
本文来自微信公众号:新智元 (ID:AI_era),作者:桃子、拉燕,原文标题:《世界首颗3D芯片诞生!集成600亿晶体管,突破7nm制程极限》,头图来自:Graphcore
全球首颗3D封装芯片诞生!
周四,总部位于英国的AI芯片公司Graphcore发布了一款IPU产品Bow,采用的是台积电7纳米的3D封装技术。
据介绍,这款处理器将计算机训练神经网络的速度提升40%,同时能耗比提升了16%。
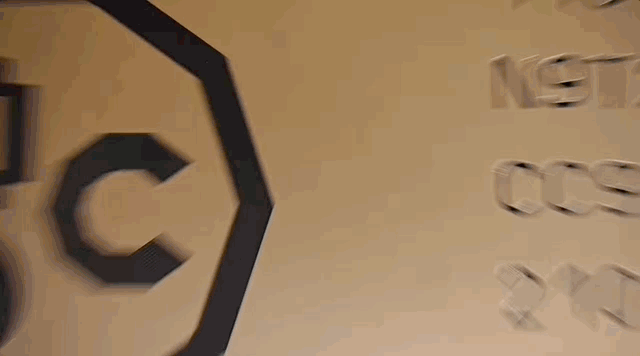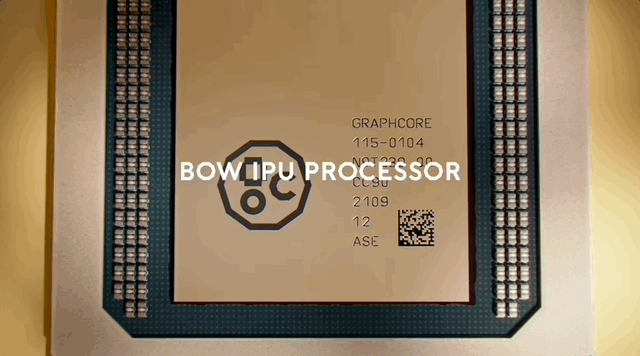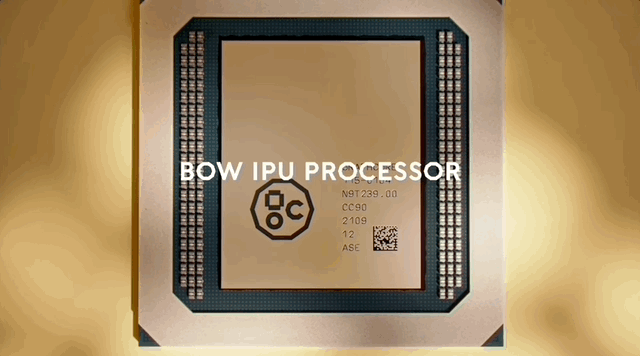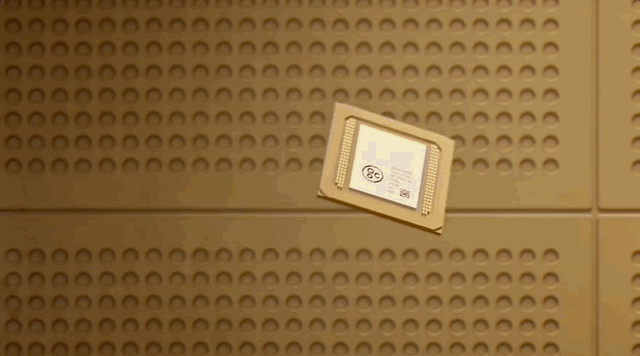
一、600亿晶体管,首颗3D芯片诞生
能够有如此大的提升,也是得益于台积电的3D WoW硅晶圆堆叠技术,从而实现了性能和能耗比的全面提升。
正如刚刚所提到的,与Graphcore的上一代相比,Bow IPU可以训练关键的神经网络,速度约为40%,同时,效率也提升了16%。
同时,在台积电技术加持下,Bow IPU单个封装中的晶体管数量也达到了前所未有的新高度,拥有超过600亿个晶体管。
官方介绍称,Bow IPU的变化是这颗芯片采用3D封装,晶体管的规模有所增加,算力和吞吐量均得到提升,Bow每秒可以执行350万亿flop的混合精度AI运算,是上代的1.4倍,吞吐量从47.5TB提高到了65TB。
Knowles将其称为当今世界上性能最高的AI处理器,确实当之无愧。

