
本文来自微信公众号:新智元 (ID:AI_era),作者:拉燕、David,原文标题:《Science封面6连发:人类最完整的基因组测序完成!》,头图来自:斯托瓦斯医学研究所
全世界科学家近40年的努力,今天终于圆满了!
Science连发6篇封面文章,宣布人类完整基因组测序计划正式完成。
据路透社、Science等报道,这项成果填补了前人几十年努力后仍然存在的空白,为全球 79 亿人寻找有关致病突变和遗传变异的线索提供了新的希望。
算起来,距离人类最早讨论基因组测序计划,到今天已经过去了近40年。
一、19年前差8%“进度条”,现在终于填上了
1984年,由美国政府资助的旨在讨论日益发展的DNA重组技术的会议上,科学家们第一次讨论了人类基因组测序的价值。
1990年,人类基因组计划由美国能源部和NIH投资,预期在15年内完成。
1999年,中国科学院遗传研究所人类基因组中心向NIH国际人类基因组计划(HGP)递交加入申请,承担总测序量1%(约3000万对碱基)的测序任务。
2003年4月,人类基因组计划宣布完成。但这里的“完成”要打个折扣,因为当时这个计划无法对所有人类细胞中发现的DNA进行测序,只能对基因组的“真染色质”区域进行测序,这些区域占人类基因组的92%。
其余的8%,称为“异染色质”区域,由高度重复且结构紧密的 DNA 块组成,当时的测序技术无能为力。
现在,这部分之前难以读取的碱基对,被一个名叫“端粒到端粒联盟”(T2T consortium)的组织解决了。

最新一期 Science 以“填平鸿沟”(Filling the Gaps)为题报道了这一重磅消息,并刊载了关于新的测序技术细节的六篇论文。






这个名字就很有意思,端粒是是真核生物染色体末端的DNA重复序列,正处于典型的异染色体区域,即之前的无法完成测序的部分。
“T2T联盟”在推特上宣布,这些部分的测序工作已经正式完成。

欧洲分子生物学实验室副主任、原人类基因组计划成员、生物信息学家Ewan Birney说:“我认为我们甚至在5年前都无法想象。
以前无法破译的基因组序列现在已经清晰可见,其中包括端粒和中心粒的部分,后者位于每条染色体的中间,起协调复制的作用。
此外,还有五条染色体的短臂上的基因组完成测序。这些短臂已知包含几十个编码核糖体主干的基因,核糖体是细胞的“蛋白质工厂”。
二、全基因组测序变成“完形填空”
2001年,人类基因组的第一份草案提出开始时,甚至在首次宣布“完成”后,基因测序技术都无法涉足DNA序列包含非常重复的碱基段的区域。在测序结果中,这些重复序列一般被跳过留白,或者以错误的方式呈现。
随着测序技术的提高和成本的下降,这些留白和错误的空间越来越小。2017年,科学家们发布了一个名为GRCh38的人类基因组。由于其“留白”缺口不到1000个,在许多人看来,它成为了其他人类基因组的标杆参照。
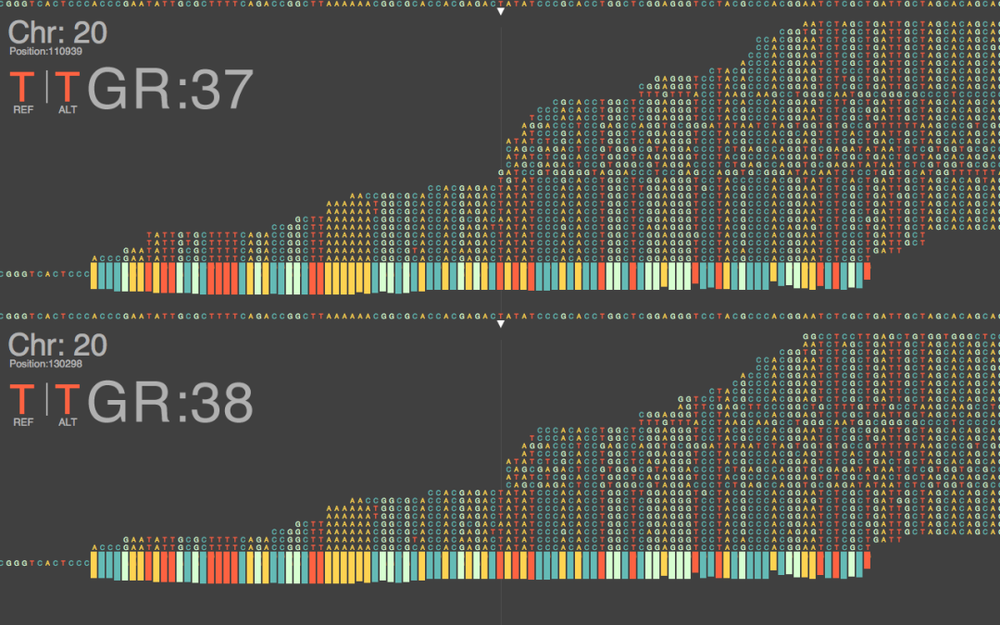
从那时开始,科学家们开始把这个工作做成了“完形填空”。
越来越多的人加入,想把这个完形填空继续做到底。
2019年,美国国家人类基因组研究中心的生物信息学家Adam Phillippy报告说,已经成功地对X染色体进行了从头到尾的测序,这也激发了其他几十个研究人员加入这一事业。
“这项事业真的有了自己的生命,” 加州大学圣克鲁兹分校的遗传学家Karen Miga表示。在一次会议上和Adam Phillippy见面后,他们开始携手合作。
T2T结合了多种测序技术,其中有纳米孔设备,可以同时识别100000对碱基;还有另一种测序设备,结果更精确,但是同时只能识别10000对。研究人员对后一种办法做了一些升级,进一步提高了准确性。
Waterston表示,“看看他们为了解决这些问题用了多少方法,你就知道到底有多难了。”他是华盛顿大学的一名遗传学家,曾经一同领导过人类基因组计划。
最终,大概两亿对碱基排列顺序正确、位置正确。其中包括超过1900组基因,大部分都是已知基因的复制。研究人员将复制的区域和可移动的元素进行记录——比如病毒带来的基因材料被整合到了基因里。
短染色体臂(short chromosome arm)蕴藏着另一个惊喜。就像预料的一样,这些短染色体包含很多复制,总共有400个,复制的是为RNA编码的基因。
Miga表示,“rDNA是最后一块多米诺骨牌。”这部分一直以来都是最难测序的地方。
“这真的很神奇,人类的基因组竟是这么的动态。”人类基因组计划组织者之一George Church教授表示。
三、这次测的是谁的DNA?

