
在近日举办的hybrid virtual/in-person SC21会议上,来自之江实验室、清华及无锡超算中心的14人组成的中国研究团队斩获今年超算领域最高奖项戈登贝尔奖——利用新的百亿亿级双威系统模拟量子电路。
据了解,戈登贝尔奖(GORDON BELL PRIZE),设立于1987年,是国际上高性能计算应用领域的最高学术奖项,被称为“超算领域的诺贝尔奖”,主要颁发给高性能应用领域最杰出成就,由ACM每年评选和颁发,具有较大的国际影响力。获奖者将会获得由HPC先驱Gordon Bell提供1万美元的奖金。
ACM 旨在“跟踪并行计算随时间的进展,特别强调将高性能计算应用于科学、工程和大规模数据分析领域的创新奖励。”。今年的戈登贝尔奖决赛有6个项目,涉及量子计算、分子动力学、光谱学及核聚变等多个领域。
附:2021年ACM戈登贝尔奖获得者
缩小“量子霸权”鸿沟:使用新型双威超级计算机实现随机量子电路模拟
来自于浙江实验室、清华大学、无锡国家超级计算中心和上海量子科学研究中心的14名研究人员利用大规模新双威百亿亿次系统对量子进行了开创性的电路模拟。
“随着Google在2019 年发表的“量子霸权”宣言,声称Sycamore超导量子计算机比Summit 快十亿倍以上,量子时代的黎明开始以更积极的方式展开,”研究人员写道,“IBM研究团队后来回应认为,他们可以在经典的Summit 超级计算机上完成模拟……是在几天之内,而不是1万 年。”
该团队使用随机量子电路的量子态采样作为解决这一备受争议的量子优势的示例问题。研究人员的随机量子电路模拟器,结合Sunway exascale系统的强大功能,模拟了一个 10×10(量子位)×(1+40+1)(深度) 的电路,持续性能达到惊人的120亿亿次单精确计算或440亿亿次混合精度计算,研究人员称这是“量子电路经典模拟的新里程碑”。他们将模拟采样时间从之前估计的1万年减少到304 秒。
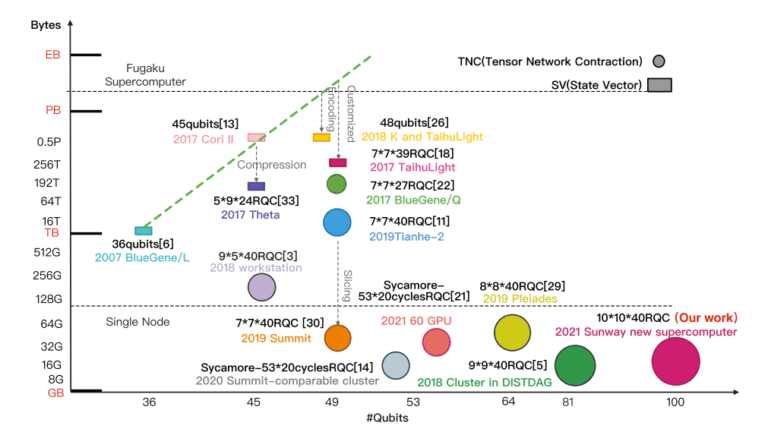
*上图由研究人员提供,主要经典随机量子电路模拟总结。X轴表示量子比特的数量;Y轴表示所需的相应内存空间;圆圈和矩形的大小表示电路的复杂性/深度。
ACM戈登贝尔奖提名:
在量子模拟研究获得奖项的同时,其他五项被提名代表了对世界上一些最紧迫的研究应用的最深入研究。
·Anton 3:午餐前的20微秒分子动力学模拟
多达 67 名研究人员参与了这项研究,最终开发出了由D.E. Shaw设计和建造的专用Anton 3分子动力学超级计算机。研究人员报告说,Anton 3能够以每天100微秒的速度在512个节点上模拟一百万个原子,每模拟1微秒的能量比任何其他机器都要少一个数量级。为实现这一壮举,他们实施了一系列架构和算法改进,包括一个新的自定义网络、不同精度的专门的成对交互,以及一个名为“曼哈顿方法”、用于解决非绑定交互的新方法。
·“富岳(Fugaku)”超级计算机上的400万亿网格Vlasov模拟:宇宙遗迹中中微子在六维相空间中的大规模分布
研究人员通过对宇宙遗迹中微子的大规模模拟,结合冷暗物质的 N 体模拟。他们最大的模拟跨越了400万亿个网格和3300亿天体的计算,“精准地再现了宇宙中中微子的非线性动力学。”在“富岳”上进行优化后,研究人员扩展了147,456个节点,显示出高达96%的弱缩放和高达93%的强缩放。
·托卡马克等离子体中111.3万亿个粒子和257亿个网格的的保辛结构粒子全体积模拟
托卡马克,一种利用磁约束来实现受控核聚变的环性容器。来自中国的十几名研究人员使用新的神威(Sunway)系统模拟了托卡马克的全体积约束环面等离子体。这些模拟达到了111.3万亿个粒子和257亿个网格,实现了超过201 petaflops双精度的持续性能,最快的迭代步数达到298.2。
·中国领先高性能计算系统的极尺度 从头计算(Ab Initio)量子拉曼光谱模拟
这项研究也利用了新的神威百亿亿次系统,将拉曼光谱——一种结构指纹——推向了新的极限。这十几名来自中国的研究人员解释称,“拉曼光谱提供了化学和成分信息,可以作为各种材料的结构指纹。因此,包括量子微扰分析和基态计算在内的拉曼光谱的模拟都具有重要意义。”生物材料的拉曼光谱的全量子力学模拟已被证明特别困难,在这里,研究人员进行了“快速、准确、大规模并行的真实生物系统拉曼光谱全从头计算模拟”,多达3006个原子,双精度达到468.5 petaflops ,混合半精度达到813.7 petaflops,这表明“QM方法在生物系统中的新应用潜力”。
·碳在极端条件和实验时间和长度尺度下的十亿原子分子动力学模拟
这些研究人员在极端压力和极端温度下观察到了碳“长期寻找”的BC8相。为此,他们在美国领导力峰会系统上运行,在24 时内指挥4650个节点,并展示了“SNAP [分子动力学] 前所未有的扩展性和无与伦比的现实世界性能”。代表模拟物理时间纳秒,模拟实现了超过97%的并行效率和50 petaflops的峰值计算能力,用于跨越Summit近 28,000 个GPU上进行了200亿原子分子动力学模拟。研究人员称,这一纪录为620万个原子步/节点秒,是之前纪录的工作的22.9倍。