
本文来自微信公众号:品玩 (ID:pinwancool),作者:洪雨晗,题图来源:视觉中国
在计算机发展的历史上,计算机性能的提升主要依托于其搭载的处理器的进步:如从奔腾(Pentium)到酷睿(Core),从推土机(AMD FX)到Zen。
而芯片性能的提升则依靠芯片技术的进步:如芯片产业采用的主流方式是提升芯片的先进制程来提升其性能,使芯片制程从14nm到5nm不断缩小,同样大小的芯片中装入更多晶体管来提升其运算能力。
苹果、英伟达也始终是先进制程的追逐者。
两家厂商的算力产品都是委托晶圆代工厂台积电代工,并争取其先进制程的产能、紧跟芯片业界最新工艺,可以说两家最新发布的产品汇聚了芯片产业界目前的工艺水平和技术能力。
从近期苹果及英伟达发布会上透露的产品信息可以发现一项惊人的事实——地表最强性能的处理器芯片都采用了“拼装”工艺。
颠覆行业的“拼装”芯片
第一个重磅炸弹是苹果砸下来的。
在市场预期已习惯于同一芯片制程,处理器性能提升在10%到20%之间时,同样采用台积电代工的5nm芯片制程的苹果自研电脑芯片M1 Ultra,硬件性能指标却远远超出仅在半年前发布的M1 Max。
彼时,市场还震惊于M1 Max的芯片面积有432平方毫米,是将近4个M1芯片大小,M1 Ultra则在此基础上让芯片的体积再度翻倍。
芯片体积的增大意味着其拥有了更多的晶体管,M1 Ultra 共有1140亿晶体管,而半年前发布的M1 Max的晶体管数量为570亿,随之而来的是CPU核心、GPU核心、神经网络引擎数量的翻倍。
M1 Ultra支持20个CPU核心、64个GPU核心和32核神经网络引擎,其支持的带宽达到128GB,每秒运算高达22万亿次。
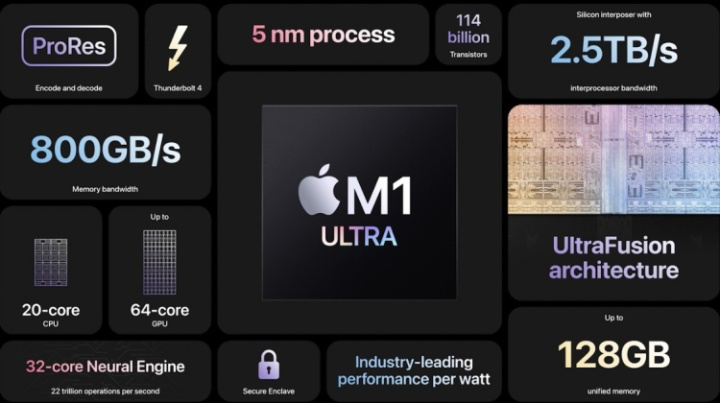
仔细看不难发现,M1 Ultra的各项核心数据基本是上一代产品M1 Max的翻倍,M1 Ultra似乎是将两块M1 Max“粘合”在一起。事实也确实如此,M1 Ultra是通过一种名为UltraFusion的封装技术,将两块M1 Max合二为一,通过这种封装技术,苹果实现了两块芯片之间2.5TB/s的数据传输速度。
苹果硬件技术高级副总裁 Johny Srouji 表示:
“通过将两个M1 Max与我们的UltraFusion封装架构连接起来,我们能够将苹果芯片材料扩展到前所未有的新高度。”
“凭借其强大的CPU、庞大的GPU、令人难以置信的神经引擎、ProRes硬件加速和大量的统一内存,M1 Ultra使M1家族成为世界上功能最强大的个人电脑芯片。”

紧接着,英伟达在两周后扔下另一枚“核弹”。
在3月22日英伟达年度GTC大会上,黄仁勋发布了其称作“AI工厂的理想CPU”的数据中心专属CPU——Grace CPU Superchip。
Grace CPU Superchip基于Armv9架构,拥有144个Arm CPU核心,其内存带宽达到了1TB/s,据SPECrate®2017_int_base基准测试数据,Grace CPU Superchip的模拟性能得分达到740,是DGX A100的1.5倍(460分)。
让人惊异的是,这款超级芯片同样由两块芯片“粘合”在一起。
Grace CPU Superchip由两块Grace CPU组成,通过芯片互连技术NVIDIA NVLink-C2C将两块Grace CPU连在一起,其实早在去年英伟达发布的Grace Hopper Superchip就采用了这一技术来连接芯片。

不难发现,从苹果M1 Ultra到英伟达Grace CPU Superchip,都是将两块相同的小芯片“拼装”在一起达到性能的机制提升,这是否意味着未来话大代价缓慢开发2nm、1nm的先进制程得不偿失,只需要不断推芯片就能达到性能的翻倍?那在更早之前这种芯片“拼装”技术为何没能成为业界的主流呢?
