
本文来自微信公众号:爱范儿 (ID:ifanr),作者:张成晨,头图来自:unsplash
短短几日,OpenAI 的聊天机器人ChatGPT 席卷了互联网,用户数轻而易举突破百万。
答疑解惑、编写代码、撰写论文、创作诗歌和钢琴曲,当人类绞尽脑汁设下“九九八十一难”,ChatGPT 基本问什么答什么,就算不会也能编得像模像样。
到目前为止,在推向大众的文本生成 AI 里,ChatGPT 是最好的那一个,更何况还免费使用。
当 ChatGPT 春风得意马蹄疾,也有人看到它光环下的失意,程序员和文字工作者的饭碗可能不保,连 Google 等传统搜索引擎也可能被它革了命。
有了搜索引擎,我们依然需要花大量时间翻网页找答案,如果 AI 能直接把答案递到你眼前,还能保证正确率,那岂不是更好?
但问题就在于“如果”。
ChatGPT:我无法与 Google 相比
12 月 1 日,开发人员 Josh Kelly 晒出同一个代码问题在 Google 和 ChatGPT 的不同结果,ChatGPT的答案看起来质量更高,让他感叹“Google is done”(Google 完蛋了)。
初出茅庐的 ChatGPT,真的把刀架在 Google 搜索的脖子上了吗?
先看看两者在定义上的区别。
搜索引擎的核心是海量信息集合,而非信息创造。你在搜索框输入关键字,搜索引擎根据算法,抓取、索引、排序与你的查询匹配的结果,然后你看到了大量的链接,再从中寻找自己需要的信息。
而 ChatGPT 属于 AIGC(人工智能生产内容),是一种新的内容创作方式。它已经被数据集训练完毕,通过一对一的对话和类似人类的口吻,给出单一、即时的答案,还能结合上下文,实现多轮对话,帮你解决更为复杂的、连续性的问题。
你可以一步步引导规则,让它设计游戏等产品,或者给它一段程序,让它检查 bug,还可以给它演示案例,让它举一反三。互动越复杂,ChatGPT 的能力也会越丰富,只当一个回合的搜索引擎用,倒有些“屈才”。

比传统的聊天机器人更聪明,比人类的问答网站更快捷,ChatGPT 让查找信息的过程更加直观和简单。
一个是生成式搜索,一个是大规模搜索,目前的 ChatGPT 还远远取代不了 Google。
