
本文来自微信公众号:CSDN(ID:CSDNnews),作者:马超,编辑:欧阳姝黎,题图来自:IBM
5 月 6 日晚间,IBM 在全球科技企业的制程大战中,率先突破了 3nm 的极限,成功推出了全球首款采用 2nm 工艺的芯片,虽然这只是实验性质的预研项目,但是根据 IBM 的材料来看,这款 2nm 芯片每平方毫米可容纳 3.33 亿个晶体管,而作为对比目前最先进的台积电 5nm 工艺每平方毫米最多才能容纳 1.713 亿个晶体管,而三星 5nm 工艺每平方毫米最多只能容纳 1.27 亿个晶体管。
IBM 这次最大的突破性进展是将 GAAFET 工艺的样片带到大众面前,本文后面也会介绍 GAAFET 将是硅基半导体突破 FinFET 工艺 5nm 极限的关键技术。本次 IBM 的 GAAFET 采用了 75nm 的单元高度,40nm 的单元宽度,单个纳米片的高度为 5nm,彼此之间间隔 5nm。栅极间距为 44nm,栅极长度为 12nm,其底部采用介电隔离通道、内部的间隔器采用第二代干式工艺的开创性方案。
同时 IBM 也官宣了这款芯片的性能指标,其中与当前主流的 7nm 芯片相比,这款芯片的性能预计提升 45%,能耗降低 75%。而与 5nm 芯片相比,2nm 芯片的体积更小,速度更快。说实话看到这里笔者略感欣慰,因为与 7nm 的经典之作苹果 A12 相比,5nm 的苹果 M1 性能提升近 100%,能耗也低了 50%,也就是说这款 2nm 的 GAAFET 芯片并没有形成对于苹果 M1 的碾压效果,可见 7nm 以下提升制程工艺的效益已经没有那么明显了,这也为我国半导体行业提供了良好的追赶契机。
当然我们自身也有好消息传来,4 月 15 日我国自主的超分辨光刻装备研制项目通过验收,这台光刻机具有 365nm 的光源波长,单曝最高线宽分辨力达到 22nm,虽然严格来讲这并不是一台 EUV 光刻机,但是利用精刀刻细线也就是多重曝光技术,未来这台光刻机应该可以制造 10nm 的芯片,只要能进入到 10nm 俱乐部,那么我们与西方先进工艺就不会有代际差。
一、为什么是制程
上世纪 40 年代由美国发起的曼哈顿计划,不但为人类带来了原子弹,也为我们带来了计算机,IT 行业发展至今已经形成了数十万亿美元的巨大产业,如果说IT行业的明珠是芯片,那么芯片产业的皇冠就是晶圆制造,而晶圆制造的关键又在于制造。
这里也再为大家科普一下制程的相关概念,在上世纪 60 年代,仙童半导体创始人之一摩尔在《电子学》杂志上发表论文,提出了至今仍有巨大影响的摩尔定律,即当价格不变时,集成电路上可以容纳的元器件的数目,将每隔一年增加一倍,这其实就是指原件的密度会不断增大,也就是元件之间的间隔距离不断减少,而在芯片中不同元件的距离就是制程,所以摩尔定律也可以被称为是制程定律。
在不断缩减芯片中晶体管的距离之后,晶体管之间的电容会更低,晶体管的开关频率也会更高。由于晶体管在切换高低电平时动态功率与电容成正比,制程低的芯片可以做到速度快的同时,还能更加省电、更加节能。同时体积越小晶体管的导通电压也就越低,而动态功耗又与电压的平方成反比,这时单位面积能效比也会随之提升。
在 10nm 工艺之前,提升制程几乎是提升芯片性能的代名词,比如 10nm 骁龙 835 体积比 14nm 骁龙 820 还要小了 35%,整体功耗降低了 40%,性能却大涨 27%。因此我们可以看到芯片最大的宣传点往往就是它的制程。
二、芯片的三大时代
正如前文所说本次 IBM 的 2nm 芯片关键性突破就在于给 IT 界带来了真正意义上的 GAAFET 样片,在 GAA 之前半导体的制作工艺主要有 MOS 和 FinFET 两个重要的时代:
MOS 时代:在上世纪 50 年代末贝尔实验室研制出 MOS 管,也就是金属-氧化物半导体场效应晶体管,随着 MOS 管的推出,计算机的电子管时代正式结束,在 MOS 管推出不久后,量产晶体管的平面工艺诞生,这项工艺可以通过氧化、光刻、等一系列的流程,制作出成规模的晶体管集成电路,这也就是我们目前芯片的雏形。不过随着元件密度的不断加大,MOS 管制程限制的劣势也就显现出来了。
FinFET 时代:由于 MOS 管并不尽善尽美,并且其制程存在着 20nm 的极限,业界一直探索着半导体制造工艺的前进方向,不过 MOS 管始终保持着强大的生命力,IT 业一直探索到 2000 年,才由加州大学伯克利分校的胡正明教授找到 FinFET 的方式,当时胡正明教授发表题为《FinFET-a self-aligned double-gate MOSFET scalable to 20 nm》的论文,并在论文中提出了一种名为 “鳍式场效应晶体管”也就是 FinFET 的晶体管结构,顾名思义 FinFET 的结构形状类似于鱼鳍。