这其实涉及到近年来半导体业界热度极高的封装技术chiplet。
独领“封”骚的Chiplet
不管是苹果M1 Ultra使用的UltraFusion封装架构,还是英伟达采用的芯片互连技术NVIDIA NVLink-C2C,都有涉及相关chiplet之间的互联互通。
NVIDIA超大规模计算副总裁Ian Buck曾表示:“为应对摩尔定律发展趋缓的局面,必须开发小芯片和异构计算。”
Ian Buck口中的小芯片正是chiplet,也常被译为芯粒。它是系统级芯片(SoC)中IP模块的芯片化,通过chiplet技术可以提高良率和降低成本,同时提高设计的灵活度,缩短设计周期。
目前的系统级芯片(SoC)并不只是一块CPU或一块GPU,而是CPU、GPU、ISP、NPU等多种计算单元都在一块芯片上。
简单来说,可以把chiplet技术想象成为一块乐高积木,chiplet则是将这些不同的计算单元模块化,多个chiplet模块可以拼接成一个系统级芯片(SoC),而在过去,一个系统级芯片(SoC)是不能再次切割的。这样做的好处在于,一块完整的晶圆可以被分成更多的chiplet,这意味着同样良率情况下更低的成本消耗。
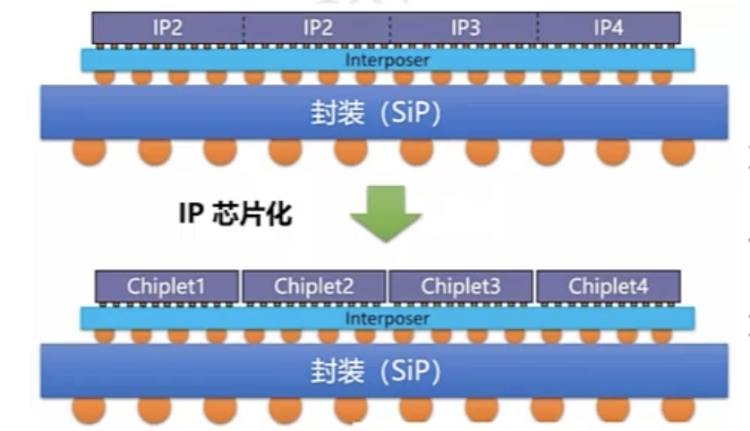
例如在一片晶圆切割封装时出现了一个点的损伤部位,直接做成一个系统级芯片(SoC)能切成10块,假如做成chiplet是100块,那么这块晶圆做成系统级芯片(SoC)的良品率为90%,而做成chiplet的良品率可以达到99%。
chiplet除了大幅提高大型芯片的良率、降低设计成本等经济上的效益, chiplet技术也为异质异构的芯片制造提供了可能,这种模块化的小芯片可以实现不同架构、不同材质、不同工艺节点甚至不同晶圆代工厂生产的产品集成到一块芯片上,由此快速产生出一个适应不同功能需求的超级芯片。
例如,AMD的数几代产品都采用了“SiP + chiplet”的异构系统集成模式,同时,今年3月的GTC上,英伟达除了发布Grace CPU Superchip,还推出了Grace Hopper Superchip,它不是由两块相同的Grace CPU组成,而是由一个Grace CPU和一个Hopper架构的GPU组成,这些都是chiplet为超级芯片的设计、生产所提供的工艺上的可能。

更有人认为以chiplet为代表的先进封装技术正在成为超越摩尔的关键,戈登·摩尔根据自己的经验在半导体领域做的一个预言:“在最小成本的前提下,集成电路所含有的元件数量大约每年便能增加一倍。(The complexity for minimum component costs has increased at a rate of roughly a factor of two per year)
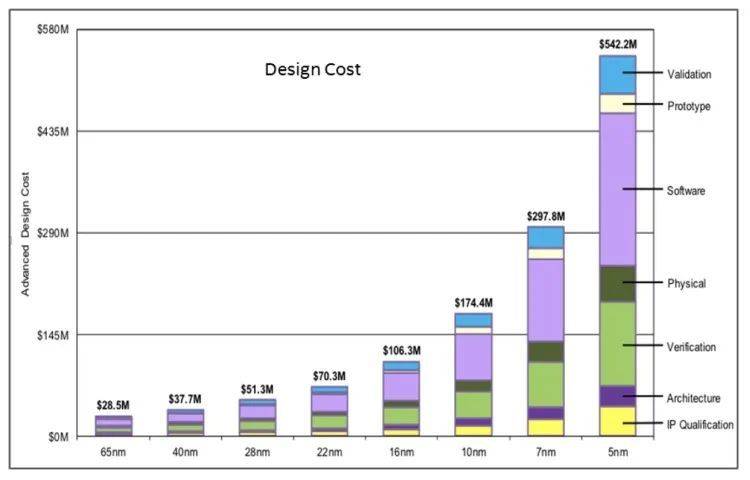
如今据摩尔定律的提出已过去了57年,要想在拇指大小的芯片上做出更多的晶体管与更小的制程,变得越来越困难。
从技术上来说就是随着芯片尺寸的微缩,短道沟效应导致的漏电、发热和功耗严重问题一直困扰着芯片制程的继续微缩。当材料逼近1nm的物理极限时,量子隧穿效应导致有一定的电子可以跨过势垒,从而漏电,这个问题对于人类来说暂时是无解的。
