
本文来自微信公众号:GenAI新世界(ID:gh_e06235300f0d),作者:薛良Neil,头图来自:OpenAI
多模态与大模型该如何更好结合是人工智能目前一个非常热门的研究方向,OpenAI刚刚发布的文生图模型DALL·E 3向所有人展示了一个最会做大模型的公司是如何看待和试图解决这个问题的。

DALL·E 3的升级点可以分为两部分,首先它是一个更好、更精确的文生图模型。
更好是相比DALL·E 2而言,更精确则意味着DALL·E 3对提示词有着更好的理解能力。
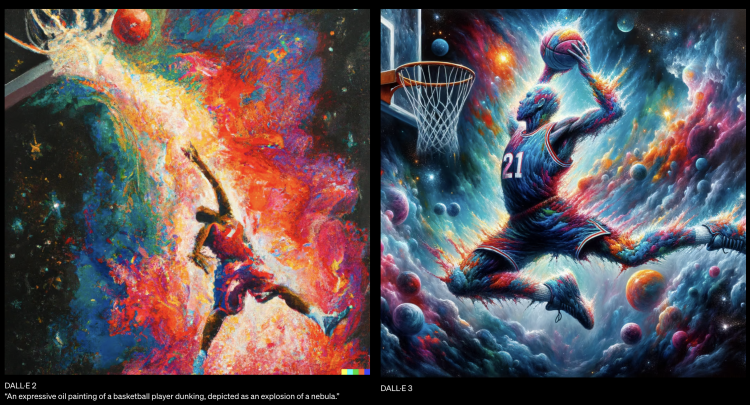
相同提示词下,DALL·E 2(左)和DALL·E 3生成效果对比。
换而言之,你不需要再绞尽脑汁成为一个提示词prompt大师了。OpenAI在介绍DALL·E 3的页面宣称,目前的文生图应用总是倾向于忽略用户给出的描述词,这强迫大家每个人都要去学着搞prompt,DALL·E 3克服了这一点。
比如下面这个例子。prompt中涵盖的各种要素,无论主次与否,比如行人、满月、斗篷乃至蒸汽朋克风格的电话,都被DALL·E 3精准还原了出来。

官方还给出了更多的案例,体现DALL·E 3出色的理解能力,简单放几张如下。

土豆国王俯瞰着它的王国。

灵感来自荔枝的球形椅子。

卷发像暴风一样飘扬,服装像大理石和瓷器碎片组成的旋风一样的舞者。

心脏里的微小宇宙。注意基座上镌刻的英文,这反映出DALL·E 3已经拥有了生成文字的能力。
这些天马行空的形容都被DALL·E 3很好地捕捉,但仅仅描述词理解能力的提升还不是DALL·E 3的升级重点,真正的杀手锏是OpenAI直接把DALL·E 3集成到了ChatGPT中!这种集成不是简单地在对话框或者提示词中放上工具的入口,而是用ChatGPT的语言能力帮助DALL·E 3理解和生成更准确的图片。
换而言之,DALL·E 3被大模型赋能,在这个基础上,图片和文字的模态实现自由转换。
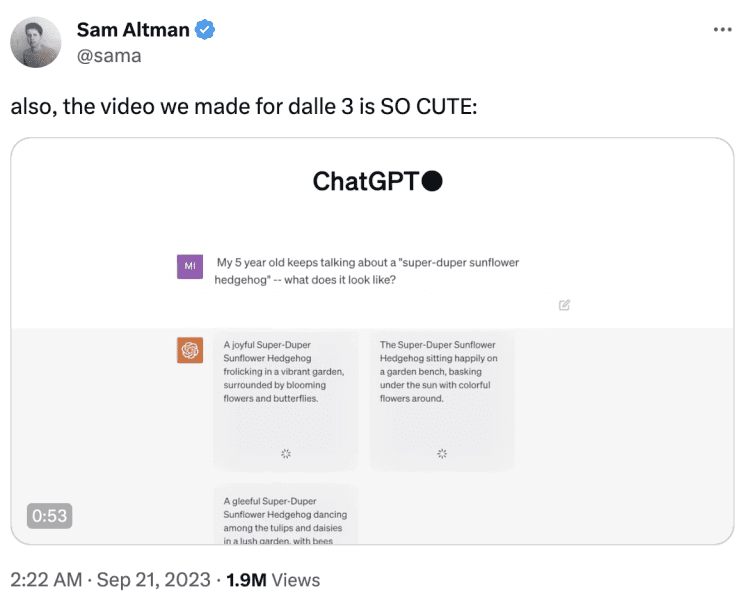
OpenAI用一个非常生动的例子诠释了这种自由转换。用户首先让DALL·E 3生成一个“超级向日葵刺猬”(好吧,我知道没有人知道那究竟是什么)。
在ChatGPT的优化帮助下,DALL·E 3精准领会了用户的意思。生成的图片不仅画风多样,而且内容准确。要注意这是在只有很少的提示词的情况下做到的。

