
IT产品的国际化是一大趋势,但是在转向国际化的过程中,往往会出现不少的问题,导致走了一些歪路。本文作者总结了自己做IT产品国际化的经验,对“国际化”和“支持英文”这两个完全不同的概念进行了区分,并且列举了一些例子,希望看后能够对你有所启发。本文来自微信公众号:余晟以为(ID:yurii-says),作者:余晟,题图来自:pixabay
几年前在纽伦堡见了个朋友,吃饭间问起他太太在德国做什么,答曰“国际化”,细问之下才发现:光是“中文化”就有一整个团队。
这个消息让我挺吃惊。
按照我们之前的理解,“国际化”主要就是要配备好对应的资源文件,针对不同语言的客户,显示不同的语言即可。
按照这种思路,“国际化”里最重要的就是要把所有的文字都抽离出来作为可配置资源,千万不要写死。
可以说,一旦你的产品可以同时支持中英两种语言,就迈过了国际化最大的障碍。增加其它语言的支持,就像“多来个人吃饭,无非多添一双筷子”。
这几年自己开始做IT产品的国际化,才深深感觉到:“国际化”和“支持英文”之间相差了十万八千里。甚至可以说,两者完全是风马牛的关系。
如果你觉得无法想象,看完下面这些例子就会明白。
例子一:文字
文字大概是许多人提到“国际化”时最早想到,也唯一能想到的因素了。
没错,国际化的第一步就是要支持多种文字的显示。
业界通常的办法是做一份资源文件,包含了各种语言的统一映射;在需要显示的时候,直接在资源文件里检索对应语言的资源,就可以得到对应的文字。
资源文件的结构类似下面这样:

这种办法有问题吗?
看起来很直观,没问题对吧?
其实有问题。
问题不在文字的内容,而在文本的长度。
大部分情况下,中文和对应英文的文本长度是差不多的,所以显示时占据的空间差不多,并不会影响原有的UI元素。但是有些时候,中文和英文的长度相差很大,在一些紧密排版的情况下,显示就会有问题。

这还不是最麻烦的。如果长度不够,可以在空格处换行,一般都还可以应付,只是高度会变化。但是对于其它语言,比如德语,情况就复杂多了。德语经常会把不同的单词拼起来,排版时如果没有考虑,最终的效果可能特别糟糕。
比如“新天鹅堡”的德文是Neueswanstein,直接替换的话就会是下面的样子:
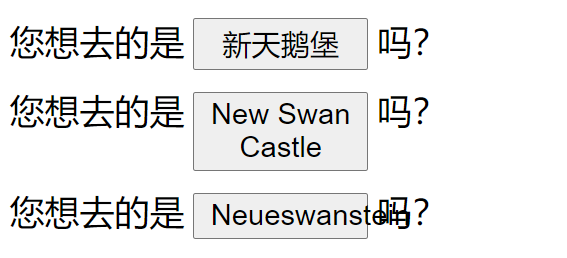
Neueswanstein的长度在德语里其实不算什么,随便可以找到更长的,比如下面这个(不要怕,其实它的意思只是数字1532而已):
Eintausendfünfhundertzweiunddreißig
所以,如果你只翻译文字,不在UI布局上考虑,就可能吃大亏。
如今流行“出海”,我在德国看到了不少国内的电子产品也提供了德文界面,但是实话说,不少界面堪称惨不忍睹。
文字方面的问题,除了显示,查找也会有问题。英语之外的语言,尤其是欧洲国家的语言,经常会有一些字母看起来有特殊符号。比如德语中的Ü、ü、Ä、ä、Ö、ö(上面的两点叫Umlaut)。
我们以Ü来举例,看起来它“应该是一个字母”,确实对应键盘上的一个键,而且在Unicode规范中也确实分配了对应的Code Point(U+00DC)。
那么,如果你在“查找”框里输入Ü,能找到所有出现的Ü吗?
答案是:也许能,也许不能。
什么情况下不能呢?
