
TTS(Text-To-Speech,语音合成) 对比熟悉的ASR(语音识别)技术,是将文字转化为声音“朗读出来”,让机器生成自然动听的人类语言。
智能音响克隆了“妈妈”的声音,陪伴孩子安然入睡;这一代的年轻人,想要被爱豆的声音叫醒起床,也是可实现的吗?如今,以siri为代表的语音助手,都是TTS技能运用的常见载体。
语音合成研究,来由已久
思必驰关于语音合成技术研究始于2007年,公司在英国剑桥大学初创立时。经过10多年的研究积累,思必驰在建模方法上,涵盖了从传统的统计参数模型到最新的基于神经网络的方法;对声码器的研究,涵盖了从传统的基于信号处理的方法到最新的基于神经网络的方法。
2017年、2020年,思必驰先后参与国家标准《中文语音合成互联网服务接口规范》与行业标准《中文语音合成服务系统评估规范》的制定,并成为全国首批通过评估测评的公司之一。
思必驰语音合成服务,也已在车载、⽩电、机器⼈、智能客服等诸多领域成功落地。如今,TTS应用即可作为技术单独使用,也可作为语音交互的重要输出环节。伴随语音交互技术应用落地各行业,语音合成技术也找到了用武之地,涵盖公共服务、智能硬件、交通出行、泛娱乐等行业。
让机器真正能与人类产生自由的交流,是一个长期的过程。
现在我们见到,语音合成技术走出实验室,从幕后到台前是AI技术落地的必由之路,交付自主权给用户,让技术在实际应用中迎来曙光。
快速“复刻”个性化声音
