
据The Verge报道,根据一项新分析,用于训练检测皮肤问题的算法的公共皮肤图像数据集并不包括足够的肤色信息。而在有肤色信息的数据集中,只有很少的图像是深色皮肤的--因此使用这些数据集建立的算法对非白人来说可能不那么准确。
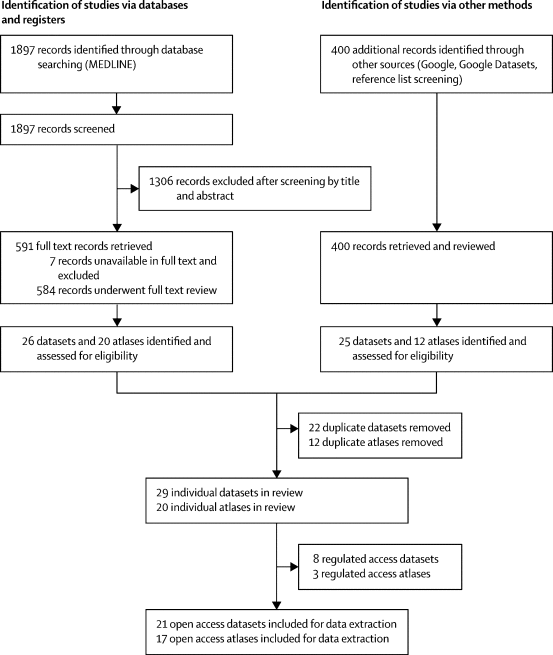
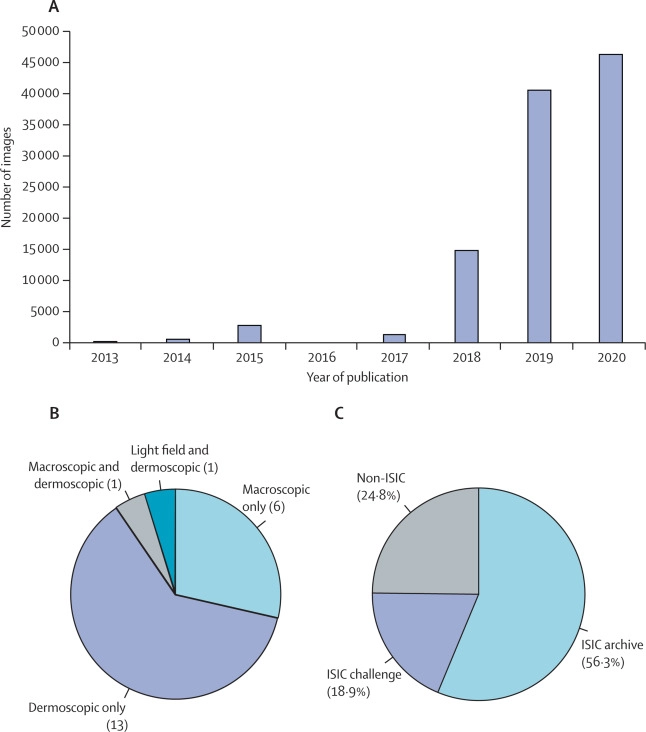
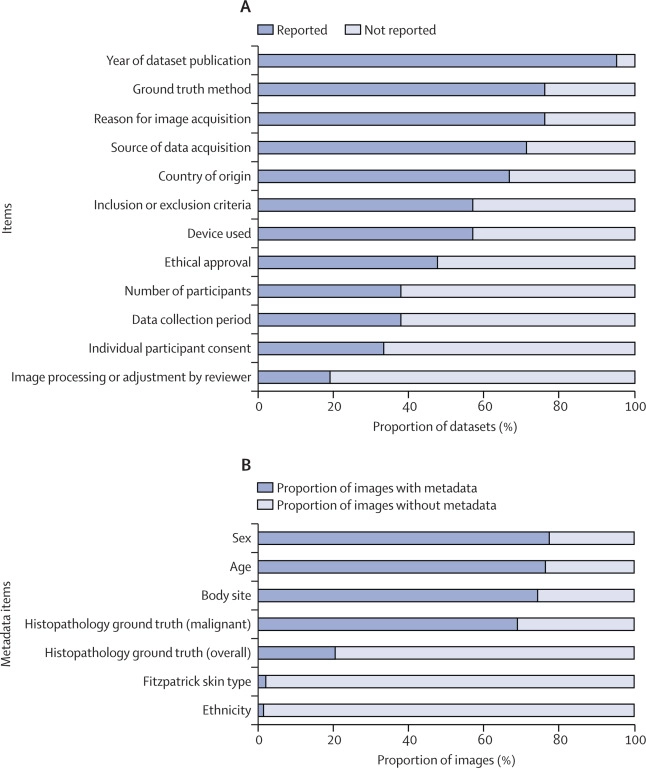
周二发表在《柳叶刀-数字医疗》上的这项研究检查了21个可自由访问的皮肤状况图像数据集。这些数据集共包含10万多张图片。这些图像中只有1400多张附有关于患者种族的信息,只有2236张有关于肤色的信息。这种数据的缺乏限制了研究人员在图像上训练的算法中发现偏差的能力。而这种算法很可能是有偏见的。在有肤色信息的图像中,只有11张是来自菲茨帕特里克皮肤量表中最深的两个类别的病人,该量表对肤色进行分类。没有来自非洲、非洲-加勒比或南亚背景的病人的图像。
这些结论与9月份发表的一项研究相似,该研究还发现,用于训练皮肤学算法的大多数数据集都没有关于种族或肤色的信息。该研究检查了70项开发或测试算法的研究背后的数据,发现只有7项描述了所用图像中的皮肤类型。
斯坦福大学皮肤病学临床学者、9月份发表的一篇论文的作者Roxana Daneshjou说:“我们从少数报告出肤色分布的论文中看到的是,那些论文确实显示出深肤色的代表不足。”她的论文分析了许多与《柳叶刀》新研究相同的数据集,得出了类似的结论。
当数据集中的图像是公开的,研究人员可以去查看哪些肤色似乎是存在的。但这可能很困难,因为照片可能与现实生活中的肤色不完全一致。“最理想的情况是,在临床就诊时注意到肤色,”Daneshjou说。然后,该患者的皮肤问题的图像可以在进入数据库之前被贴上标签。
如果图像上没有标签,研究人员就不能检查算法,看看它们是否使用了有足够多不同皮肤类型的人的例子的数据集。
仔细检查这些图像集很重要,因为它们经常被用来建立算法,帮助医生诊断病人的皮肤状况,其中一些--如皮肤癌--如果不及早发现就会更危险。如果算法只在浅色皮肤上进行了训练或测试,它们对其他人来说就不会那么准确。"研究表明,只对浅色皮肤类型的人的图像进行训练的程序对深色皮肤的人来说可能不那么准确,反之亦然,"新论文的共同作者、牛津大学的一名研究员David Wen说。
新的图像总是可以被添加到公共数据集中,研究人员希望看到更多关于深色皮肤状况的例子。而提高数据集的透明度和清晰度,将有助于研究人员跟踪更多样化的图像集的进展,这可能导致更公平的AI工具。Daneshjou说:“我希望看到更多的开放数据和更多精心标记的数据。”