
本文来自微信公众号:新智元 (ID:AI_era),原文标题:《超级编程AI登上Science封面!AlphaCode编程大赛卷趴一半程序员》,题图来自:视觉中国
这个12月,正当OpenAI的ChatGPT势头正旺时,那个曾经卷趴一半程序员的AlphaCode登上Science封面了!

说到AlphaCode,想必大家并不陌生。早在今年2月,它就在著名的Codeforces上,悄悄地参加了10场编程比赛,并一举击败了半数的人类码农。
卷趴一半码农
我们都知道,程序员中非常流行这样一种测试——编程竞赛。
在竞赛中,主要考察的就是程序员通过经验进行批判性思维,为不可预见的问题创建解决方案的能力。
这体现了人类智能的关键,而机器学习模型,往往很难模仿这种人类智能。
但DeepMind的科学家们,打破了这一规律。YujiA Li等人,使用自监督学习和编码器-解码器转换器架构,开发出了AlphaCode。

虽然AlphaCode也是基于标准的Transformer编解码器架构,但DeepMind对它进行了“史诗级”的强化——
它使用基于Transformer的语言模型,以前所未有的规模生成代码,然后巧妙地筛出了一小部分可用的程序。
具体步骤为:
1)多问询注意力:让每个注意力块共享键和值的头,并同时结合编码器-解码器模型,使AlphaCode的采样速度提高了10倍以上。
2) 掩码语言建模(MLM):通过在编码器上加入一个MLM损失,来提高模型的解决率。
3)回火:让训练分布更加尖锐,从而防止过拟合的正则化效应。
4)值调节和预测:通过区分CodeContests数据集中正确和错误的问题提交,来提供一个额外的训练信号。
5)示范性异策略学习生成(GOLD):通过将训练的重点放在每个问题最可能的解决方案上,让模型为每个问题产生正确方案。
结果嘛,大家都知道了。
凭借着1238的Elo得分,AlphaCode让自己在这10场比赛中的排名达到了前54.3%。放眼之前的6个月,这一成绩更是达到了前28%。
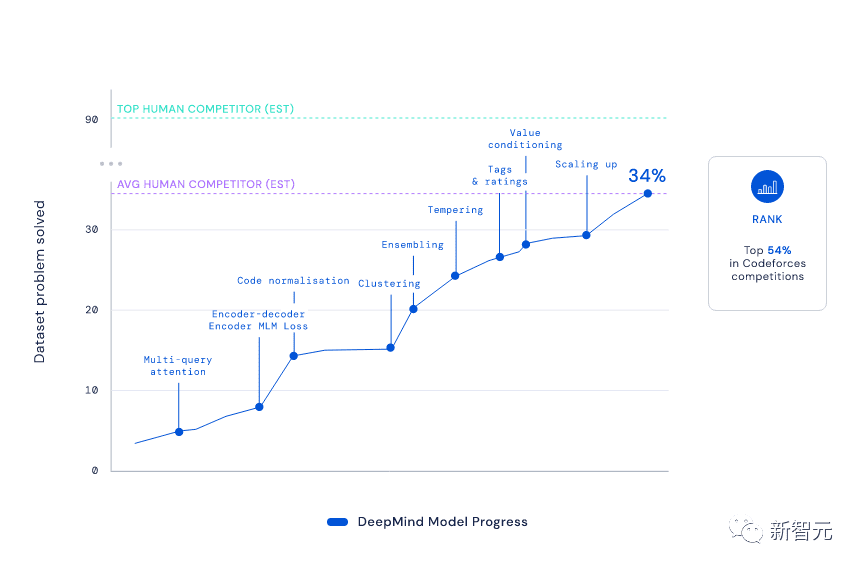
要知道,为了达到这个排名,AlphaCode必须“过五关斩六将”,解决融合了批判性思维、逻辑、算法、编码和自然语言理解相结合的种种新问题。
从结果来看,AlphaCode不仅解决了CodeContests数据集中29.6%的编程问题,而且其中有66%是在第一次提交时解决的。(总提交次数限制在10次)
相比起来,传统的Transformer模型求解率都比较低,只有个位数。
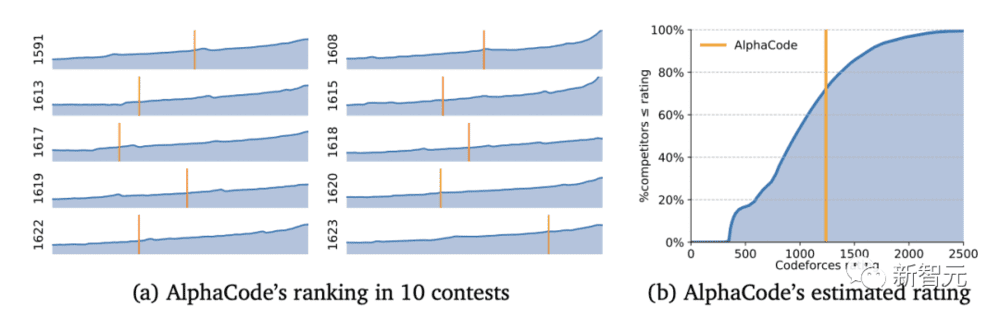
对于这个结果,就连Codeforces创始人Mirzayanov都非常惊讶。
毕竟,编程比赛考验的是发明算法的能力,这一直是AI的弱项,人类的强项。
我可以肯定地说,AlphaCode的结果超出了我的预期。开始我持怀疑态度,因为即使在简单的竞赛问题中,不仅需要实施算法,而且还需要发明算法(这是最困难的部分)。AlphaCode已经让自己成为很多人类的强劲对手。我迫不及待地想知道,未来会发生什么!
