
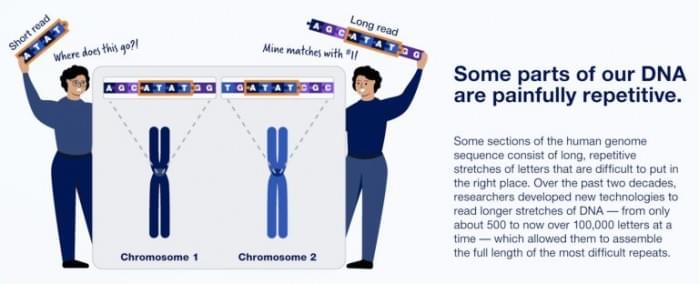
当科学家们在2003年宣布人类基因组的完整序列时,实际上当时仍有大约8%尚未被完全破译。这主要是因为它由高度重复的DNA片段组成,很难与其他部分啮合。但是,一个为期三年的联盟终于填补了剩余的DNA研究空白,为科学家和医生提供了第一个完整的、无间隙的基因组序列供参考。

新完成的基因组被称为T2T-CHM13,代表了目前参考基因组的一个重大升级,该基因组被医生用来寻找与疾病有关的突变,以及被研究人类遗传变异进化的科学家使用。
除其他事项外,新的DNA序列揭示了关于着丝粒(centromere)周围区域的前所未有的细节,着丝粒是细胞分裂时染色体被抓取和拉开的地方,确保每个“子”细胞继承正确的染色体数量。这个区域内的变异性也可能为我们的人类祖先如何在非洲进化提供新的证据。
加利福尼亚大学伯克利分校的博士后研究员Nicolas Altemose说:“揭示这些以前缺失的基因组区域的完整序列告诉我们很多关于它们是如何组织起来的,这对于许多染色体来说是完全未知的。”他是四篇关于已完成基因组的新论文的共同作者。“以前,我们只是对那里的情况有最模糊的了解,而现在它已经清晰到了单碱基对的分辨率。”
Altemose是一篇描述着丝粒周围碱基对序列的论文的第一作者。一篇解释如何进行测序的论文出现在4月1日的《科学》杂志印刷版上,而Altemose的着丝粒论文和其他四篇描述新序列告诉我们什么的论文在该杂志上进行了总结,论文全文发布在网上。四篇配套论文,包括Altemose是共同第一作者的一篇,也于4月1日在《自然方法》杂志上在线发表。
测序和分析是由一个由100多人组成的团队完成的,即所谓的“端粒到端粒”联盟(T2T),以覆盖所有染色体末端的端粒命名。该联盟的所有22条常染色体和X性染色体的无间隙版本由30.55亿个碱基对组成,这些碱基对是构建染色体和我们的基因的单位,还有19969个蛋白质编码基因。在蛋白质编码基因中,T2T团队发现了大约2000个新的基因,其中大部分是禁用的,但其中115个可能仍在表达。他们还在人类基因组中发现了大约200万个额外的变体,其中622个发生在医学相关的基因中。
“将来,当某人的基因组被测序时,我们将能够识别他们DNA中的所有变体,并利用这些信息更好地指导他们的医疗保健,”T2T的领导人之一、美国国立卫生研究院国家人类基因组研究所(NHGRI)的高级调查员Adam Phillippy说。“真正完成人类基因组序列就像戴上了一副新眼镜。现在我们可以清楚地看到一切,我们离理解这一切意味着什么又近了一步。”
不断演变的着丝粒
着丝粒内和周围的新DNA序列共占整个基因组的6.2%,即近1.9亿个碱基对,或核苷酸。在剩下的新增加的序列中,大部分被发现在每条染色体末端的端粒周围和核糖体基因周围的区域。整个基因组仅由四种类型的核苷酸组成,这些核苷酸以三组为单位,对用于构建蛋白质的氨基酸进行编码。Altemose的主要研究涉及寻找和探索染色体上蛋白质与DNA相互作用的区域。
