
科学家通过对神经网络的研究发现,大脑是一台名副其实的“预测机器”。这样的工作方式使它们能节省许多能量。我们的大脑包裹在硬质的颅骨中,是一团重约1.4至1.5千克组织。长期以来,关于大脑如何通过感觉来获得感知的问题,一直令科学家感到困惑。
150秒看马斯克脑机接口震撼进展:无损植入猪脑,下一步人脑
来源:quantamagazine
撰文:Anil Ananthaswamy
翻译:任天

当看到一个模糊的图像时,我们会依赖背景来获得感知信息。一些神经科学家认为,这证明了大脑能通过对预期事件的预测,自上而下地将感知信息组合起来
大量的证据和数十年的持续研究表明,大脑并不能像玩拼图游戏那样,将感官信息简单地组合起来,以此感知周围的环境。我们可以通过一个事实来证明这一点,大脑可以根据进入眼睛的光线信息构建出一个场景,即使这些信息既嘈杂且模糊。
因此,许多神经科学家转而将大脑视为一台“预测机器”。通过预测性的处理过程,大脑利用其对世界的先验知识,对输入的感官信息做出原因推断或假设。正是这些假设,而不是感官输入本身,在我们的脑海中产生了感知。对大脑来说,输入的信息越模糊,它对先验知识的依赖就越大。
预测性处理框架的优美之处在于,它拥有相当强的能力来解释许多不同系统中的大量现象。
尽管有越来越多的神经科学证据支持了这一观点,但主要是间接证据,而且存在其他解释的可能性。如果你仔细审视人类的认知神经科学和神经成像研究,就会发现很多证据,但都是极为隐性、间接的证据。
因此,研究人员开始转向计算模型,试图理解和验证“预测性大脑”的想法。计算神经科学家已经建立了人工神经网络,其设计灵感来自生物神经元的行为,可以学习对输入信息做出预测。这些模型显示出一些不可思议的能力,似乎可以模仿真正的大脑。利用这些模型所做的实验甚至暗示,大脑必须进化成预测机器,才能满足能量的限制。