由于和ChatGPT集成在了一起,DALL·E 3拥有思维链能力。你可以给这只刺猬起个名字,然后ChatGPT会记住这一点,在接下来的交互中,DALL·E 3始终知道Larry是谁。
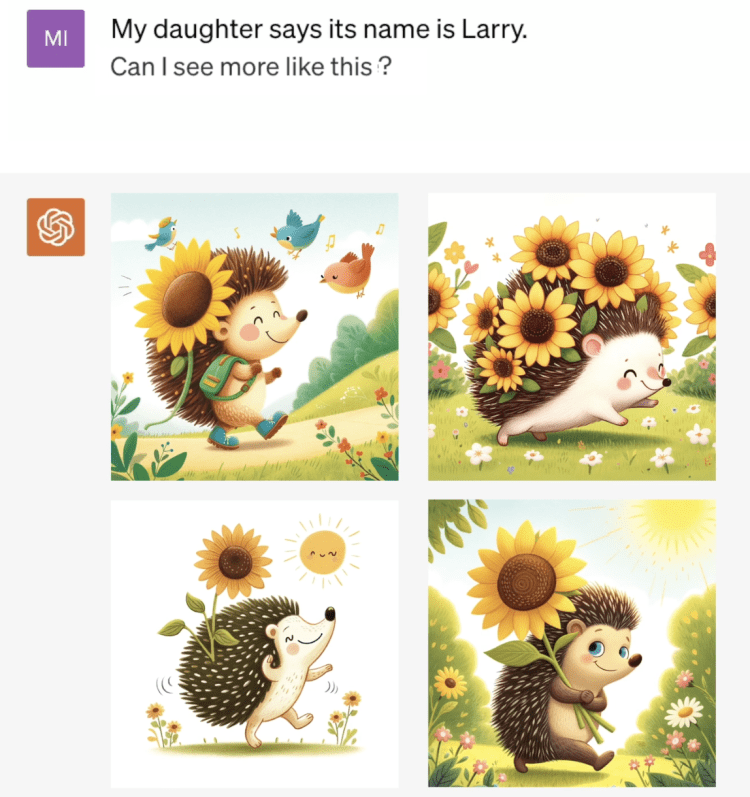
你可以继续像同人类对话一样,用自然语言来同DALL·E 3进行交互。比如你可以说,“能让我看看Larry的房子吗?”或者“为什么它这么棒(super-duper)?”,ChatGPT会通过文字和图片来给你答案。
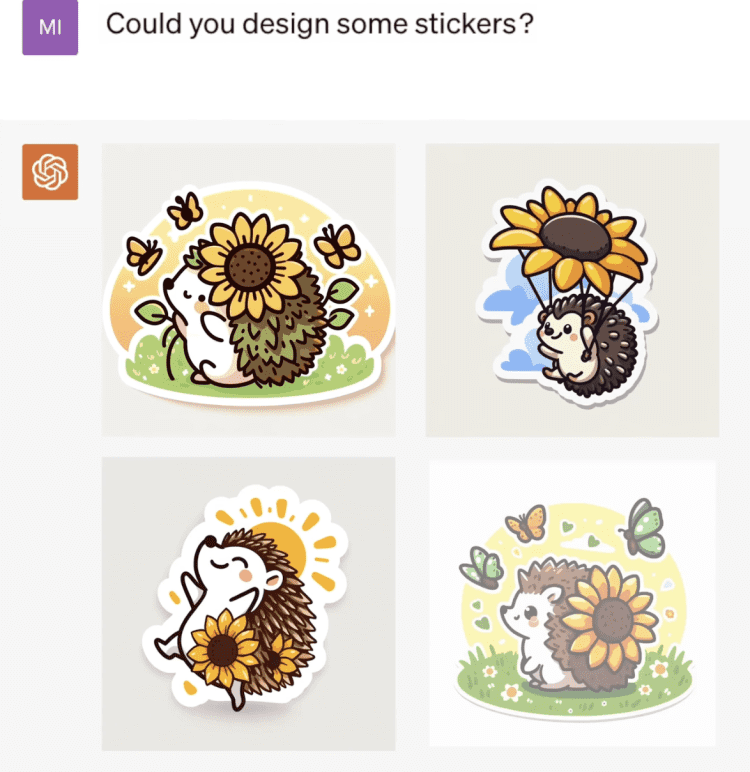
正在生成和Larry有关的贴纸。
最终,这些内容可以被总结汇编成一个图文并茂的睡前故事。
连OpenAI的CEO都忍不住夸,这个宣传视频真的还怪可爱的。
迈出多模态自由转换的第一步
DALL·E 3和ChatGPT的结合能力让人震惊,有网友已经直接给 MidJourney点蜡烛了。

相比基于Discord的MidJourney,自然语言显然是更好的交互方式,OpenAI用ChatGPT辅助用户使用DALL·E 3的过程不仅包括了对用户意图的解读,还将具有一定智能的大模型将思维链引入其中,图片生成始终沿着用户的prompt指示进行,在多轮对话中体现出了很好的一致连贯性。
但DALL·E 3绝不仅是交互方式的革新,它背后反映的OpenAI在跨模态应用上的潜力更值得注意。
OpenAI以大模型能力闻名,但它也是最早尝试用文本作为条件引导图像生成的公司,在DALL·E 2的前身GLIDE中,OpenAI训练了一个35亿参数文本条件扩散模型,文本条件信息的嵌入正是来自transformer模型。
可以说,GLIDE的成功第一次让扩散模型“真正出圈”,因此,尽管目前我们很难知道DALL·E 3的技术细节,但有鉴于它在demo中展现出来的实力,有理由相信OpenAI在大模型中积累的经验同样也被应用在了DALL·E 3的开发中。
OpenAI的独特优势让大模型在交互方式和开发过程都与DALL·E 3实现了紧密结合,这恐怕是其它公司所不具备的企业护城河,借助大语言模型的智能来推动多模态之间的转换,我们已经在DALL·E 3看到了一个多模态大模型的雏形。
本文来自微信公众号:GenAI新世界(ID:gh_e06235300f0d),作者:薛良Neil