicLM 可能是第一个做到的。
为什么这么说?
曲风随便选,你要做的就是动动手指输入文本就可以。比如让 MusicLM 来段街机游戏配乐,我们就可以输入文本“街机游戏的主配乐,音乐给人的感受节奏快且乐观,带有朗朗上口的电吉他即兴重复段,但又伴随着意想不到的声音,如铙钹撞击声或鼓声”。
还想让 MusicLM 来段电子舞曲,也没问题,输入提示“雷鬼和电子舞曲的融合,带有空旷的、超凡脱俗的声音,引发迷失在太空中的体验,音乐的设计旨在唤起一种惊奇和敬畏的感觉,同时又适合跳舞”;或者工作累了,想听听放松的音乐,MusicLM 也能安排。
MusicLM 生成长音乐的质量也很出色:来段轻松的爵士乐,时长可达足足 5 分钟;MusicLM 还有故事模式,你可以要求 MusicLM 在不同的时间段生成不同的音乐风格。例如爵士乐(0:00-0:15)、流行乐(0:15-0:30)、摇滚乐(0:30-0:45)、死亡金属乐(0:45-1:00)、说唱(1: 00-1:15)、弦乐四重奏与小提琴(1:15-1:30)、史诗电影配乐与鼓(1:30-1:45)、苏格兰民歌与传统乐器(1:45-2:00):
MusicLM 也可以通过图片和标题的组合来指导,生成相应风格的音乐。例如拿破仑翻越阿尔卑斯山配乐:

除此以外,MusicLM 还能生成由特定类型的乐器“演奏”的特定流派的音频。甚至可以设置“AI 音乐家”的经验水平,系统可以根据地点、时代或要求创作音乐(例如体育锻炼时的励志音乐)。
有人对这一研究给予极高的评价:这比大火的 ChatGPT 还重要,谷歌几乎解决了音乐生成问题。
MusicLM 肯定不是完美无缺的——事实上,远非如此。一些样本有质量问题,不可避免地对训练过程产生副作用。虽然 MusicLM 在技术上可以生成人声,包括合唱的和声,但它们还有很多地方需要改进。大多数“歌词”可能是蹩脚的英语或纯粹的胡言乱语,然后由合成的声音演唱,听起来像是几个艺术家的“混合物”。

论文主页:https://google-research.github.io/seanet/musiclm/examples/
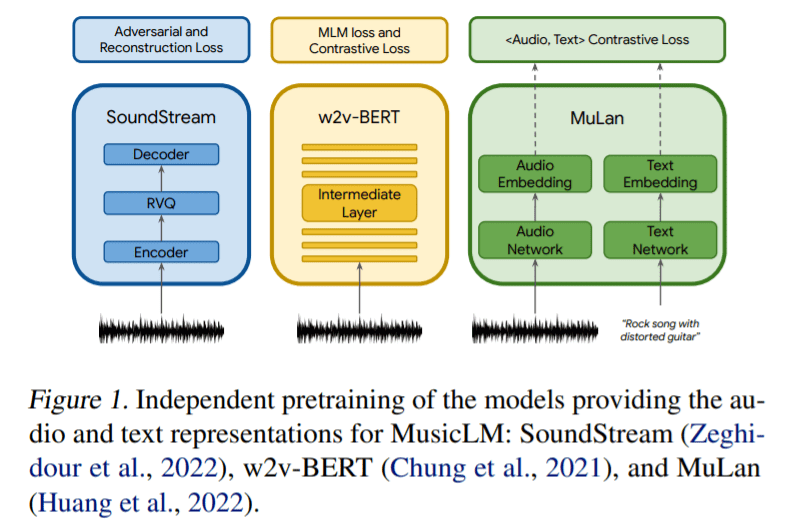
方法层面,谷歌采用三个模型来提取音频表示,这些模型将用于条件自回归音乐生成,如图 1 所示。SoundStream 模型用来处理 24 kHz 单声音频,从而得到 50 Hz 的嵌入;具有 600M 参数的 w2v-BERT 模型用于建模中间层;MuLan 模型用于提取目标音频序列的表示。
然后将上述得到的离散音频表示与 AudioLM 相结合,从而实现基于文本的音乐生成。为了达到这一效果,谷歌提出了一个分层的序列 - 序列建模任务,其中每个阶段都由单独的解码器 Transformer 自回归建模。所提出的方法如图 2 所示。