——Mike Mirzayanov,Codeforces 创始人
所以,AlphaCode这是能抢程序员的饭碗了?
当然还不行。
AlphaCode还只能完成简单的编程任务,如果任务变得更复杂,问题更加“不可预见”,只会将指令翻译成代码的AlphaCode就束手无策了。
毕竟,1238的得分从某种角度来说,也就相当于一个初学编程的中学生菜鸟的水平。这个level,还威胁不到真正的编程大牛。
但毫无疑问的是,这类编码平台的开发,会对程序员的生产力产生巨大的影响。
甚至,整个编程文化都可能会被改变:或许,以后人类只要负责制定问题就可以,而生成和执行代码的任务,就可以交给机器学习了。
编程竞赛有啥难的?
我们知道,虽然机器学习在生成和理解文本方面取得了巨大进步,但是大部分AI目前仍然局限于简单的数学和编程问题。
它们会做的,更多是检索和复制现有的方案(这一点相信最近玩过ChatGPT的人都深有体会)。
那么,让AI学习生成正确的程序,为什么这么困难呢?
1. 要生成解决指定任务的代码,就需要在所有可能的字符序列中搜索,这是一个海量的空间,而其中只有一小部分对应有效的正确程序。
2. 一个字符的编辑,可能会完全改变程序的行为,甚至会导致崩溃,而且每个任务都有许多截然不同的有效解决方案。
对于难度极高的编程比赛,AI需要理解复杂的自然语言描述;需要对以前从未见过的问题进行推理,而不是简单地记住代码片段;需要掌握各种算法和数据结构,并精确地完成可能长达数百行的代码。
此外,为了评估自己生成的这些代码,AI还需要在一套详尽的隐藏测试上执行任务,并且检查执行速度和边缘情况的正确性。

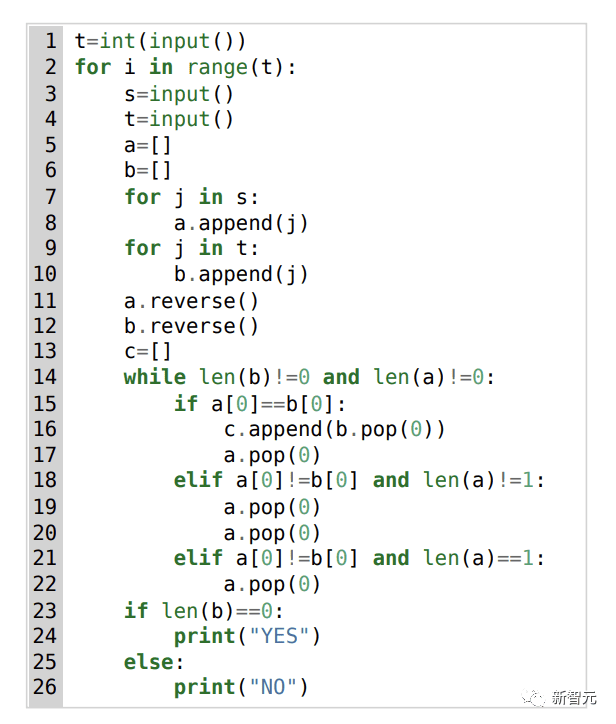
