
垃圾邮件检测器模型可以自动检测垃圾邮件,但我们需要在大型电子邮件数据集上训练它们,并对它们进行人工标注。这就是印度 Sinhgad 理工学院 Lonavala 分校的研究人员希望解决的问题。相关论文发表在《International Journal of Intelligent Robotics and Applications》上。
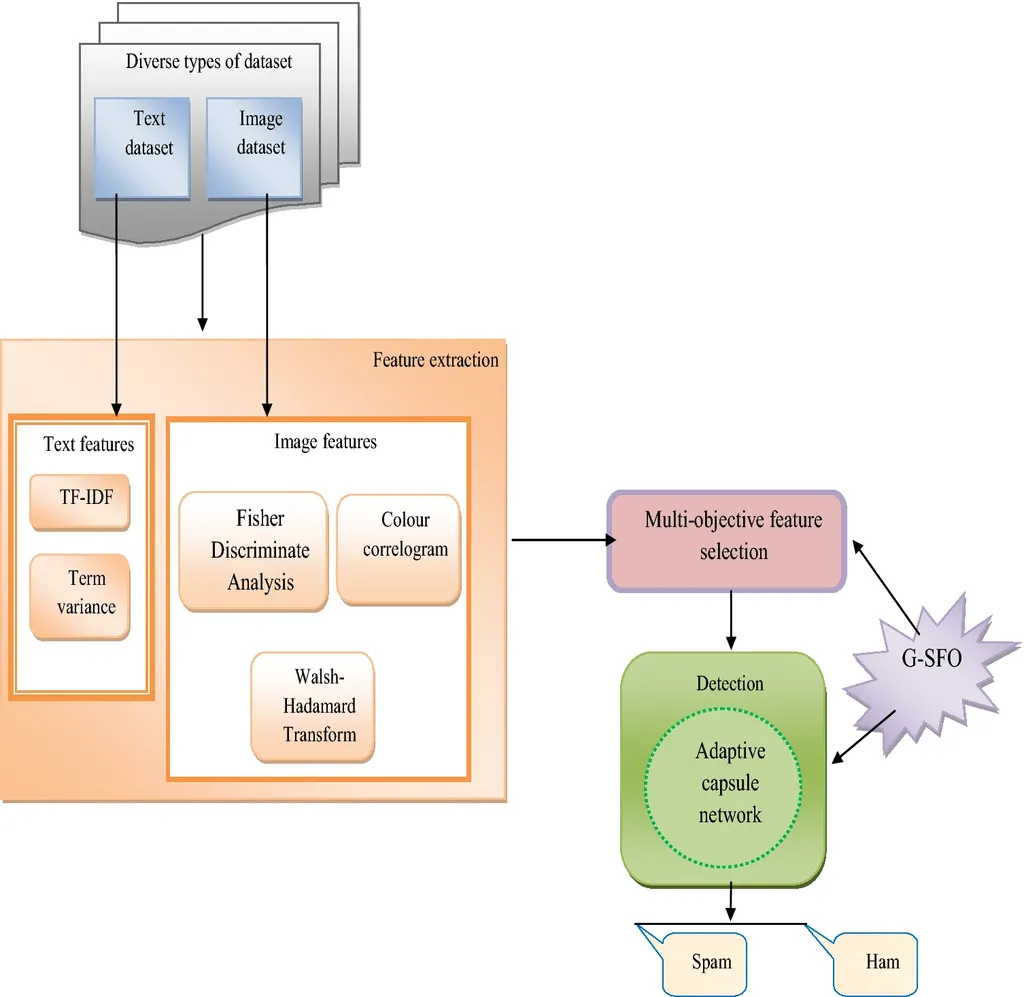
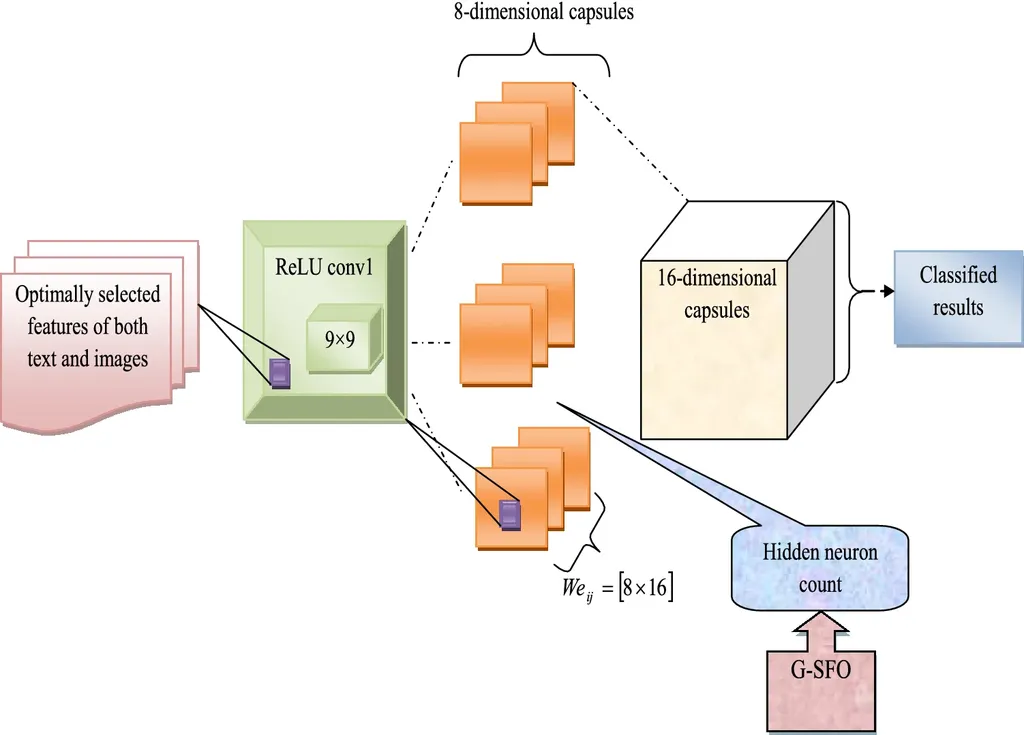
该项目的研究人员之一 Vikas Samarthrao Kadam 说:“垃圾邮件检测是至关重要的,因为它可以确保卖家的公正,并保留买家对网店的信任。与其他方法相比,它提高了训练速度和分类效率。我们的模型可以随着收到大量电子邮件的人的生活质量的提高,使他们能够顺利地浏览他们的电子邮件,并且只为他们的预期目的使用他们的账户”。