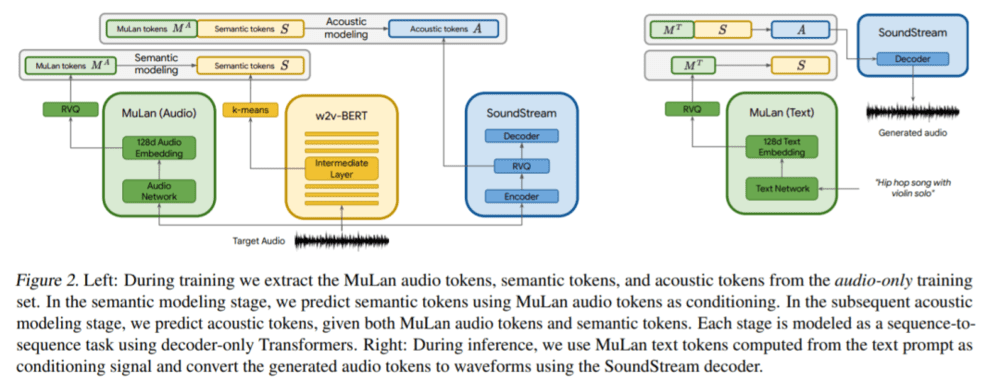
谷歌在 FMA(Free Music Archive)数据集上训练 SoundStream 和 w2v-BERT 模型,而语义和声学建模阶段的 tokenizer 以及自回归模型是在 500 万音频剪辑的数据集上训练的,在 24kHz 下总计 280000 小时的音乐。
实验部分,谷歌将 MusicLM 与文本生成音乐的基线方法 Mubert 、 Riffusion 进行比较。结果显示在 FAD_VGG 指标上,MusicLM 所捕获的音频质量比 Mubert 和 Riffusion 得分更高。在 FAD_Trill 上,MusicLM 的得分与 Mubert 相似(0.44 vs 0.45),优于 Riffusion(0.76)。
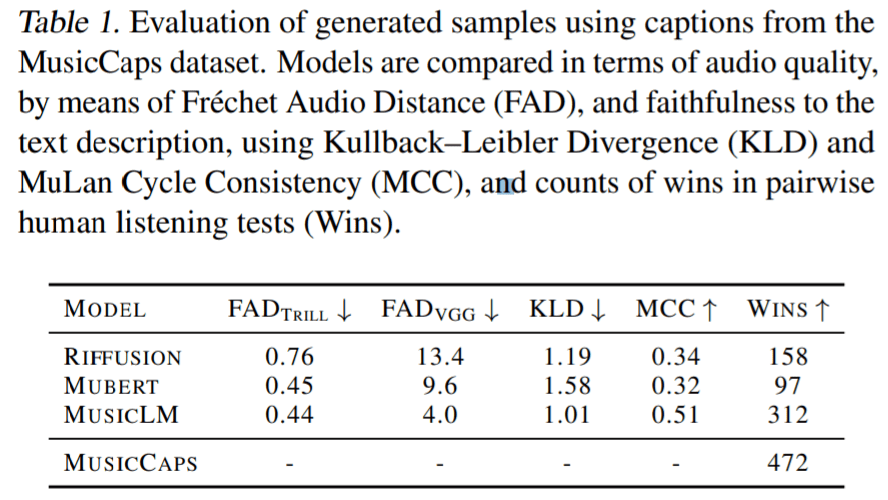
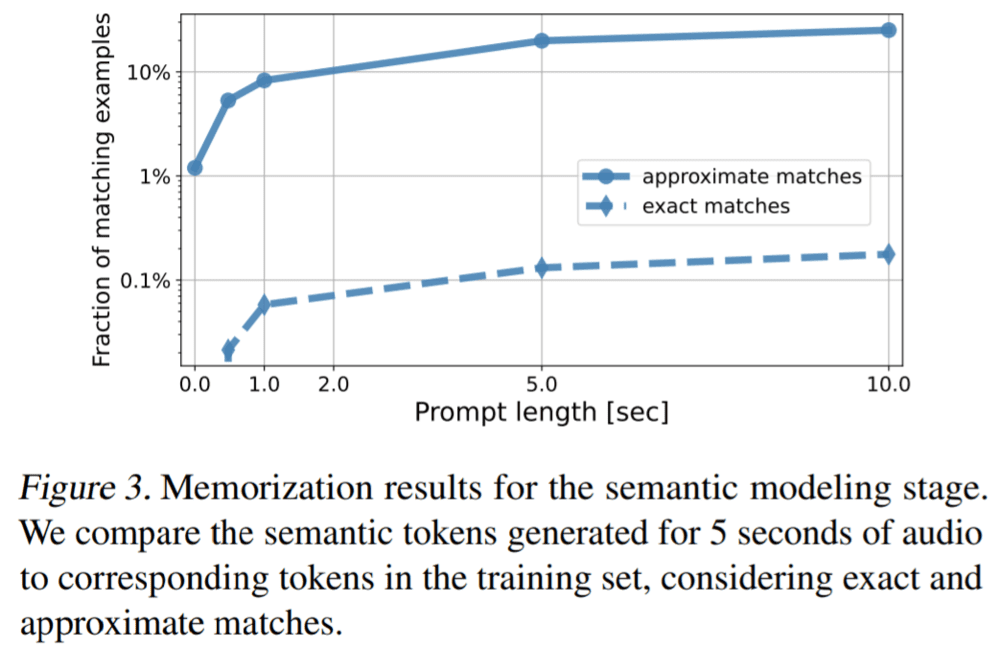
图 3 是对提示长度分析的结果:
饱受争议的生成式 AI
与此同时,谷歌的研究人员也注意到了像 MusicLM 这样的系统所带来的许多道德挑战,包括将训练数据中受版权保护的材料纳入生成的歌曲中的倾向。在一次实验中,他们发现该系统生成的音乐中约有 1% 是直接复制自其训练的歌曲,这个问题足以让研究人员不愿意以目前的状态发布 MusicLM。
“我们承认与该用例相关的盗用创意内容潜在风险”,作者们在论文中写道。“我们强调的是,在解决这些与音乐生成相关的风险方面,未来需要更多的工作。”
假设有一天 MusicLM 或类似的系统可用,似乎仍将不可避免地会出现重大法律问题,即使这些系统被定位为辅助艺术家而不是取代他们的工具。
这类的争议此前已经发生过:2020 年,Jay-Z 的唱片公司对 YouTube 频道 Vocal Synthesis 提出版权警告,理由是它使用 AI 创作了 Jay-Z 翻唱 Billy Joel 的《We Didn't Start the Fire》等歌曲。尽管在删除视频后,YouTube 发现删除请求“不完整”且恢复了它们,但 Deepfake 式的音乐仍然处于模糊的法律基础之上。
Eric Sunray 撰写的一份白皮书认为,像 MusicLM 这样的 AI 音乐生成器通过“从训练摄取的作品中创建连贯音频”侵犯了音乐版权,从而侵犯了美国版权法的复制权。随着 OpenAI 音乐生成神经网络 Jukebox 的发布,批评者也开始质疑在受版权保护的音乐材料上训练 AI 模型是否构成合理使用。围绕图像、代码和文本生成 AI 系统中使用的训练数据也引起了类似的担忧,这些数据通常是在创作者不知情的情况下从网络上收集的。