Altemose说:“没有蛋白质,DNA就什么都不是。”在获得牛津大学统计学博士学位后,他于2021年在加州大学伯克利分校和旧金山分校联合获得了生物工程博士学位。“DNA是一组指令,如果它周围没有蛋白质来组织它,调节它,在它受损时修复它,并复制它,就没有人可以读懂它。蛋白质与DNA的相互作用确实是基因组调控的所有行动发生的地方,能够绘制出某些蛋白质与基因组结合的位置,对于理解它们的功能真的很重要。”
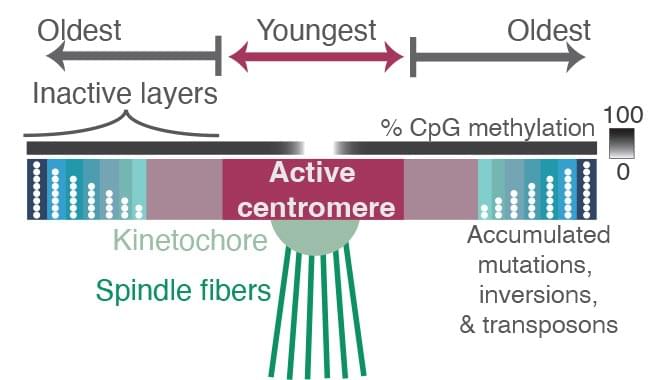
在T2T联盟对缺失的DNA进行测序后,Altemose和他的团队使用新技术找到了着丝粒内的位置,在那里,一个被称为"动粒"的大蛋白复合物牢固地抓住了染色体,以便细胞核内的其他机器能够将染色体对拉开。
他说:“当这出错时,你最终会出现染色体错误分离的情况,而这将导致各种问题。如果这发生在减数分裂中,这意味着你可能出现染色体异常,导致自发流产或先天性疾病。如果它发生在体细胞中,你可能最终患上癌症--基本上,有大量错误调节的细胞。”
他们在着丝粒内和周围发现的是新的序列层叠在旧的序列层上,就像通过进化,新的着丝粒区域被反复铺设以结合到动粒上。旧区域的特点是有更多的随机突变和缺失,表明它们不再被细胞使用。较新的与动粒结合的序列变化较少,而且甲基化程度也较低。甲基化的增加是一个表观遗传标签,倾向于使基因沉默。
着丝粒内和周围的所有层都是由重复长度的DNA组成的,基于一个大约171个碱基对长的单位,这大约是包裹着一组蛋白质形成核糖体的DNA的长度,保持DNA的包装和紧凑。这些171个碱基对的单位形成了更大的重复结构,被串联重复多次,在着丝粒周围建立了一个大的重复序列区域。
T2T团队只关注一个人类基因组,该基因组是从一个被称为葡萄胎的非癌症肿瘤中获得的,它本质上是一个拒绝母体DNA而复制其父体DNA的人类胚胎。这样的胚胎会死亡并转化为肿瘤。但是这个痣有两个相同的父系DNA副本--都带有父亲的X染色体,而不是来自母亲和父亲的不同DNA--这一事实使它更容易测序。
Altemose说,研究人员本周还发布了一个来自不同来源的Y染色体的完整序列,该序列花费的时间几乎与基因组的其他部分加起来一样长。对这个新的Y染色体序列的分析将出现在未来的出版物中。
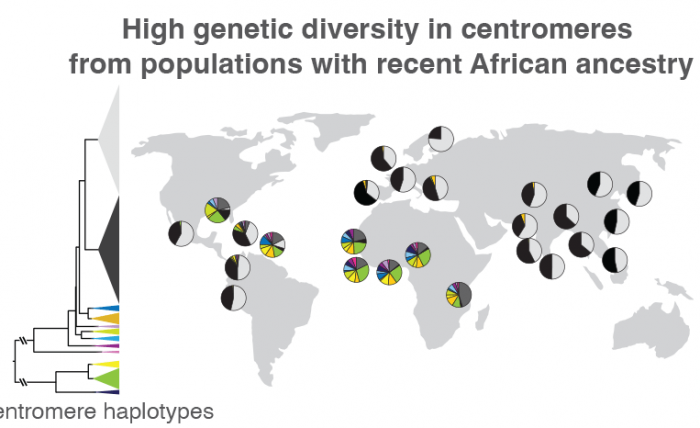
Altemose和他的团队,包括加州大学伯克利分校的项目科学家Sasha Langley,还用新的参考基因组作为支架,比较了来自世界各地的1600个个体的中心粒DNA,揭示了着丝粒周围重复DNA的序列和拷贝数的重大差异。以前的研究表明,当古人类群体从非洲迁移到世界其他地方时,他们只带走了一小部分基因变体的样本。Altemose和他的团队证实,这种模式延伸到了着丝粒。
