
跟大多数事物一样,自然界的数据存储系统--DNA远远超过了我们所创造的任何东西。现在,伊利诺伊大学厄巴纳-香槟分校的研究人员通过在其“字母表”上增加额外的字母来将其令人难以置信的存储能力提高了一倍并开发了一种新的方法来读取它。
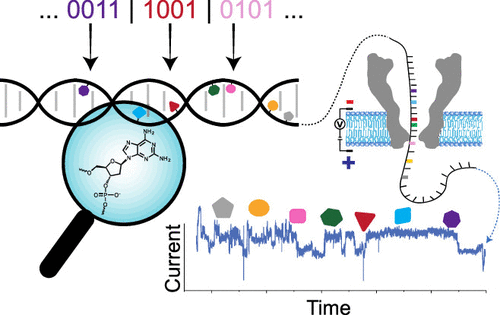
DNA是由四个核碱基的自然组合组成:腺嘌呤、鸟嘌呤、胞嘧啶和胸腺嘧啶。这些碱基以字母A、G、C和T表示,以不同的序列组合在一起进而形成每个生物体的蓝图。而这种信息存储系统的密度令人难以置信,一克DNA能存储多达215PB(2.15亿GB)的数据。
这当然使它成为现代社会每天产生的大量数据的一个非常具有吸引力的潜在存储解决方案--互联网的全部内容都可以装在一个装满DNA的鞋盒里。并且,如果这种存储还不够密集的话,新研究的研究人员已经找到了一种将其加倍的方法。
除了通常的A、G、C和T之外,研究小组在DNA字母表中有效地增加了七个“字母”。这些字母采取化学改性核苷酸的形式开辟了更多不同的组并允许在相同数量的物理空间内存储更多的信息。
“想象一下英语字母表,”该研究的论文共同作者Kasra Tabatabaei说道,“如果你只有四个字母可以使用,那么你只能创造出这么多单词。如果你有完整的字母表,你可以产生无限的单词组合。这跟DNA是一样的。我们可以将零和一转换为A、G、C和T,而不是将零和一转换为A、G、C、T及存储字母表中的七个新字母。”
当然,增加额外的核苷酸意味着现有的读取数据系统不会识别它们,所以该团队还开发了一个能识别的新系统。DNA链通过一个专门设计的蛋白质中的纳米孔来检测各个单元--无论它们是天然的还是合成的。然后机器学习算法对储存在其中的信息进行解码。
“我们尝试了11种核苷酸的77种不同组合,我们的方法能完美区分每一种,”该研究的论文共同作者Chao Pan说道,“作为我们识别不同核苷酸的方法的一部分的深度学习框架是通用的,这使得我们的方法可以通用于许多其他应用。”
除了密度,新方法还提高了数据的写入速度,这通常是一个相当迟缓的DNA过程。这个系统约将向DNA写入信息所需的时间减半。
这项工作可能有助于使DNA成为一个可行的数据存储系统,当然在实现之前仍有大量的工作要做。