从用户的角度来看,Andy Baio 推测由 AI 系统生成的音乐将被视为衍生作品,在这种情况下,只有原创元素会受到版权保护。当然,暂不清楚在这种音乐中什么可以被视为“原创”,将这种音乐用于商业用途就像是进入未知水域。如果将生成的音乐用于受合理使用保护的目的,比如模仿和评论,那就更简单了,但预计法院将不得不根据具体情况做出判断。
近期法院审理的几起诉讼可能会对生成音乐的 AI 产生影响,比如微软、GitHub 和 OpenAI 目前在一场集体诉讼中被起诉,指控其 Copilot 违反版权法。
还有一项涉及艺术家的权利,这些艺术家的作品在他们不知情或未同意的情况下被用于训练 AI 系统。流行的 AI 艺术工具幕后的两家公司 Midjourney 和 Stability AI 正被指控通过在网络抓取的图像上训练他们的工具,侵犯了数百万艺术家的权利。就在上周,库存图片供应商 Getty Images 将 Stability AI 告上法庭,据报道,该公司未经许可使用其网站上的数百万张图片来训练 Stable Diffusion。
问题主要在于,生成式 AI 偏好从用于训练它的数据中复制图像、文本等,包括受版权保护的内容。在最近的一个例子中,CNET 用来编写文章的 AI 工具被发现抄袭了人类撰写的文章,这些文章可能在其训练数据集中被清除了。与此同时,2022 年 12 月发表的一项学术研究发现,像 DALL-E-2 和 Stable Diffusion 这样的图像生成 AI 模型,能够且确实从它们的训练数据中复制了图像的各个方面。
因此,一些图片托管平台已经禁止了 AI 生成的内容,因为担心会遭到法律诉讼。几位法律专家警告说,如果公司无意中将这些工具生成的受版权保护的内容整合到他们销售的任何产品中,那么生成式 AI 工具可能会使公司面临风险。
伴随着关注与争议,或许在不远的未来,这些问题都将有清晰的答案。
参考链接
https://techcrunch.com/2023/01/27/google-created-an-ai-that-can-generate-music-from-text-descriptions-but-wont-release-it/
https://techcrunch.com/2023/01/27/the-current-legal-cases-against-generative-ai-are-just-the-beginning/
本文来自微信公众号:机器之心 (ID:almosthuman2014),编辑:蛋酱、陈萍