Bow IPU的诞生证明了芯片性能的提升并不一定要提升工艺,也可以升级封装技术,向先进封装转移。
Graphcore 首席技术官和联合创始人Simon Knowles表示,“我们正在进入一个先进封装的时代。在这个时代,多个硅芯片将被封装在一起,以弥补在不断放缓的摩尔定律(Moore’s Law)道路上取得的不断进步所带来的性能优势。”

二、台积电WoW封装技术
2018年4月,在美国加州圣克拉拉举行了第二十四届年度技术研讨会。在这次会上,全球最大的半导体代工企业台积电首次对外公布了名叫SoIC(System on Integrated Chips)的芯片3D封装技术。
这是一种整合芯片的封装技术,由台积电和谷歌等公司共同测试开发。而谷歌也将成为台积电3D封装芯片的第一批客户。
什么是封装技术呢?
封装技术的主要功能是完成电源分配、信号分配、散热和保护等任务。而随着芯片技术的不断发展,推动着封装技术也在不断革新。
而3D封装技术,简单来说,就是指在不改变封装体尺寸的前提下,在同一个封装体内,在垂直方向上叠放两个或者更多芯片的技术。
相较于传统的封装技术,3D封装缩小了尺寸、减轻了质量,还能以更快的速度运转。
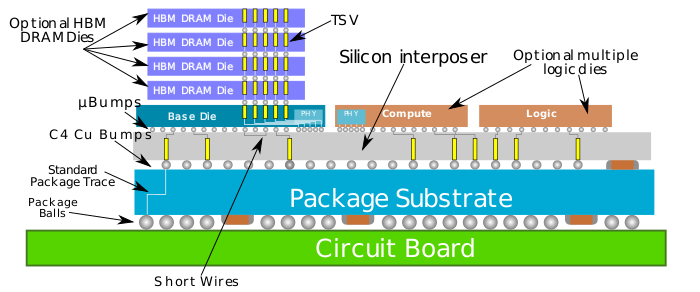
台积电在年度技术研讨会上表示,SoIC是一种创新的多芯片堆叠技术,是一种晶圆对晶圆的键合技术。SoIC的实现,是基于台积电已有的晶圆基底芯片(CoWoS)封装技术和多晶圆堆叠(WoW)封装技术所开发的新一代封装技术。
晶圆基底芯片(CoWoS),全称叫Chip-on-Wafer-on-Substrate,是一种将芯片、基底都封装在一起的技术。封装在晶圆层级上进行。这项技术属于2.5D封装技术。
而多晶圆堆叠技术,或者堆叠晶圆(WoW,Wafer on Wafer),简单来说,就是取代此前在晶圆上水平放置工作单元的技术,改为垂直放置两个或以上的工作单元。这种做法可以使得在相同的面积下,有更多的工作单元被放到晶圆之中。
这样做还有另一个好处:每个晶片可以以极高的速度和最小的延迟相互通信。甚至,制造商还可以用多晶圆堆叠的方式将两个GPU放在一张卡上。
但也存在问题。晶圆被粘合在一起后,一荣俱荣、一损俱损。哪怕只有一个坏了,另一个没坏,也只能把两个都丢弃掉。因此,晶圆量产或成最大问题。
而为了降低成本,台积电只在具有高成品率的生产节点使用这项技术,比如,台积电的16nm工艺。
相较于CoWoS和WoW,SoIC更倚重CoW(Chip on Wafer)设计。对于芯片业者来说,采用CoW设计的芯片,生产上会更加成熟,良率也可以提升。

值得一提的是,SoIC能对小于等于10nm的制作过程进行晶圆级的键合。键合技术无疑会大大提高台积电在这方面的竞争力。
三、性能表现怎么样?
Bow是IPU-POD人工智能计算系统的核心,称为 BOW PODs。
它可以从16个BOW芯片扩展到1024个,提供高达358.4千亿次的计算机运算速度,同时配合多达64个CPU处理器。

新的Bow-2000 IPU Machine是Bow Pod系统的构建块。
它是基于与第二代IPU-M2000 machine同样鲁棒的系统架构,但是配备了四个强大的Bow IPU处理器,可提供1.4 PetaFLOPS的人工智能计算。