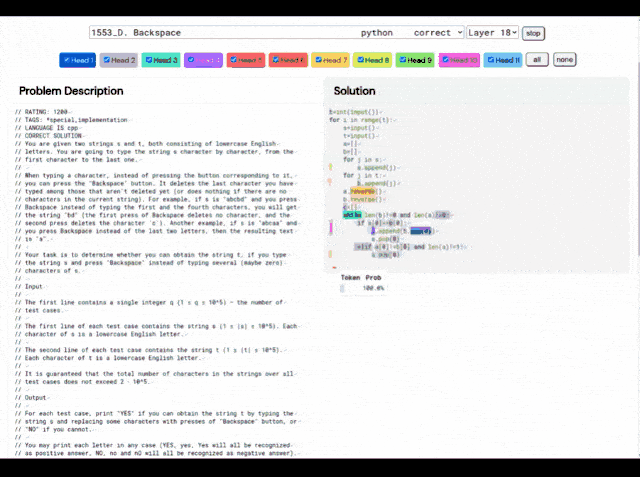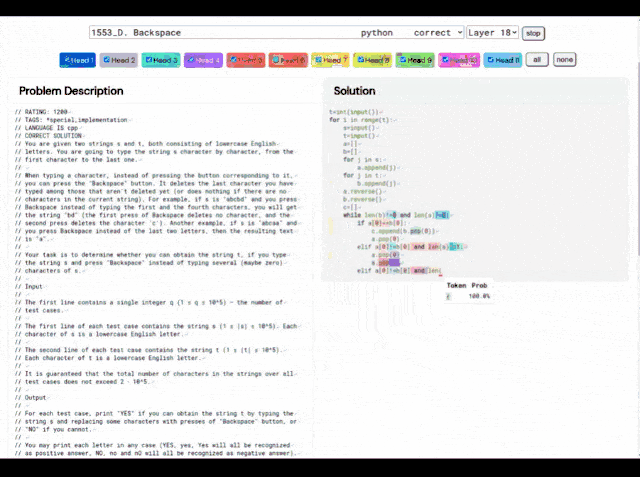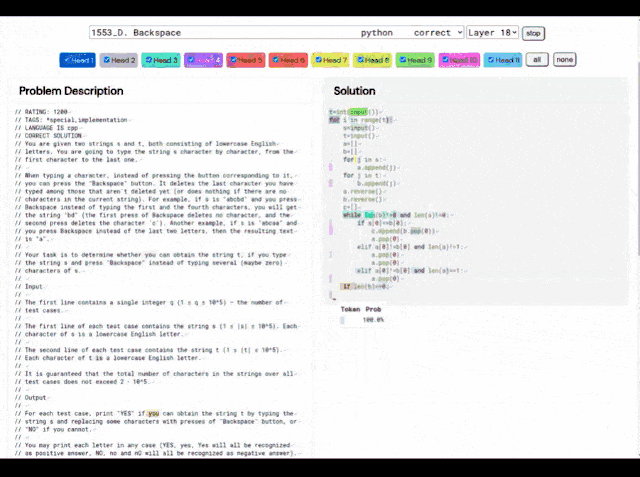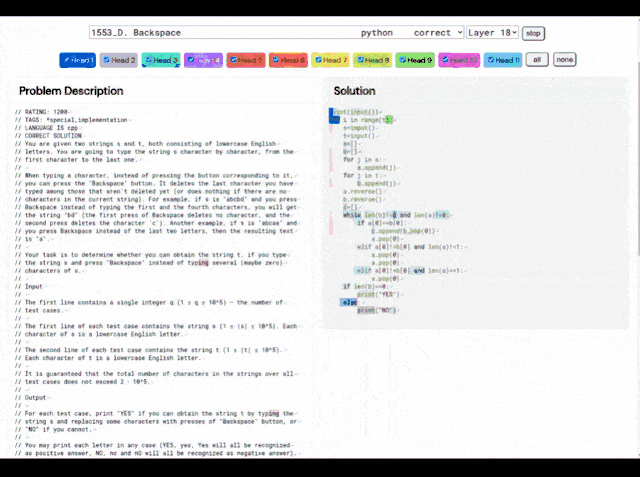
就拿这个1553D问题来说,参赛者需要找到一种方法,使用一组有限的输入将一串随机重复的s和t字母转换成另一串相同的字母。
参赛者不能只是输入新的字母,而必须使用“退格”命令删除原始字符串中的几个字母。赛题具体如下:

对此,AlphaCode给出的解决方案如下:
并且,AlphaCode的“解题思路”也不再是黑箱,它还能显示代码和注意力高亮的位置。
参加编程比赛时,AlphaCode面临的主要挑战是:
(i)需要在巨大的程序空间中搜索;
(ii)只能获得约13000个用于训练的示例任务;
(iii)每个问题的提交数量有限。
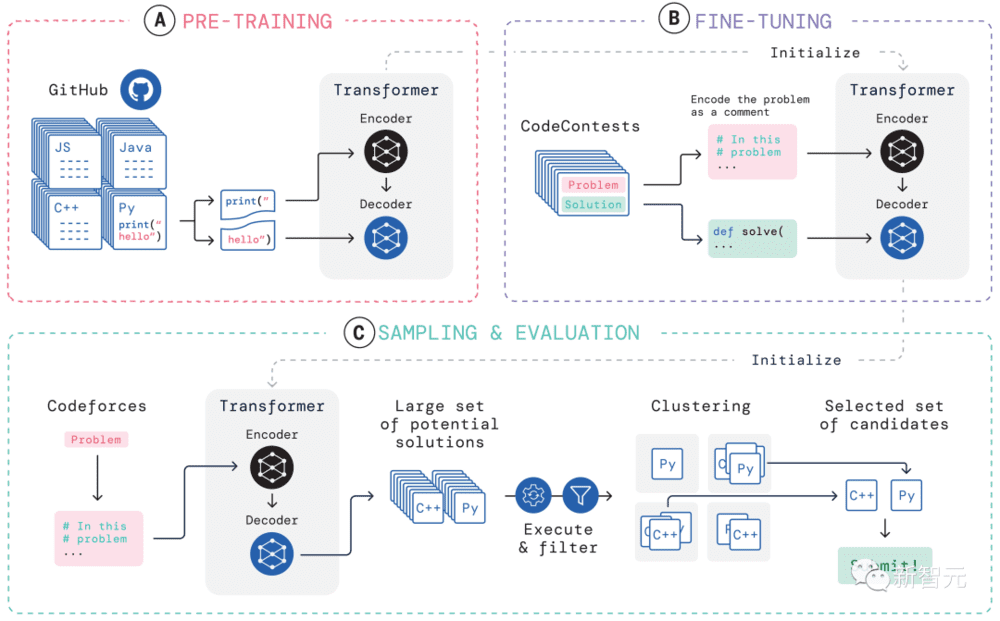
为了应对这些问题,AlphaCode整个学习系统的构建分为三个环节,预训练、微调、采样与评估,如上图所示。
预训练
在预训练阶段,利用在GitHub收集的715GB人类码农的代码快照,对模型进行预训练,并使用交叉熵next-token预测损失。在预训练过程中,随机地将代码文件分成两部分,将第一部分作为编码器的输入,并训练模型去掉编码器生成第二部分。
这种预训练为编码学习了一个强大的先验,使随后的特定任务的微调能够在一个更小的数据集上进行。
微调
在微调阶段,在一个2.6GB的竞争性编程问题数据集上对模型进行了微调和评估,数据集是DeepMind创建的,命名为CodeContests公开发布。
