
抗体是由免疫系统产生的小型蛋白质,可以附着在病毒的特定部分以中和它。随着科学家们继续与SARS-CoV-2(引起COVID-19的病毒)作斗争,一种可能的“武器”是一种合成抗体,它能与病毒的刺突蛋白结合,防止病毒进入人体细胞。为了开发出一种成功的合成抗体,研究人员必须准确了解这种结合将如何发生。蛋白质具有包含许多褶皱的块状三维结构,可以以数百万种组合粘在一起,因此在几乎无数的候选者中找到正确的蛋白质复合物是非常耗时的。
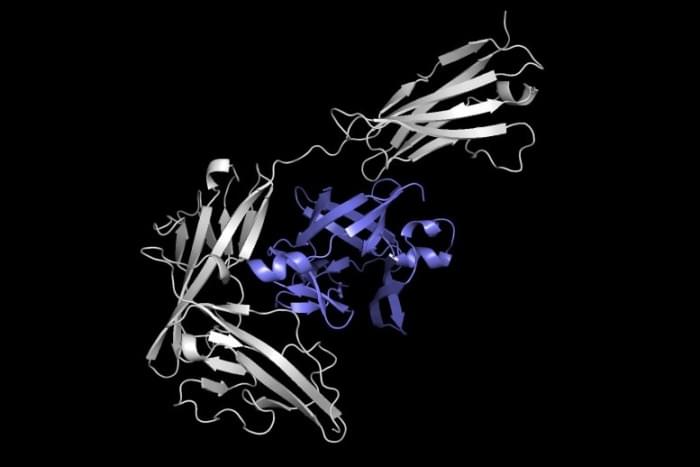
为了简化这一过程,麻省理工学院的研究人员创建了一个机器学习模型,可以直接预测两个蛋白质结合在一起时将形成的复合物。他们的技术比最先进的软件方法快80到500倍,并且经常预测的蛋白质结构更接近于实验观察到的实际结构。
这项技术可以帮助科学家更好地理解一些涉及蛋白质相互作用的生物过程,如DNA复制和修复;它还可以加快开发新药的进程。
“深度学习非常善于捕捉不同蛋白质之间的相互作用,否则化学家或生物学家很难通过实验写出来。其中一些相互作用非常复杂,而人们还没有找到很好的方法来表达它们。”麻省理工学院计算机科学与人工智能实验室(CSAIL)的博士后、该论文的共同第一作者Octavian-Eugen Ganea说:“这种深度学习模型可以从数据中学习这些类型的相互作用。”
Ganea的共同第一作者是苏黎世联邦理工学院的研究生Xinyuan Huang。麻省理工学院的共同作者包括Regina Barzilay,CSAIL的工程学院人工智能和健康杰出教授,以及Tommi Jaakkola,CSAIL的Thomas Siebel电子工程教授和数据、系统和社会研究所的成员。该研究将在学习表征国际会议上发表。
研究人员开发的模型被称为Equidock,专注于刚体对接--当两个蛋白质通过在三维空间中的旋转或平移而附着时,就会出现这种情况,但它们的形状不会被挤压或弯曲。该模型采用两种蛋白质的三维结构,并将这些结构转换为可由神经网络处理的三维图形。蛋白质是由氨基酸链形成的,其中每个氨基酸都由图中的一个节点表示。
研究人员在模型中加入了几何知识,因此它了解如果物体在三维空间中旋转或平移,它们会如何变化。该模型还内置了数学知识,确保蛋白质总是以相同的方式附着,无论它们在三维空间中存在于何处。这就是蛋白质在人体内的对接方式。
利用这些信息,机器学习系统确定了两种蛋白质中最有可能相互作用并形成化学反应的原子,称为结合袋点。然后它利用这些点将两种蛋白质放在一起形成一个复合体。
“如果我们能从蛋白质中了解哪些个别部分可能是这些结合袋点,那么这将捕捉到我们将这两种蛋白质放在一起所需的所有信息。假设我们能找到这两组点,那么我们就可以找出如何旋转和翻译蛋白质,使一组与另一组相匹配,”Ganea解释说。
建立这个模型的最大挑战之一是克服缺乏训练数据的问题。Ganea说,由于蛋白质的实验性三维数据太少,将几何知识纳入Equidock尤为重要。如果没有这些几何约束,该模型可能会在数据集中发现错误的关联性。
在模型被“训练”出来后,研究人员将其与四种软件方法进行了比较。Equidock只需一到五秒就能预测出最终的蛋白质复合物。所有的基线都需要更长的时间,从10分钟到一个小时或更长时间。
在质量衡量方面,即计算预测的蛋白质复合物与实际的蛋白质复合物的匹配程度,Equidock经常与基线相当,但有时表现得比它们差。
“我们仍然落后于其中一条基线。我们的方法仍然可以改进,它仍然可以是有用的。它可以用于一个非常大的虚拟筛选,我们想了解成千上万的蛋白质如何相互作用并形成复合体。”Ganea说:“我们的方法可以用来非常快速地生成一组最初的候选人,然后可以用一些更准确但更慢的传统方法对这些候选人进行微调。”
除了将这种方法用于传统模型外,该团队还希望将特定的原子相互作用纳入Equidock,以便它能做出更准确的预测。例如,有时蛋白质中的原子会通过涉及水分子的疏水相互作用而附着。
Ganea说,他们的技术也可以应用于类似药物的小分子的开发。这些分子以特定的方式与蛋白质表面结合,因此快速确定这种附着是如何发生的可以缩短药物开发的时间。
在未来,他们计划加强Equidock,使其能够为灵活的蛋白质对接做出预测。那里最大的障碍是缺乏训练数据,所以Ganea和他的同事们正在努力生成他们可以用来改进模型的合成数据。