这么厉害的芯片,还不赶快拿来练练手?
近年来,语言模型的参数量不断刷新。从惊艳四座的谷歌BERT,到OpenAI的GPT-3,再到微软英伟达推出的威震天等等,都对训练时所需的计算性能提出了更大要求。
根据Graphcore公布的初始数据可以看出,这些模型在最新的硬件形态上都有很大的性能提升。
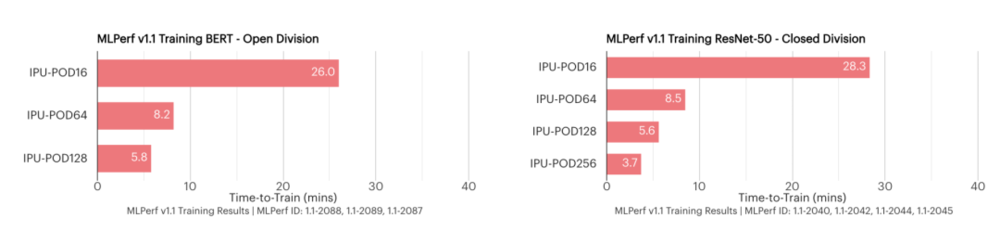
另外,在图像方面,无论是典型的CNN网络,还是近期比较热门的Vision Transformer网络,以及深层次的文本到图片的网络。
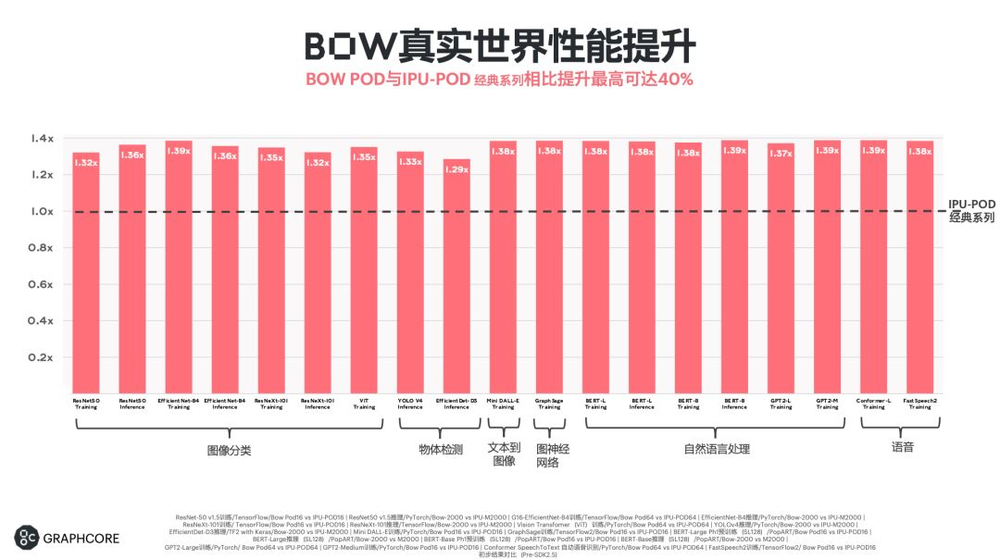
与上一代产品相比,Bow IPU都有30%到40%的性能提升。
对于最先进的计算机视觉模型EfficientNet,Bow Pod16能够提供可比Nvidia DGX A100系统5倍以上的性能,而价格只有它的一半,总体拥有成本优势提升高达10倍。

四、下一步,超级智能AI计算机
Graphcore今天还宣布了一件重大的事,正在开发一款超级智能AI计算机,要在2024年推出,售价1.2亿美元。
我们知道,大脑是一个极其复杂的计算设备,在一个生物神经网络系统中拥有大约1000亿个神经元和超过100万亿个参数,它提供的计算水平是任何芯片计算机都无法比拟的。
而这款超级智能AI计算机Good将超越人类大脑的参数能力。

Good计算机名字何来?是以计算机科学先驱 i.j. Jack Good 的名字命名。
Jack Good在1965年的论文《关于第一台超级智能机器的推测》中就描述了一种超越我们大脑能力的机器。
未来,它可以进行超过10 Exa-Flops的人工智能浮点计算,最高可达4PB的存储,带宽超过10PB/秒。
Graphcore的首席执行官Graphcore表示,“当我们创建 Graphcore 的时候,我们脑海中一直有一个想法,那就是建造一台超智能计算机,它将超越人脑的能力,这就是我们现在正在努力做的事情。”
参考资料:
https://spectrum.ieee.org/graphcore-ai-processor
https://www.zdnet.com/article/ai-computer-maker-graphcore-unveils-3-d-chip-promises-500-trillion-parameter-ultra-intelligence-machine/
https://www.hpcwire.com/2022/03/03/graphcore-launches-wafer-on-wafer-bow-ipu/
本文来自微信公众号:新智元 (ID:AI_era),作者:桃子、拉燕