CodeContests数据集中包括问题以及测试案例。训练集包含13328个问题,每个问题平均有922.4个提交答案。验证集和测试集分别包含117个和165个问题。
在微调过程中,将自然语言的问题陈述编码为程序注释,以使其看起来与预训练期间看到的文件更加相似(其中可以包括扩展的自然语言注释),并使用相同的next-token预测损失。
采样
为了选出10个最好的样本进行提交,采用过滤和聚类的方法,利用问题陈述中包含的例子测试来执行样本,并删除未能通过这些测试的样本。
通过过滤筛除了近99%的模型样本,再对剩下的候选样本进行聚类,在一个单独的transformer模型生成的输入上执行这些样本,并将在生成的输入上产生相同输出的程序归为一类。
然后,从10个最大的聚类中各挑选一个样本进行提交。直观地说,正确的程序行为相同,并形成大的聚类,而不正确的程序的失败方式是多种多样的。
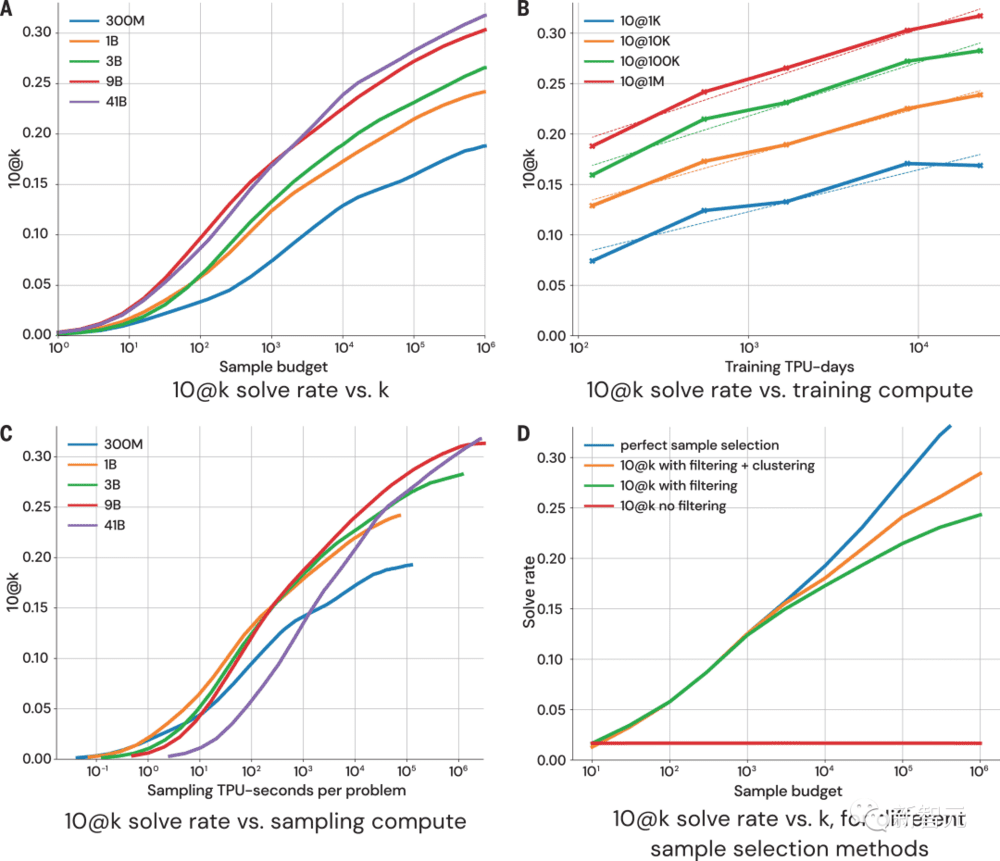
评估
上图所示为在10@k指标上,模型性能是如何随着更多的样本量和计算量而变化的。从对采样结果的性能评估上看,研究人员得出了以下4点结论:
1. 解决率随着更大的样本量而呈对数线性扩展;
2. 更好的模型在比例曲线上有更高的斜率;
3. 解决率与更多的计算量呈对数线性比例;
4. 样本选择对解决率的扩展至关重要。
纯粹的“数据驱动”
毫无疑问,AlphaCode的提出,代表了机器学习模型在发展上已经迈出了实质性的一步。
有趣的是,AlphaCode并不包含关于计算机代码结构的明确的内置知识。
相反,它依靠一种纯粹的“数据驱动”方法来编写代码,也就是通过简单地观察大量现有代码来学习计算机程序的结构。

从根本上说,使AlphaCode在竞争性编程任务上胜过其他系统的原因归结为两个主要属性:
