
在科幻电影《降临》当中,一群外星人乘着12艘飞船造访地球。人类无法准确把握其意图,而由语言学家班克斯领导的一支跨学科专家队伍,被赋予了解码“七肢桶”(Heptapod) 外星人语言,与其实现对话,理解其意图的重要使命。
所幸的是,班克斯率领的美国团队掌握了外星人的符号语言,实现了和外星人的对话,并且成功通过避免了因为预料不全和翻译误差而导致人类和外星人,甚至人类不同国家之间的全面战争。
这部电影改编自美国作家姜峯楠的星云奖获奖作品《你一生的故事》。虽然人类希望交流的对象是外星生物,这部作品和一些古埃及、古罗马传说,以及安徒生童话、爱丽丝梦游仙境等文学作品,仍然可以属于同一个母题:跨物种交流。
而在真实世界当中,一群来自世界各地知名院校的跨学科研究者,也在做着和电影当中类似的事情。他们的对象,不是外星人,而是我们地球的海洋中,一个十分令人着迷,极有可能具有智慧和情感的物种:抹香鲸。
这些研究者,希望翻译鲸鱼的语言,实现人鲸对话。
Project CETI:借助ML的力量,实现跨物种翻译
哈佛大学拉德克里夫学院 (HRI)是该校专门为汇集来自全世界的优秀专家进行跨学科研究而运作的机构。2017年,一群海洋生物学家、信号学家和计算机科学家聚在这里,谈天说地。
来自加州大学伯克利分校的计算机和加密学教授Shafi Goldwasser走在楼道里,路过海洋生物学家David Gruber的办公室时,听到了一种奇怪但又熟悉的滴答声(Clicks)。
其实,Goldwasser听到的是抹香鲸发出的声音。
抹香鲸是一种听觉极其敏感的海洋生物。其所有滴答声中,大约有70%用于回声定位和捕猎等。海洋生物学家经过大量的研究,认为其余大约20-25%的滴答声,极有可能是用于鲸鱼之间的交互沟通的。
——这部分的滴答声,被称为“密码曲” 。

而Goldwasser对这些声音感到熟悉,是因为它们很自己的信号学专业很接近,有点类似摩尔斯电码,也有点像故障的电路板元器件会发出的声音。
这位2012年图灵奖得主发现自己的兴趣被莫名调动起来了。她当时随口一提,表示:“或许我们应该搞一个项目,把这些声音翻译出来让人能听懂。”
当时她也没想到,这个非常随机的想法,居然在三年后,促成了一个雄心壮志的的跨学科前沿研究项目:Project CETI。
Project CETI 全称Cetacean Translation Initiative(鲸类翻译计划),由来自纽约城市大学、UC伯克利、MIT、哈佛、Google研究院和《国家地理》等知名学府、研究和环保机构的专家共同组成。