近期,思必驰DUI开放平台上线“声音复刻”技术服务,用户通过该平台(www.dui.ai),快速获取思必驰TTS技术服务并集成到产品中,缩短项目落地周期,加快产品迭代更新。
“声音复刻”又称“声音克隆”,是语音合成技术(TTS)的个性化应用,用户可通过少量的录音进行模型训练,得到与用户本人在音色和发音风格上非常相似的声音模型,快速“复刻”个性化声音,该“复刻”声音可使用在讲故事、播天气、读小说、导航播报等功能场景。

思必驰DUI开放平台“声音复刻”技术服务,支持男声、女声、童声的复刻,支持中、英文文本,支持UTF-8等多种文本格式,支持SSML标签控制。
同时,该服务支持8k、16k、32k等多种采样率,支持合成mp3、wav、pcm等多种音频格式……
思必驰DUI开放平台上线该功能,通过短短的几步,即可获取“声音复刻”的超级体验!
第一步,打开思必驰DUI开放平台(www.dui.ai),创建开发者账号,并登录。
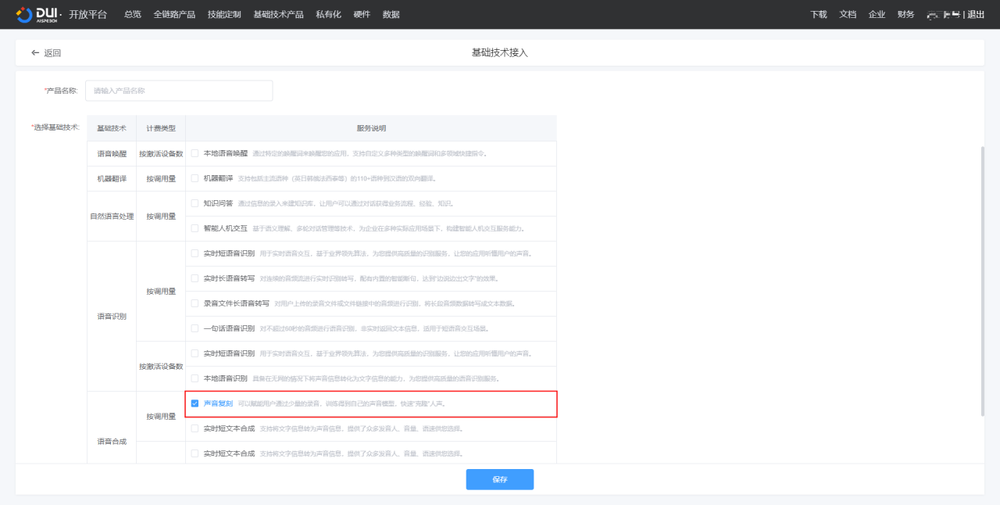
第二步,创建产品,并勾选“声音复刻”服务。
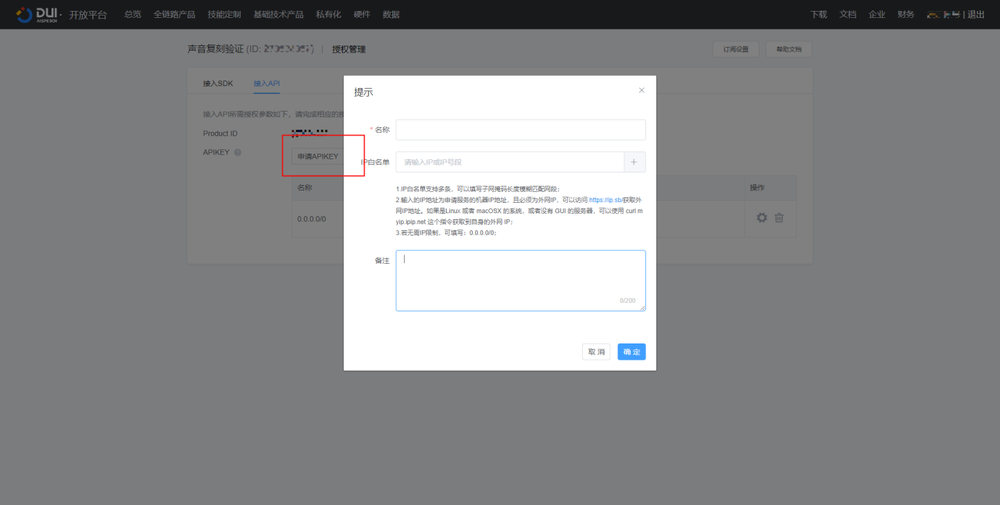
第三步,给创建的产品配置授权参数:选择接入API,创建APIKEY。
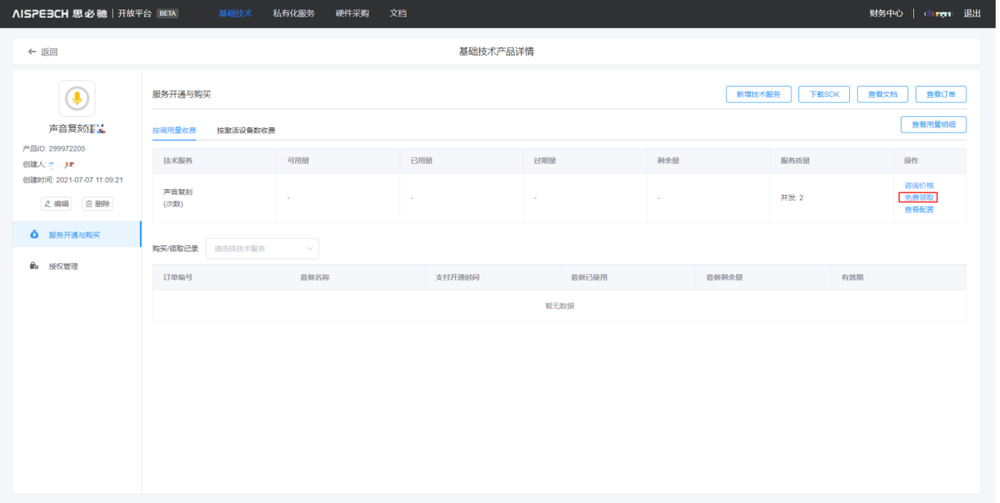
第四步,获取免费调用量套餐包:用于调试时请求训练接口的用量消耗。
(可免费申请100次训练调用量)
按照网页操作指南,即可快速集成声音复刻功能,应用的智能终端产品中,优化产品的语音交互体验。