因为Unicode规范中还有许多特殊字符,比如U+0308,这个字符叫COMBINING DIAERESIS,说白了就是那“两点”。它可以和元音字母结合,显示为一个字符。
所以你看到一模一样的Ü,既可能是U+00DC,也可能是U+0055 U+0308(U+0055就是大写的U)。如果开发软件时不考虑这一点,就可能被用户痛骂:明明看到文本里有Ü,在搜索框里怎么也搜不到,这是什么破软件!
例子二:时间
中国的时区是非常规整的,全国统一用北京时间,所以对许多程序员来说,时间“天然”就是统一的,简单的。如果要换到其它时区,那也只是增减几个小时,多算一个偏移量就可以。
比如德国使用的是柏林时间,柏林时间目前和北京时间相差6小时,那么如果要在系统里支持柏林时间,每次存取的时候都“以北京时间-6小时”即可。北京时间早上6点,柏林时间0点;北京时间下午3点,柏林时间早上9点……
这样就足够了吗?
显然不是。
要知道,许多国家都有“夏令时”的规定(其实中国以前也有)。也就是说,在一年中的不同时段,柏林时间和北京时间的差距是会变化的。有时候是7小时(冬令时),有时候是6小时(夏令时)!
而且,冬令时和夏令时的切换日期并不固定。冬令时是每年10月的最后一个周日,凌晨3时将时钟拨回去1小时;夏令时是每年3月的最后一个周日,凌晨2时将时钟拨快1小时。
如果自己写程序处理这种变化,估计要烦死,还不一定能保证正确。
所以不少系统都内置了“时区”的设置和相关函数,自动帮用户换算时间。可惜,有不少程序员似乎不理解为何“时区”的设置很重要,还是习惯自己算偏移值,这可真是不折不扣的“拿金饭碗要饭”。
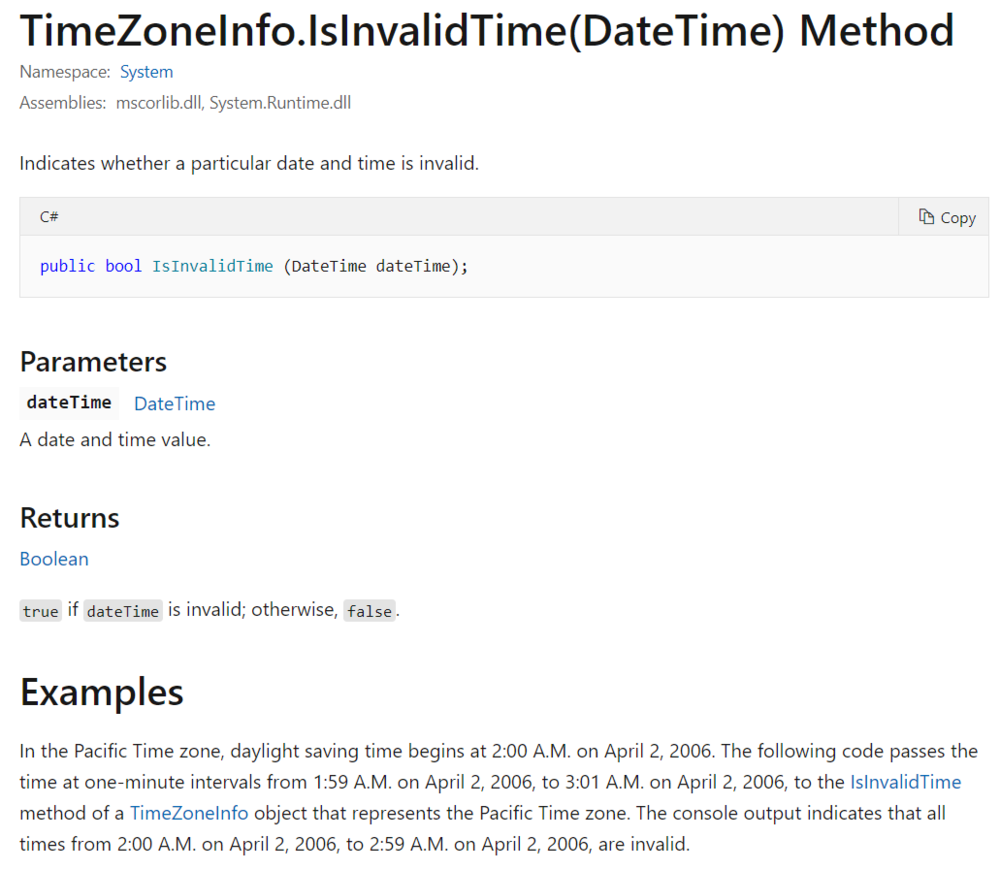
如果你仔细观察上面的例子,还会发现一个问题:在某些系统里,时间不是连续的。
比如在冬令时切换夏令时的那一刻,其实有个空缺,也就是“不存在的一小时”。具体到今年(2021年),柏林时间的3月28日,凌晨02:00:00到02:59:59,都是不存在的。
所以,尽管2021-03-28 02:30:21看起来是一个完全正常的时刻,但是如果时区选择了柏林时间,它就是非法的。
这种情况不只在德国存在,其实广泛存在着。