这些专家涵盖了AI、机器人、信号学、语言学、水下声学、海洋生物学等多个学科。鲸类翻译计划脱胎于哈佛拉德克里夫学院,也继承了该校的跨学科研究思路。成员们认为,只靠一两种技术是无法实现他们的目标的。如果要对鲸类语言获得更加全面和深入的了解,必须采用这种跨学科研究的研究思路,让不同专业的专业知识在项目里融会贯通。
这个计划,获得了知名科普机构 TED大会旗下The Audacious Project 的资助支持,并且按照501c3非营利机构的模式,在美国和多米尼加运作。
在多米尼加海岸以外的一块大约20平方公里的海域上,海洋生物学家已经对当地的抹香鲸群落进行了十多年的观察,记录了大量的数据。而这些专家也带着数据加盟了鲸类翻译计划,让团队实力显著增强。今后,项目团队将进一步扩大抹香鲸的观察研究,以及密码曲数据的记录。
整个项目的工作内容和阶段目标,主要如下:
1)从多米尼加海域开始,对当地的抹香鲸种群进行大规模的长期追踪研究
2)大规模收集适合机器学习方式处理的声音数据和其他元数据(如鲸鱼的位置、动作、姿态等)
3)了解鲸鱼之间的互动方式,特别是声学沟通的方式
4)建立声音表达和行为模式之间的关联
5)更多了解幼鲸的沟通能力是如何发展的
6)初步目标:找到更多语言结构存在的证据,例如类似于语法的高级别沟通方式
7)训练一个“鲸语聊天机器人”,尝试对抹香鲸的表达做出回应,并进一步观察是否能够发生有意义的交流
8)学习更多的对话数据中,增加对抹香鲸语言的句法、语义等要素的理解
8)超长期的终极目标:实现人鲸对话,对族群和物种有更多的了解。
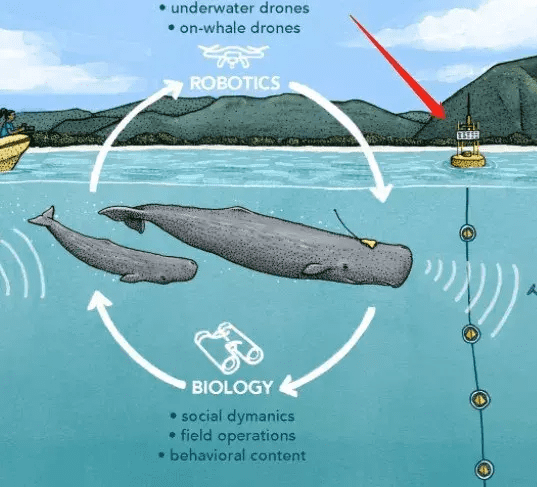
图片来源:Project CETI
Michael Bronstein是鲸类翻译计划的机器学习负责人。他自嘲这辈子到现在还没见过真的鲸鱼。尽管如此,当Goldwasser 和 Gruber找他来聊想法的时候,他对数据的敏感程度,以及对用于NLP(自然语言处理)的无监督深度学习模型的了解,还是令他立刻意识到这个项目是绝对可以做的。虽然注定很艰难,但如果真的做出来的话, 对于人类文明的进步、环境保护的推动,带来的积极影响将会是难以估量的。
在一场硅星人参加的线上研讨会中,Bronstein列举了一组重要的数据:
假设一片海域有50-400只抹香鲸(数量浮动很大,因为它们也会迁徙),每年能够录得的Click数量可能在4到40亿次之间——从数据量的规模来看,这个项目做下去的话,是完全可以和一些深度学习语言模型(比如 BERT)相提并论的。
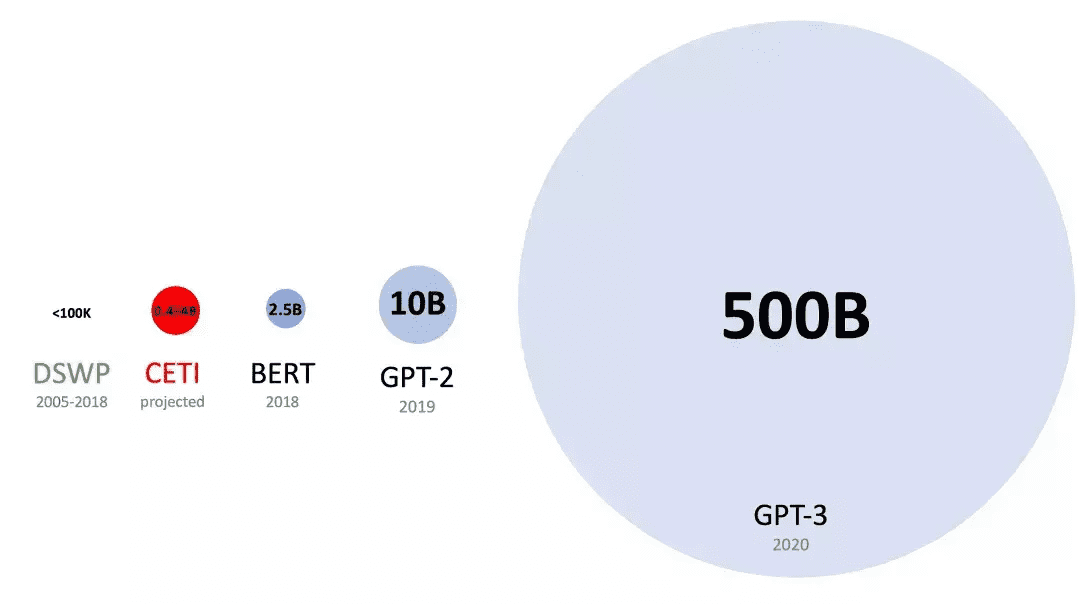
Project CETI和一些主流语言模型的数据量对比 图片来源:Michael Bronstein