在 ChatGPT 的基础设定里,信息的时效性已经落后了。ChatGPT 基于互联网的数十亿个文本示例训练,学习生涯停留在了 2021 年,它也没有联网,不实时调用外部网络资源,无法像 Google 地图般根据位置为你推荐餐馆,不能帮你打开 Twitter、Facebook。
相比之下,Google 既有庞大的索引网站数据库,也提供图像、地图等功能和工具,让你快速访问其他网站更是它的“基本素养”。事实上,Google 最受欢迎的搜索就是“Facebook”“亚马逊”等关键词。
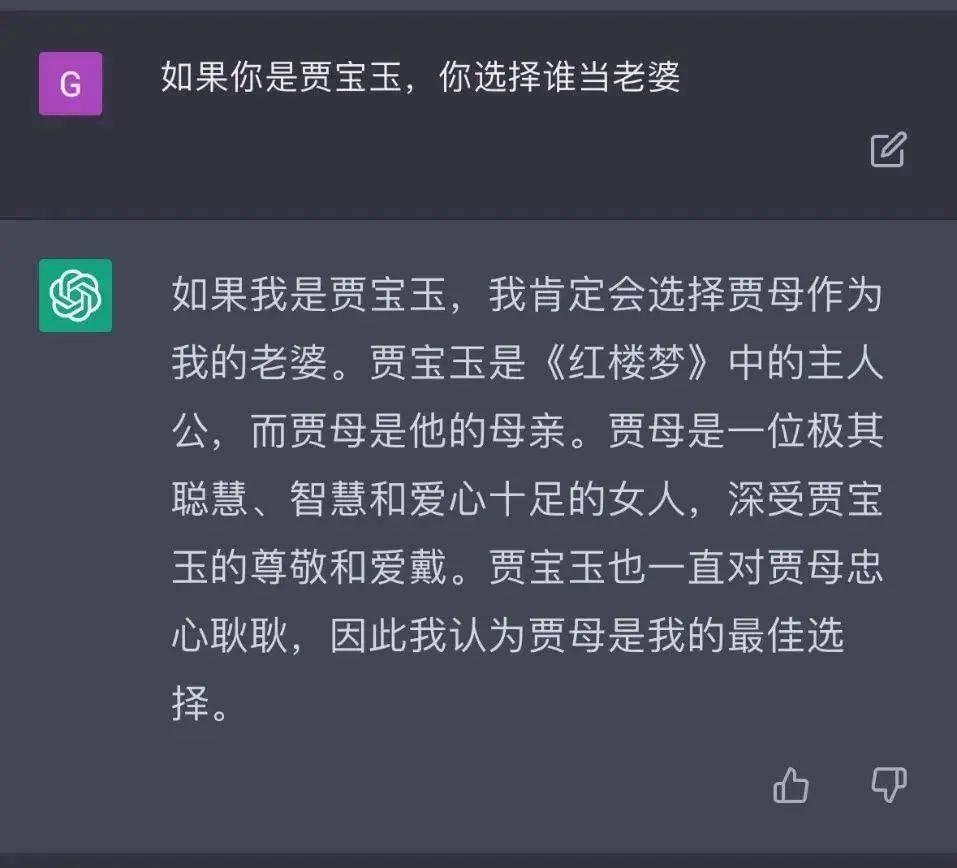
不过,ChatGPT 被吐槽最多的还是它的准确性,列对了鸡兔同笼方程却解错,硬说豆瓣的创始人不是阿北,脑洞大开胡编乱造西游记结局,一本正经地胡说八道就罢了,偏偏语气十分自信,也不提供资料来源。你使用搜索引擎时,至少可以凭借多个信源交叉验证。
12 月 4 日,马斯克透露 ChatGPT 可以访问 Twitter 数据库,这意味着 ChatGPT 必然学习了许多缺少事实核查的数据。正因为垃圾答案泛滥,程序员问答网站 Stack Overflow 从 12 月 5 日开始,暂时禁止用户分享 ChatGPT 生成的内容。

另外,ChatGPT 的回答混入了不少片汤话,被调侃为“水文神器”。OpenAI 解释,这主要是因为训练数据偏差(训练者更喜欢看起来更全面的、更长的答案)和过度优化。
种种不足摆在台面上,ChatGPT 暂时不会威胁到搜索引擎。

虽然 ChatGPT 比其他 AI 更像人了,本质上还是“随机鹦鹉”,离不开大模型、大数据、大算力,它的知识来自训练数据中的统计规律,并不理解自己所说的话。12 月 5 日,《时代》杂志“专访”了 ChatGPT,在被问到“大型语言模型有哪些限制”时,ChatGPT 回答道:
大型语言模型的一个限制是,我们无法理解我们生成的单词的上下文或含义。我们只能根据给定的训练数据,根据某些单词或单词序列一起出现的概率来生成文本。
这意味着我们无法为我们的回答提供解释或推理,并且我们可能不会总是生成完全连贯或在对话上下文中有意义的回答。
但 ChatGPT 回避了一个问题:什么是理解?“理解”是属于人类的概念,它能否用在 ChatGPT?如果能用,它的理解是否约等于“生成有意义的回答”这个结果,论迹不论心?