1. 训练数据
2. 候选解决方案的后处理
但计算机代码是一个高度结构化的媒介,程序必须遵守定义的语法,并且必须在解决方案的不同部分中产生明确的前、后条件。
而AlphaCode在生成代码时采用的方法,却和生成其他文本内容时完全一样——一次一个token,并且只在整个程序写完后检查程序的正确性。
鉴于适当的数据和模型的复杂性,AlphaCode可以生成连贯的结构。然而,这个顺序生成程序的最终配方被深埋在LLM的参数中,难以捉摸。
不过,无论AlphaCode是否真的能“理解”编程问题,它的确在代码竞赛方面达到了人类的平均水平。
“解决编程竞赛的问题是一件非常困难的事情,需要人类具有良好的编码技能和解决问题的创造力。AlphaCode能够在这一领域取得进展,给我留下了深刻的印象,我很高兴看到,该模型如何利用其语句理解来生成代码,并引导其随机探索以创建解决方案。”
——Petr Mitrichev,谷歌软件工程师和世界级竞技程序员
AlphaCode在编程竞赛中名列前54%,展示了深度学习模型在需要批判性思维的任务中的潜力。
这些模型优雅地利用现代机器学习,将问题的解决方案表达为代码,这就回到几十年前AI的符号推理根源。
而这,仅仅是一个开始。
在未来,还会诞生更多解决问题的强大AI,或许这一天已经不远了。
参考资料
https://www.science.org/doi/10.1126/science.add8258
https://www.science.org/doi/10.1126/science.abq1158
https://www.deepmind.com/blog/competitive-programming-with-alphacode
本文来自微信公众号:新智元 (ID:AI_era)