Altemose说:“我们所发现的是,在非洲大陆以外的具有近期血统的个体中,他们的着丝粒,至少在X染色体上,往往分为两个大的集群,而大多数有趣的变异是在具有近期非洲血统的个体中。鉴于我们对基因组其他部分的了解,这并不完全是一个惊喜。但它所表明的是,如果我们想看看这些着丝粒区域的有趣变异,我们确实需要集中精力对更多的非洲基因组进行测序,并进行完整的端粒到端粒的序列组装。”
他指出,着丝粒周围的DNA序列也可以用来追踪人类的血统,追溯到我们共同的猿人祖先。
Altemose说:“当你远离活跃的着丝粒部位时,你会得到越来越多的退化序列,以至于如果你走到这个重复序列‘海洋的最远海岸’,你开始看到古老的着丝粒,也许,我们的灵长类祖先的着丝粒曾经与动粒结合。这几乎就像化石的层次。”
长读测序“改变了游戏规则”
T2T的成功归功于一次对长DNA片段进行测序的改进技术,这有助于确定高度重复的DNA片段的顺序。其中有PacBio的HiFi测序技术,它可以高精度地读取长度超过20,000个碱基对的数据。另一方面, Oxford Nanopore技术有限公司开发的技术可以读取多达几百万个碱基对的序列,尽管保真度较低。作为比较,Illumina公司的所谓下一代测序技术仅限于数百个碱基对。
Altemose说:“这些新的长读DNA测序技术真是令人难以置信;它们是这样的游戏改变者,不仅对于这个重复的DNA世界,而且因为它们允许你对单个长的DNA分子进行测序。你可以开始在一个分辨率水平上提出问题,这在以前是不可能的,即使是短读测序方法也不可能。”
Altemose计划进一步探索着丝粒区域,使用他和斯坦福大学的同事开发的一种改进技术来确定染色体上被蛋白质结合的位置,类似于动粒与着丝粒结合的方式。这项技术也使用了长读测序技术。他和他的小组在本周发表在《自然方法》杂志上的一篇论文中描述了这种技术,称为定向甲基化与长读测序(DiMeLo-seq)。
同时,T2T联盟正在与人类泛基因组参考联盟合作,致力于建立一个代表全人类的参考基因组。
Altemose说:“我们应该有一个代表每个人的参考,而不是仅仅从一个人类个体或一个葡萄胎(甚至不是真正的人类个体)获得一个参考。关于如何实现这一目标,有各种想法。但是我们首先需要的是掌握这种变异是什么样子的,我们需要大量高质量的个体基因组序列来完成这个任务。”
他在着丝粒区域的工作,他称之为"一个激情项目",是由博士后奖学金资助的。T2T项目的负责人是加州大学圣克鲁兹分校的Karen Miga、华盛顿大学的Evan Eichler和NHGRI的Adam Phillippy,后者提供了大部分的资金。加州大学伯克利分校着丝粒论文的其他合著者是生物工程副教授Aaron Streets;分子和细胞生物学教授Abby Dernburg和Gary Karpen;项目科学家Sasha Langley;以及前博士后研究员Gina Caldas。