如果你留意的话,各种语言里都有对应的说明。
例子三:标点
许多开发人员都知道,系统里有个重要的变量叫locale,它代表了与本地化有关的一组设置。
最常见的,比如中日韩文字中有许多“看起来一样”的文字,其实有细微差别。但是,为了节省Unicode中的空间,给它们指定了同样的Code Point,显示的时候就靠locale来区分。
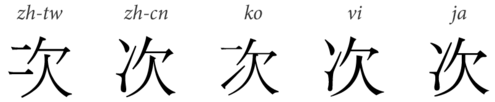
但是locale的作用不止于此。同样的标点符号,在不同的语言中,作用也是不同的。
比如半角逗号“,”,在英文里表示逗号,但是在德语和法语里,它表示小数点,所以3.14在德语里应当写作3,14,而7.99在德语里应当写作7,99。如果你仍然用半角逗号来切分句子,多半要碰得头破血流。
相反,如果你懂得locale,能从系统变量里读取line.separator作为分隔符,就省去了这种烦恼。
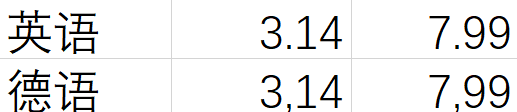
更让人意想不到的是,常见的CSV文件,也就是“逗号分隔值文件Comma Separated Value”,在德国也会有完全不一样的规定。
因为德语里comma是小数点,所以即便CSV叫“逗号分隔值”,它也不能用逗号(comma)来分隔,而应当用分号(semicolon)来分隔。

所以,如果你的CSV处理程序本来跑得好好的,忽然报了一大堆错,没准就是这里出的问题。
不要为这一点“意想不到”吃惊,还有更加“意想不到”的情况:Excel的函数里,我们会用逗号来分隔多个参数,但是在德语版Excel里,逗号必须替换为分号,否则一定会报错。
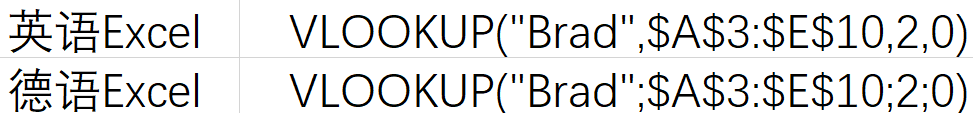
上面这些例子,说穿了平淡无奇,但没有说穿的时候,往往让人绞尽脑汁,所以不要问我怎么知道的,这是血泪的教训。
也恰恰是在积累了许多血泪教训之后,我才发现:微软的国际化真的做得很好,各种情况都考虑到了,甚至可以说是业界的翘楚——不过,那估计也是积累了无数血泪教训的结果吧。
本文来自微信公众号:余晟以为(ID:yurii-says),作者:余晟