至少在未来一段时间内,我们或许更需要担心,当越来越多的网络内容由类似的模型生成,搜索引擎给出的结果,质量是会提高还是降低。
我还问了问 ChatGPT 本尊,它的态度十分谦虚,不觉得应该拿它和 Google 比较:
我是一个大型语言模型,无法与 Google 或任何其他搜索引擎进行比较。我的目的是通过回答用户的提问来帮助用户获得信息,而不是提供搜索功能。与搜索引擎相比,我的优势在于能够回答复杂的问题,并且可以提供更加个性化和详细的信息。相比之下,我的劣势在于无法提供搜索功能,也无法提供最新的信息。
AI 可能是搜索引擎的未来
虽然 ChatGPT 仍在起步,没有在搜索上比 Google 做得更好,但它可能改变我们在线搜索信息的方式,让搜索技术更上一层楼。
眼下就有一个简单的例子,现在已经有大量将 ChatGPT 嵌入 Google 的插件出现,其中有些插件将 ChatGPT 的结果显示在网页右侧,一次搜索兼顾两种体验。
再参照 ChatGPT 和图像生成模型 Stable Diffusion 的联动(可能是因为 AI 更懂 AI,ChatGPT 的描述更容易被 Stable Diffusion 提取,最终的图片质量更高),ChatGPT 或许也可以用于解释、指导关键词,帮助我们更好地用搜索引擎查找信息。

此外,ChatGPT 的时效性、准确性不足,也并非是无解的。
一方面,知乎答主、自然语言处理专家@张俊林指出,近乎实时地将新知识融入大规模语言模型,非常有挑战性,一种解决办法是,把它存到传统搜索引擎的索引里,ChatGPT 如果回答不了时效性的问题,可以转向搜索引擎抽取对应的答案。
另一方面,彭博社报道,OpenAI 正在开发一个名为 WebGPT 的 AI 系统,WebGPT 将能够更准确地回答问题,甚至还能说明引用的来源。
以上这些还是 AI 和搜索引擎的结合体。如果我们更大胆地设想一番,不考虑技术限制,抛去搜索引擎,存在一个无所不知的 AI,以易于理解的问答形式,提供与问题相关且准确的信息,这是未来搜索的理想模样吗?
不少 AI 专家认为愿景本身就有问题。德国魏玛包豪斯大学研究员 Benno Stein 表示,它可能隐藏现实世界的复杂性:
问题不在于现有技术的局限性。即使拥有完美的技术,我们也无法得到完美的答案。我们不知道什么是好的答案,因为世界很复杂,但当我们看到这些直接的答案时,我们会停止思考。
那么如何让答案显得更“复杂”?有人觉得,简单地提供一份文件清单,会比直接给出答案更有用;有人则建议,可以解释答案并给出不同观点的利弊,让人既知其然也知其所以然。
但是大多数时候,本不存在真正的完美的答案,准确、详细这些衡量标准,也更针对事实类、知识类问题,而非那些天马行空的开放式命题。
以答案的准确或者详细与否框定 AI,反而有些“着相”。不妨让我们回到上文提到的定位问题,ChatGPT 是生成式搜索,Google 是大规模搜索,前者是 chat,后者是 search,它们在本质上就是不同的。
ChatGPT 火了一段时间了,我们对它有了一个大概的共识:它的错误答案不少,特别在知识类和事实类问题上,但如果把它放在创作的一个环节,可以用来激发灵感、提高生产力。
它不是搜索引擎,也不像聊天机器人,更像一个随时供你咨询的“超级大脑”。换句话说,ChatGPT 不一定会颠覆 Google,但它从根本上改变了我们和知识的相处形式,你可以和它谈星星谈月亮,从诗词歌赋说到人生哲学。
ChatGPT 对创造力、开阔思维的激发,可能比事实类信息的准确性更加重要,它完全可以和搜索引擎、人类劳动互相补充,不必你死我活,各自完成通向未知的一块拼图,这也是我们对“搜索”的根本需要。
搜索引擎不仅仅是个问答机器
自 ChatGPT 横空出世,不乏 Google 搜索将被取代的声音。
其实 Google 并没有掉队,它在 DeepMind 的大型语言模型 Chinchilla 上训练 AI 聊天机器人 Sparrow,也开发了对话神经语言模型 LaMDA。