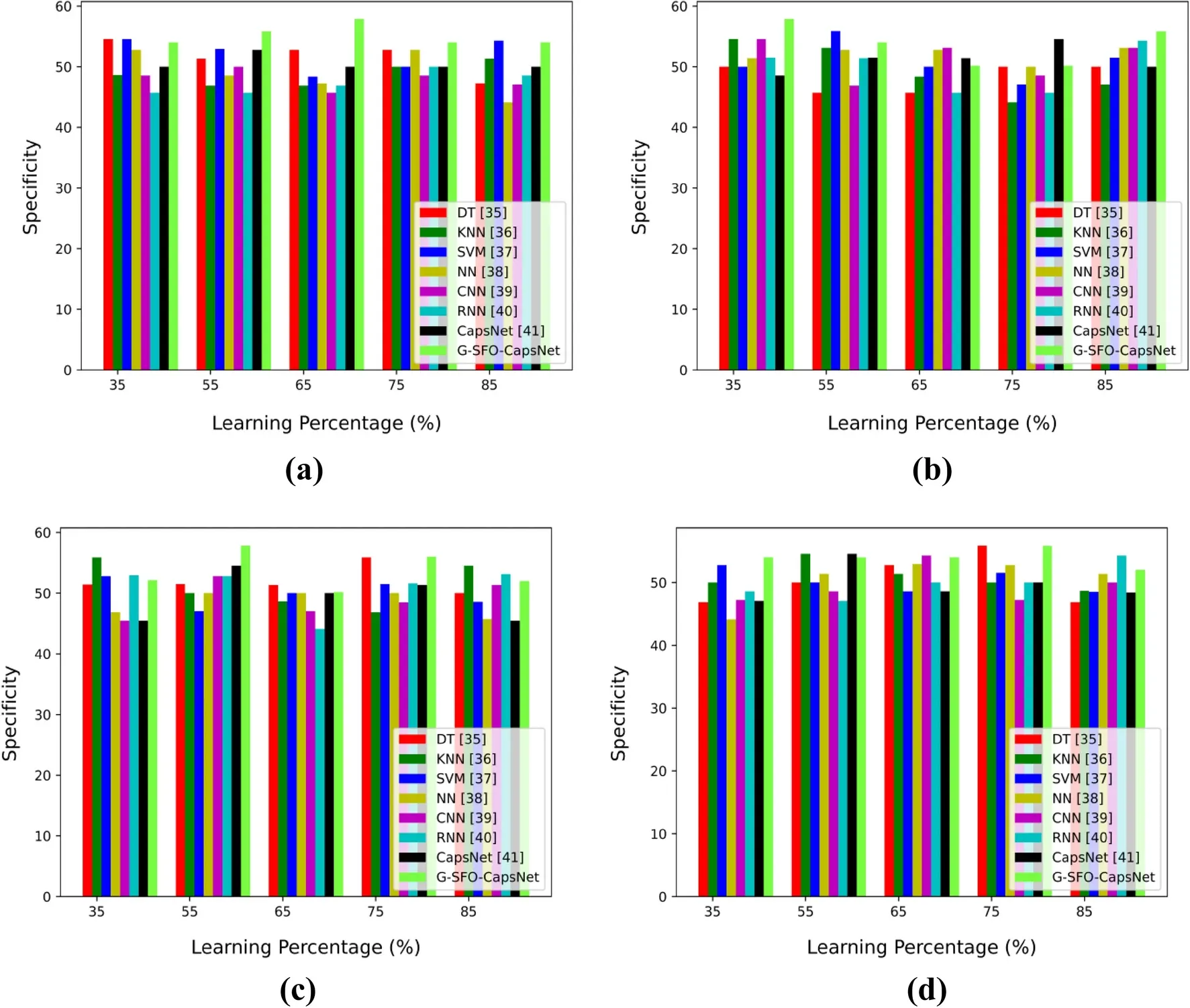
该团队开发了一个基于多目标特征选择和自适应胶囊网络的模型,并在图像和文本数据集上进行训练。据称,这种使用深度学习技术的模型提供了简单的实现方式,可以在短时间内快速训练。Kadam 说,他们的初步评估显示,新模型拥有比其他现有方法更高的准确性。该团队指出,这可以帮助提高用户的安全性,并帮助他们更好、更容易地撇开无关的电子邮件。
在接受 TechXplore 采访的时候,Kadam 表示:“我们的模型也降低了训练速度,并导致了更高的分类效率。与其他模型相比,它提高了垃圾邮件检测的收敛率,取得了更好的效果”。
另一方面,该小组表示,该模型仍然需要开发,以确保在速度和精度方面的最大效率。不过,一旦准备就绪,这种垃圾邮件过滤技术就可以大规模使用,包括在Gmail、雅虎邮箱和Outlook上使用。
Kadam 表示:
垃圾邮件检测和过滤系统的安全性对于实现更好的准确性和可靠的结果至关重要,这可以在未来使用集合学习来改进。许多模型的误报率仍然高于要求,但今后应减少到尽可能小的数值。实时垃圾邮件分类是非常需要的,因为大多数提出的模型在实时数据中不能很好地工作......
几乎所有的研究人员都根据他们的模型的准确性、精确性和召回率来展示他们的结果,但我们觉得机器学习模型的时间复杂性也应该被视为一个评估指标。
一些研究人员在使用词包进行特征提取的过程中显示出有希望的结果,因为他们声称电子邮件的标题对于垃圾邮件的检测和正文内容一样重要。因此,未来也可以考虑对标题行进行深度特征提取。