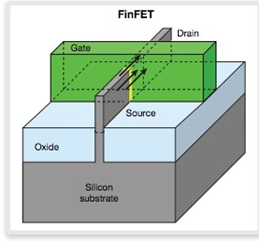
FinFET 使得芯片制程突破了 20nm 的工艺关键节点,是推动当代工艺进一步缩小的关键技术。
未来的 GAAFET 时代:GAA 也就是 Gate-All-Around,是由 Imec 提出的。GAA 的技术特点是实现了栅极对沟道的四面包裹,源极和漏极不再和基底接触,而是利用线状或者平板状、片状等多个源极和漏极横向垂直于栅极分布后,实现 MOSFET 的基本结构和功能。这样的设计在很大程度上解决了栅极间距尺寸减小后带来的各种问题,包括电容效应等,也可以突破目前 5nm 的制程极限,不过从目前 IBM 2nm 芯片的情况来看,这项技术距离正式商用恐怕还有很长的路要走,并且即使突破 5nm,也很难对于 FinFET 结构的芯片产生代差优势。
三、AI 优化:英特尔和 ARM 都在押注的方向
在纷乱的制程之争背后,我们也需要仔细观察其它半导体巨头的发展方向,最近英特尔的至强三代和安谋推出的 ARM v9 似乎都把大招留给了专为优化矩阵运算而设计的 SIMD 技术。
我们看到帕特·基辛格正式回归英特尔之后最新的至强三代推出 Ice Lake-SP 芯片,并随之推出了 AVX-512 与 VNNI 两种 AI 运算加速技术,还有前不久 ARM v9 上的 SVE2,从本质上来说它们都属于 SIMD 技术,而 SIMD 的由来要从芯片流水线技术聊起,我们知道 CPU 的每个动作都需要用晶体震荡而触发,以加法 ADD 指令为例,想完成这个执行指令需要取指、译码、取操作数、执行以及取操作结果等若干步骤,而每个步骤都需要一次晶体震荡才能推进,因此在流水线技术出现之前执行一条指令至少需要 5 到 6 次晶体震荡周期才能完成。

为了缩短指令执行的晶体震荡周期,芯片设计人员参考了工厂流水线机制的提出了指令流水线的想法。由于取指、译码这些模块其实在芯片内部都是独立的,完全可以在同一时刻并发执行,那么只要将多条指令的不同步骤放在同一时刻执行,比如指令 1 取指,指令 2 译码,指令 3 取操作数等等,就可以大幅提高 CPU 执行效率:
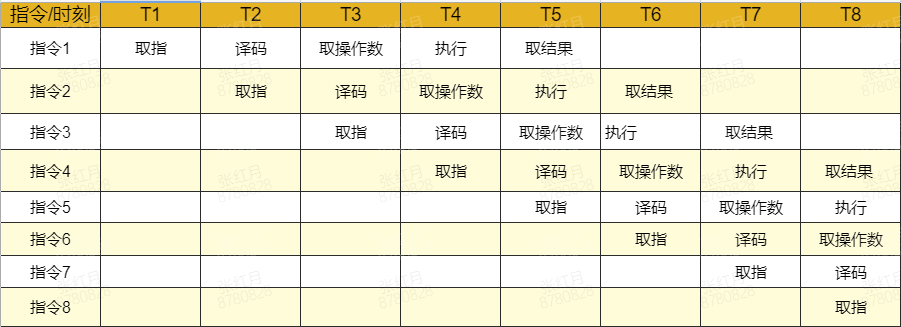
以上图流水线为例 ,在 T5 时刻之前指令流水线以每周期一条的速度不断建立,在 T5 时代以后每个震荡周期,都可以有一条指令取结果,平均每条指令就只需要一个震荡周期就可以完成。这种流水线设计也就大幅提升了 CPU 的运算速度。
SIMD(Single Instruction Multiple Data)也就是单指令多数据流技术,其实就是一种数据流水线的技术,我们知道在 AI 神经网络世界中操作数可能很长,以深度神经网络为例,神经元可以抽象为对于输入数据乘以权重以表示信号强度乘积加总,再由 ReLU、Sigmoid 等应用激活函数调节,本质是将输入数据与权重矩阵相乘,并输入激活函数,对于有三个输入数据和两个全连接神经元的单层神经网络而言,需要把输入和权重进行六次相乘,并得出两组乘积之和。这实际上就是一个矩阵乘法运算。而一个操作数往往只能表示矩阵中的一个元素,这也使得传统 CPU 在进行矩阵运算时效率很低。
而英特尔的 VNNI(Vector Neural Network Intruction)和ARMv9的SVE2恰恰都是支持变长输入的指令集。
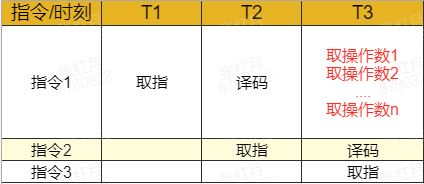
读者们可把这项技术简单理解为在一个周期内可以将指令所需的所有操作数全部取到,而且读操作数的个数还是可变长的,这样矩阵运算的效率就可以大大提升。
目前 ARMv9 芯片还没有产品发布,而至强三代的处理器已有推出一段时间了,从笔者了解到的情况看,可变长的 VNNI 在腾讯应用时,可以使 2D 转 3D 的建模速度提升 4.24 倍以上,这意味着原有基于 3D 人脸建模比较慢的各种优化、缓存、预处理都不需要了,在大部分场景当中腾讯都能为游戏玩家提供所见即所得的 3D 头像。
总而言之我们这次的好消息是 GAAFET 并没有强到能与现有 FinFET 工艺拉开代差的地步,同时我们也要清醒认识到半导体领域更具有基础科学的属性,只能结硬寨,打硬仗,没有捷径可言。
本文来自微信公众号:CSDN(ID:CSDNnews),作者:马超(CSDN博客专家,阿里云MVP、华为云MVP,华为2020年技术社区开发者之星)