20世纪中期的认知心理学家利用这张著名的鸭兔图像来研究人类的感知能力
随着计算模型的激增,研究活体动物的神经科学家也越来越确信,大脑已经学会了推断感官输入背后的原因。大脑是如何做到这一点的?研究者尚不清楚其中的具体细节,但总体思路正变得越来越清晰。
知觉中的无意识推论
一开始,“预测性处理”似乎是一种与直觉相悖的复杂感知机制,但由于缺少其他有力的解释,科学家长期以来一直都对其青睐有加。甚至在一千年前,阿拉伯天文学家和数学家哈桑·本·海什木在他的《光学书》(Book of Optics)中就提出了该机制的一种形式,从各个方面对视觉进行了解释。19世纪60年代,德国物理学家、生理学家兼医生赫尔曼·冯·亥姆霍兹提出,大脑会推断感官输入信息的外部原因,而不是根据这些输入信息“自下而上”地构建感知。
亥姆霍兹阐述了“无意识推论”的概念,来解释双稳态(或多稳态)知觉;在这种知觉中,大脑可以用不止一种方式感知同一个图像。例如,当看到那幅广为人知的鸭兔图像时,我们的知觉就会在这两种动物图像之间来回切换。也就是说,图像可以通过两种方式来看,或是鸭子或是兔子。通过诸如此类的例子,亥姆霍兹断言,由于眼睛视网膜上形成的图像并没有改变,因此这种感知必然是一个自上而下的无意识推理过程的结果。
在20世纪,认知心理学家继续通过案例来说明感知是一个积极构建的过程,利用了自下而上的感觉和自上而下的概念输入。1980年,英国心理学家理查德·兰顿·格里高利发表了一篇颇具影响力的论文,题为《作为假设的感知》。文中认为,感知错觉本质上是大脑对感官印象成因的错误猜测。同一时期,计算机视觉科学家在没有“生成”模型作为参考的情况下,试图使用自下而上的重建方式使计算机能“看到东西”。但他们的努力遇到了挫折。
试图在没有生成模型的情况下理解数据注定会失败——人们所能做的就是对数据中的模式做出陈述。
然而,尽管研究者对“预测性处理”的接受程度有所提高,但关于它如何在大脑中实现的问题仍未解决。目前有一个颇受欢迎的模型,称为“预测编码”,认为大脑中存在信息处理的层级结构。最高层级代表最抽象、最高级的知识(比如感知到阴影中有一条蛇)。该层级通过向下发送信号来预测下一层级的神经活动;下一层级则将其实际活动与上一层级的预测进行比较。如果不匹配,该层级将产生流向上层的误差信号,以便较高层级更新其内部的表征结果。
在每一对连续的层级之间会同时发生这一过程,一直到最下面接收实际感觉输入的层级。从外界接收到的信息与预期信息之间的任何差异都会产生一个误差信号,并将其传回层级结构。最终,最高的层级会更新其假设(发现阴影中其实不是一条蛇,而是一条绳子)。
总的来说,预测编码的概念是指大脑基本上由两个神经元群构成,尤其是当这一概念被应用到大脑皮层时。一个神经元群负责对当前感知信息的最合理预测进行编码,另一个则负责发出预测中的误差信号。
1999年,计算机科学家拉杰什·拉奥和达纳·巴拉德(当时分别在索尔克生物研究所和罗切斯特大学任职)建立了一个强大的预测编码计算模型,其中具有明确用于预测和纠错的神经元。他们模拟了灵长类动物大脑视觉处理系统——由负责识别面孔和物体的层级组织区域组成——的部分通路,并表示该模型可以重现灵长类视觉系统的一些不寻常行为。
不过,在这项工作完成时,现代深层神经网络还没有出现。深层神经网络有一个输入层和一个输出层,以及夹在这两层之间的多个隐藏层。到2012年,神经科学家开始使用深层神经网络来模拟灵长类视觉皮层的腹侧流。但几乎所有这些模型都是前馈网络,信息都只从输入端流向输出端。大脑显然不是一个纯粹的前馈机器,大脑中有很多反馈信息,基本上与前馈信号一样多。
因此,神经科学家转向了另一种模型:循环神经网络(recurrent neural network,又称递归神经网络,简称RNN)。这些神经网络具有一些使其成为模拟大脑“理想基质”的特征。循环神经网络的神经元之间既有前馈又有反馈连接,而且它们有独立于输入的持续活动。在很长一段时间——基本上可以说是永远——之内产生这些动态的能力,正是这些网络随后可以被训练的原因。
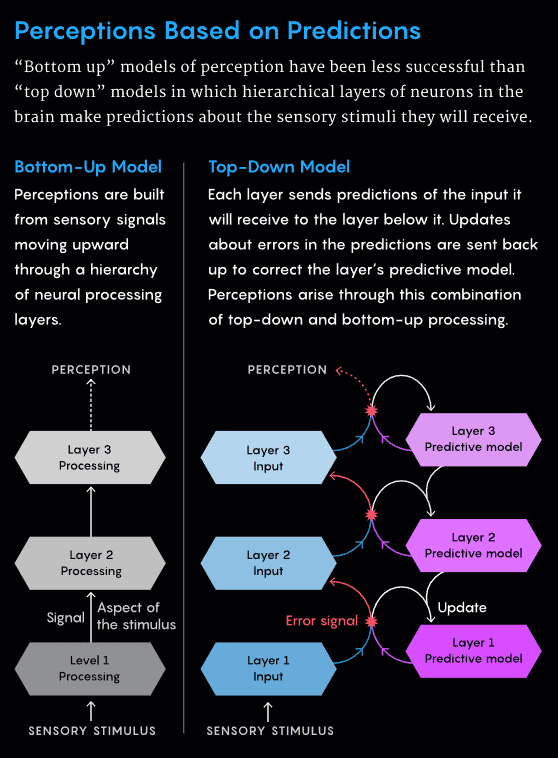
基于预测的感知。在解释大脑的感知机制时,“自下而上”的感知模型(左)并不如“自上而下”的模型,后者具有由神经元组成的层级结构,使大脑能对即将接收到的感官刺激做出预测
预测可以节能
循环神经网络引起了哈佛大学科学家的注意。2016年,研究团队展示了一个学会预测视频序列中下一帧的循环神经网络。他们将其称为“PredNet”。这个循环神经网络的设计原理与预测编码是一致的,是一个4层的层级结构,每一层都会预测来自下一层的输入信息,如果不匹配,就会向上层发送误差信号。
然后,他们用安装在车载摄像头拍摄的城市街道视频训练该网络。PredNet学会了持续预测视频序列中的下一帧,这非常酷。
他们的下一步是将PredNet与神经科学联系起来。2020年,研究团队撰文称,PredNet显示了猴子大脑对意外刺激做出反应时的行为,包括一些在简单前馈网络中难以复制的行为。
这是一项了不起的工作,无论是拉奥和巴拉德的模型,还是PredNet,都明确加入了用于预测和纠错的人工神经元,以及能做出自上而下的准确预测以抑制错误神经元的机制。但如果没有明确指定这些神经元会如何呢?研究人员想知道,所有这些加进去的构造约束是否真的有必要,或者我们是否可以通过更简单的方法把它们去掉。