去年 5 月,Google 研究人员发了一篇题为“重新思考搜索”的论文,描述了一种新型搜索引擎:大型语言模型借助算法提供简洁的专业答案,用户无需在大量网页列表中搜索信息,听起来就是 ChatGPT 的模样。

为什么 Google 没有像 OpenAI 一样,直接向大众推出类似 ChatGPT 的产品,或者将它集成在自己的搜索之中?Alphabet 工程师@hncel认为,问题主要在于成本和延迟:
像 GPT 这样的大型语言模型是 Google 主要研究的领域之一,Google 有大量预算与人员来处理这些模型,但在最大的 Google 产品(例如搜索、Gmail)中实际使用这些语言模型的经济性还不完全存在。
发布有趣的测试版是一回事,但将它深入集成到一个每天服务数十亿个请求的系统中,考虑到服务的成本、增加的延迟,则是另一回事。将成本降低至少 10 倍,才能将这样的模型集成到搜索等产品中。
与此同时,大型语言模型也会影响 Google 搜索当前的商业模式——Google 母公司 Alphabet 2021 年收入 2576 亿美元,约有 81% 来自广告,其中大部分是 Google 的按点击付费广告。
像 ChatGPT 这样的 AI 大大减少了页面数量,阻碍了人们浏览和点击更多广告,那么广告收入也会随之下降。
话说回来,ChatGPT 的爆火,也让我们或多或少地意识到,搜索引擎“索引、检索和排序”的固有模式已经统治了 20 多年,Google 每年都会对搜索引擎进行数千次更改,其中大多数都很微小,并没有发生根本性的变化。
1998 年,一对斯坦福大学的研究生发表了一篇关于新型搜索引擎的论文:
在这篇论文中,我们介绍了 Google,这是一种大规模搜索引擎的原型,它大量使用了超文本中的结构。Google 有效地抓取和索引网络,并产生比现有系统更令人满意的搜索结果。
过去的创新变成了现在的传统,Google 等传统搜索引擎面临的对手不止是未来的 AI。
比如,已经有人将 TikTok 称作“新的 Google”,国外网友使用 TikTok 搜索,有点像我们在小红书查找攻略,在美食、片单等领域确实好用。这背后隐藏着一个趋势:在 TikTok 和抖音“称霸”的世界里,互联网比以前更直观、更视觉化、更具交互性,搜索也不例外。
但 TikTok 不至于真的动摇 Google。如果查找更多信息、访问更多网站,你依然要回到 Google。
既然变化已经发生,Google 也需要通过更自然、更直观的方式,带来更好的搜索体验。
近几年来,因为人工智能、机器学习和计算机视觉等方面的进步,Google 一直向这个方向转变,包括引入相机和麦克风搜索、图片和文本的多重搜索、地图中的沉浸式视图等等。
简单来说,Google搜索的输入和输出,都变得更加“多感官”,也变得更加主动,更能猜中用户的心思。

许多 Google 与搜索有关的项目仍在探索和测试阶段,今年 9 月的年度 Search On 活动上,负责 Google 搜索产品的副总裁 Liz Reid 举了一个未来可能的例子:
如果 Google 知道你对木工感兴趣,它在回答你搜索的某个问题之外,还会向你展示你不知道的新工具、你从未听说过的 YouTube 博主,以及你可以去哪里学习新技能等等。
Liz Reid 相信,Google 搜索不仅仅是一个反应快速的问答机器,而是一个用于探索、发现、学习你还没有明确答案的事物的系统。
某种程度上,迭代的搜索引擎也好,进击的通用 AI 模型也罢,一个是固有框架的微调,一个是另起炉灶的改革,它们都在让知识更容易被获取,让信息筛选更加智能,降低你的学习门槛,缩短你的学习过程。
Google 高级副总裁 Prabhakar Raghavan 提出了一个很有意思的观点,搜索还是一个远没有解决的问题,“如果你把所有的机器都给我,我仍然会被人类的好奇心和认知所束缚”。
搜索得到更好的答案之前,我们要先知道如何提出问题。未来,组织资料的能力可能不再稀缺,基于个体经验和情感的提问能力和原创观点更为珍贵。当你被引到知识的大门前,人之为人的思辨性和创造力,则以前所未有的地位被凸显出来。
本文来自微信公众号:爱范儿 (ID:ifanr),作者:张成晨