如此完整的基因测序工作,自然离不开无私奉献的人贡献出自己的DNA。51岁的哈佛生物学博士Leonoid Peshkin就是这样一个人。
此次测序基因组的Y染色体来自Peshkin,而剩下的DNA则来自所谓的葡萄糖妊娠(molar pregnancy),这是一种较为罕见的子宫生长方式。精子在进入卵细胞时如果没有染色体,就会发生葡萄糖妊娠。
在这种情况下,受精的细胞会复制精子的23条染色体,产生两组一模一样的染色体, 并具备复制能力。匹兹堡大学的遗传学家Urvashi Surti发现了这个特性可以对基因组测序工作大有帮助,因为测序仪不必解决父母染色体之间的差异。她想据此培育一个细胞系出来。
在征得了医疗中心审查委员会的许可后,她删掉了所有有可能会和父母有关联的信息。2001年,她成功了,并获得了1981到2000年间相关研究的数据。
2019年,该研究出现了一些潜在的问题,当时美国国家人类基因组研究所(NHGRI)要求任何基因数据共享都必须征得捐献者百分之百的同意。
虽然Surti和她的团队没有获得相应的许可,但NHGRI最终对这项研究网开一面。他们认为,这次例外应该要开个后门,因为该研究的大部分序列都已经公开了。
然而问题还是没有得到解决。研究中创造的基因组的主人身份究竟能不能靠数据库确认?
NHGRI认为,就算能确认,也不能这么做。这样做是不道德的。男方身份也不能公开,哪怕是去找他要许可也不行。
Surti研究中的基因组只有X染色体,没有Y染色体,最后,Peshkin的DNA被加了进去。此前,Peshkin和他的父母曾经为DNA研究捐献过组织。
几个月前,Peshkin给NIST打了个电话。NIST告诉他,T2T研究团队正全面的对Peshkin的X、Y染色体测序。正是因为他的奉献,研究人员才得以大规模的利用他的DNA。他的基因组将会是有史以来第一个完整的人类基因组。
Peshkin表示,“我非常兴奋能参与到这项前沿的科学研究中来。为科学做点微不足道的贡献嘛,这是我该做的。”
参考资料:
https://www.science.org/content/article/most-complete-human-genome-yet-reveals-previously-indecipherable-dna
https://www.science.org/toc/science/376/6588
https://www.reuters.com/lifestyle/science/scientists-publish-first-complete-human-genome-2022-03-31/
本文来自微信公众号:新智元 (ID:AI_era),作者:拉燕、David