哈佛大学的威廉·洛特和他的博士论文导师共同创建了PredNet,这是一个循环神经网络,在结构设计上可用于执行预测编码
首先能到想的是,神经通信是十分耗能的,毕竟大脑是身体中消耗能量最多的器官。因此,保存能量的需要可能会限制生物体中任何正在进化的神经网络行为。
研究人员决定试一下,看看在需要用尽可能少的能量完成任务的循环神经网络中,是否会出现预测编码的计算机制。他们认为,在神经网络中,人造神经元之间的连接强度(也被称为“权重”),可以作为突触传递的代理,而突触传递是生物神经元消耗大量能量的原因。如果能减少人工单元之间的权重,就意味着你能用更少的能量交流,这等同于将突触传递最小化。
然后,研究团队用多个升序并头尾相接的连续数字序列来训练RNN,包括1234567890、3456789012、6789012345等等。每个数字都以28×28像素的图像形式显示给循环神经网络。该网络学习了一个从序列中任意位置开始预测下一位数字的内部模型,但被要求以最小的单元权重来完成这一任务,类似于生物神经系统中低水平的神经活动。
在这些条件下,这一循环神经网络学会了预测序列中的下一个数字。它的一些人工神经元充当了“预测单元”,代表一个预期输入的模型。其他神经元则充当“误差单元”,当预测单元尚未学会正确预测下一个数字时,它们最为活跃;而当预测单元开始正确做出预测时,这些误差单元就被抑制住了。至关重要的是,该网络之所以能形成这一结构,是因为它必须尽量减少能量消耗。它只是学会了人们通常明确内置于系统中的那种抑制机制,系统是即开即用的,将其作为一件紧急事务来做,并达到高效节能。

当研究人员向PredNet展示视频序列时(上),这个具有预测编码结构的循环神经网络学会了预测下一帧图像(下)
因此,研究人员得出的结论是:最大限度减少能耗的神经网络最终将实现某种预测性处理。这反过来也说明了,生物大脑可能也在做着同样的事情。
这是一个非常好的例子,说明了自上而下的约束,如能耗最小化,会如何间接地导致某个特定的功能,比如预测编码。循环神经网络中特定误差单元和预测单元的出现,是否可能是网络边缘的神经元接收输入的意外结果。如果输入信息遍布整个网络,你不会发现误差单位和预测单位之间有什么区别,但你仍然会发现预测活动。
大脑行为的统一框架
尽管从这些计算研究中获得的见解看起来很有说服力,但最终,只有来自活体大脑的证据才能证明大脑中确实存在预测处理过程。布莱克·理查兹是加拿大麦吉尔大学和魁北克人工智能研究所的神经科学家兼计算机科学家,他和同事们提出了一些明确的假设,描述了大脑在学习预测意外事件时应该“看到”什么。
为了验证这些假设,他们求助于美国西雅图艾伦脑科学研究所的研究人员,后者在小鼠身上进行了一些实验,同时监测它们大脑中的神经活动。特别让研究者感兴趣的是,大脑新皮层中的某些锥体神经元,被认为在解剖学上很适合进行预测处理。它们既可以接收来自附近神经元的自下而上的感觉信号(通过向它们的细胞体输入信号),也可以接收来自更遥远神经元的自上而下的预测信号(通过它们的顶树突)。

大脑中的锥体神经元似乎在解剖学上很适合进行预测性处理,因为它们可以分别整合来自邻近神经元的“自下而上”信号,以及来自较远神经元的“自上而下”信号
研究人员向小鼠展示了许多加博尔光斑(由明暗条纹组成)序列,每个序列中的4个光斑都有大致相同的朝向。小鼠逐渐适应了这些序列,然后,研究人员插入了一个意外事件:第4个加博尔光斑随机旋转到另一个方向。一开始,这些小鼠显得很惊讶,但随着时间的推移,它们也开始期待惊喜。实验期间,研究人员一直在观察小鼠大脑的活动。
研究人员发现,许多神经元对预期和意外刺激的反应是不同的。至关重要的是,在实验的第一天,这种反差在局部的、自下而上的信号中非常强烈;但在第二天和第三天,反差就减弱了。这表明,在预测性处理的背景下,随着刺激变得不那么令人惊讶,新形成的自上而下的预期开始抑制对传入感觉信息的反应。
与此同时,顶树突的情况恰好相反:它们对意外刺激的反应差异随着时间的推移而增强。神经回路似乎正在学习更好地表征这些意外事件的性质,以便更好地预测下一次事件。这项研究进一步支持了这样一种观点,即新大脑皮层正在进行着预测学习或预测编码。
有时,对神经元活动或动物行为的个别观察结果也可以用其他大脑模型来解释。例如,神经元对相同输入的反应减弱,可能只是一个适应过程,而不必解释为误差单元受到抑制。不过,这最后可能会导致你要对许多不同现象一一做出解释。相比之下,预测性处理提供了一个统一的框架,可以一次性解释许多现象,因此是一个很有吸引力的大脑工作理论。