虽然摩尔定律到现在仍在艰难维持,但产业界也确实意识到了制程不会无限缩小下去,晶体管也不可能无限增加下去,可以说产业界将先进封装技术提升到与制程微缩同等重要的程度,从晶圆代工厂到封测厂商都在加大对先进封装技术的投入,从去年开始,先进封装技术已成为了各大晶圆厂、封测厂商甚至一些Fabless的重点投入领域。
早在2021年1月,台积电总裁魏哲家在财报会议上透露:“对于包括SoIC、CoWoS(苹果M1 Ultra所采用的工艺)等先进封装技术,我们观察到chiplet正成为一种行业趋势。台积电正与几位客户一起,使用chiplet架构进行3D封装研发。”
到了去年6月,封测龙头日月光宣布将投入20亿美元用于提高其晶圆封装业务;7月,英特尔公布了未来制程工艺和封装技术路线图,将继续推动Foveros 3D堆叠封装技术与EMIB(嵌入式多管芯互连桥)封装技术的应用;9月,联电与封测厂商颀邦相互交换股权。
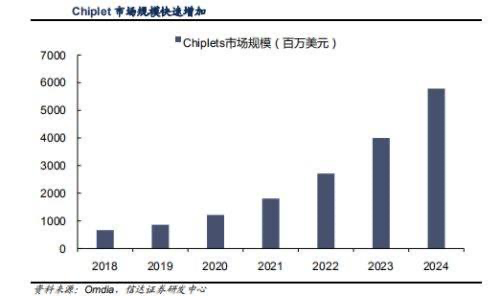
在各大半导体厂商的追加投资的热潮下,chiplet市场也迎来迅猛发展。据Omdia预计,2024年chiplet的市场规模将达到58亿美元,到2035年则超过570亿美元,市场规模将迎来快速增长。
当然,chiplet的实现需要诸多技术接口上的整合,就如上文所说, chiplet可以实现不同架构、不同材质、不同工艺节点甚至不同晶圆代工厂生产的产品集成到一块芯片上,但不同的芯片厂商其采用的连接协议是不同的,如英伟达Grace CPU Superchip采用的是NVLink-C2C技术、苹果M1 Ultra采用的台积电提供的连接协议,英特尔也有自己的授权协议AIB。
毫无疑问,各芯片巨头们正在通过自家的chiplet协议来打造产品生态、抢占市场,但chiplet技术的出现本来就意在打破不同生态间的壁垒,如果又因其背后的连接协议而造成产业链的割裂,可以说是得不偿失,于是,就在今年3月初,半导体产业第一个chiplet互联接口标准化的“桥梁”——UCIe联盟成了。
UCIe是机遇还是洪水猛兽?
今年3月2日,英特尔、AMD、ARM、高通、三星、台积电、日月光等半导体产业链厂商,以及Google Cloud、Meta、微软等互联网硬件终端企业宣布了一项新技术标准UCIe(Universal Chiplet Interconnect Express)。
简单来说,UCIe是一个开放的行业互连标准,它定义了各小芯片之间的互联标准,这意味着半导体产业界正在打造一个标准化、通用化、即插即用的chiplet接口,这个开放标准的推广无疑将为整个产业带来巨头的创新空间,它不仅具有高带宽、低延迟、经济节能的优点,还能够应用于包括计算机、云边端、5G、汽车和移动设备在内的所有领域。
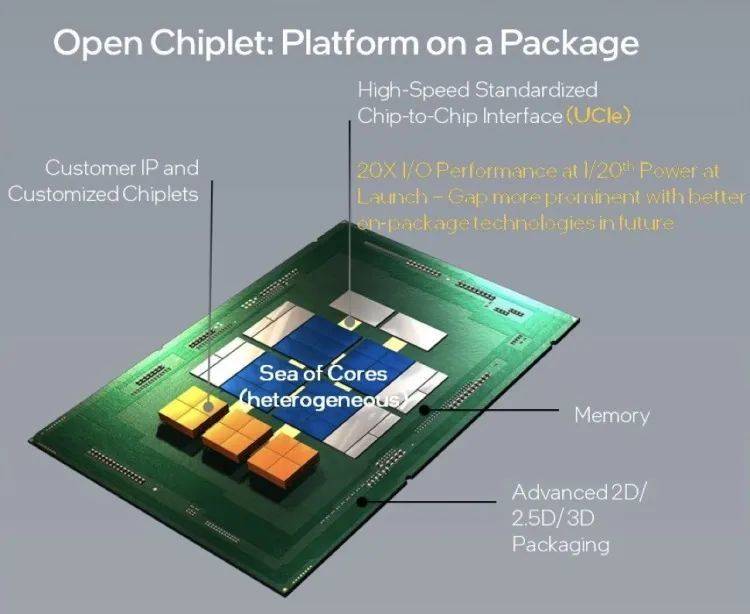
然而,UCIe所制定的行业互连标准虽好,但眼尖的人不难发现创立该联盟的十大公司中没有一家是来自中国的企业,尤其是在半导体这样一个极为敏感的行业,这是不是意味着UCIe产业联盟要自己搞一个协议在chiplet工艺中自立游戏规则,那么新玩家想要加入需要付出什么代价?是要像对待Arm一样交授权费,或是又可以被拿来当做“卡脖子”的工具?
对国内的芯片企业而言,以chiplet技术为代表的先进封装正是现下适合长期投入的优质赛道,毕竟短期内国内企业还无法通过自研或是进口来获取EUV光刻机。
虽然,现在我们处于光刻来驱动尺寸微缩的时代,但未来驱动芯片行业继续往前走的可能是设计与工艺协同优化,以及系统与工艺协同优化的阶段,那么,先进封装或是下一次芯片产业洗牌的开端,chiplet成为我国芯片产业弯道超车的一个绝佳技术机会,但如今,UCIe产业联盟先人一步成立,它未来是否会成为堵在前方的又一座大山?

好消息是,我国的chiplet行业互连标准制也在紧锣密鼓的准备中。
今年3月28日起,中国计算机互连技术联盟(CCITA)联合电子标准院、中科院计算所、工信部以及国内多个芯片厂商已完成《小芯片接口总线技术》、《微电子芯片光互连接口技术》的标准草案制定,国内涉及小芯片技术的相关企业都可通过CCITA与联盟反馈草案意见。
需要注意的是,中国计算机互连技术联盟的《小芯片接口总线技术》与UCIe联盟制定的相关标准有着不小的差异,如台积电引以为傲的CoWoS(苹果M1 Ultra所采用的工艺)技术,大陆的封测厂目前无法达到。
简单说,《小芯片接口总线技术》适合中国芯片产业链当前的状况,偏向成熟制程,UCIe联盟的相关标准在某种程度上来说更看重chiplet在先进制程上的表现。
这当然不是意味着《小芯片接口总线技术》就不如UCIe,在中芯国际、华虹半导体等大陆数一数二的晶圆厂无法制造先进制程芯片时,探索更适合当下产业链状况的小芯片互联技术才显得脚踏实地。中国计算机互连技术联盟秘书长、中科院计算所研究员郝沁汾认为国内的chiplet标准可以用更加成熟和低成本的方式做出,由此可替代先进制程的昂贵方案。
就在不少人认为未来中国芯片企业加入UCIe联盟无望,中国半导体产业得再接一记硬招的时候,成立UCIe联盟的发起者英特尔,在4月2日竟然把一家大陆芯片公司芯原微电子拉入了UCIe联盟。
芯原微电子究竟是何方神圣?据该公司官网资料,芯原是国内的一家半导体IP供应商,拥有图形处理器IP、神经网络处理器IP、视频处理器IP、数字信号处理器IP、图像信号处理器IP和显示处理器IP六大类处理器IP核。
根据研究机构IPnest统计,芯原是中国大陆排名第一、全球排名第七的半导体IP供应商,目前芯原推出了基于Chiplet架构所设计的处理器平台,该平台12nm SoC版本已完成流片和验证,并正在进行chiplet版本的迭代。
中国半导体IP的核心企业加入UCle联盟意味着什么现在还很难说清,是好是坏还有待时间验证,但谁也不敢就此保证UCIe对中国芯片企业将彻底开放,毕竟有着前车之鉴。这不是简单的选Lightning接口还是Type-C接口的问题,其背后所代表的技术路线、支撑其的产业链乃至背后的经济博弈每一项都不可小觑。
唯一能确定的是,国内现已完成草案的《小芯片接口总线技术》《微电子芯片光互连接口技术》不能停下脚步,尽快汇集更多企业,做到国内chiplet技术标注的落地和不断迭代是一个艰难却必定要做下去的事情。
本文来自微信公众号:品玩 (ID:pinwancool),作者:洪雨晗