Bronstein透露,自己到现在大体上对于鲸鱼还是“一无所知”。但是,他和团队当中负责机器学习部分的小伙伴们,已经对之前录下来的数十万个独立的抹香鲸密码曲数据单元进行了分析。
不懂鲸鱼的人也来做鲸鱼研究?如果在一般的学术环境下,这种行为早就要被人笑掉大牙了。然而其实这样完全没问题,因为这跟机器学习(准确来说是无监督深度学习)的逻辑是完全一样的。
以面向文本生成的深度神经网络模型为例。其实神经网络根本不懂它说的语言,也不知道自己输出的句子到底什么意思。尽管如此,这些模型在语言生成上面仍然非常出色,其实是因为统计学做的好。它学习了大量的语料数据之后,其实已经从统计的角度掌握了句子的构成结构、语法的规律等。
甚至在翻译任务中,新的无监督神经网络,可以在不需要平行语料库(也即同一内容两种语言对照的语料)的前提下,仅通过大量学习互联网上的内容,算法就能自己掌握翻译的能力。

巨大的科学赌注
Bronstein坦诚地表示,鲸类翻译计划的基础,其实是一个特别大胆、高风险的科学假设。也即:抹香鲸的“密码曲”是足以构成一种语言,或者至少是一种接近于语言的声学表意方式。
这里需要明确的是:不是所有的发声都是语言。比如猫狗的叫声就不构成语言;学舌的鹦鹉就算模仿人类说出了一句话,它多半也只是想要获取主人的注意,而不是真的理解学出来那句话的含义,同样不属于语言表达。
鲸类翻译计划的假设,基本就是:
1)抹香鲸发出的滴答声组成的“密码曲”当中,是存在单词或词组的。一些特定结构的滴答声,在整个抹香鲸物种当中(或者至少在一个族群当中)是具有固定的含义的——也即语义的存在。
2)这些“密码曲”当中有语法的存在,哪怕是最简单的语法。比如山雀在特定威胁发生的时候会连续发出两种声音,作为对其它同类的警告,或者抹香鲸在用密码曲“自报家门”的时候可能会采用某种特定的报告顺序,这都是简单语法可能存在的例证。
3)抹香鲸的密码曲不是天生就会,而是在社会化的族群生活中,通过不断观察学习其他同类而获得的。只有后天习得的语音表达能力,才有可能构成语言。
以上这几点假设,目前都没有足够的、科学上绝对靠得住的证据和学术研究能够证实。不过,目前团队已经积累了一些数据资料,似乎预示着他们的方向是正确的,假设是合理的。
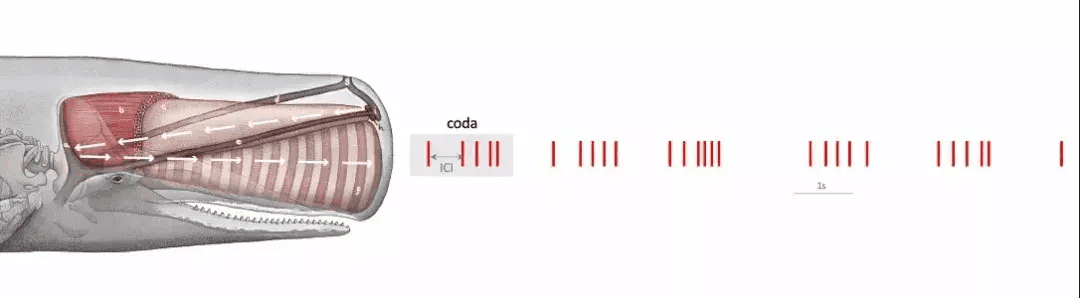
其中一个证据:抹香鲸的一段单独的密码曲一般由5个间隔各不相同的滴答声组成。不同的鲸鱼会使用不同的间隔方式。而通过大量的观察和研究,目前海洋生物学家的共识是,抹香鲸的密码曲当中编码了其所属的族群、家庭,以及其个体身份的信息。甚至还有研究发现,一些抹香鲸在不同的环境、处境下,发出的密码曲的频谱和振幅都不一样,就好像在说“方言”一样。
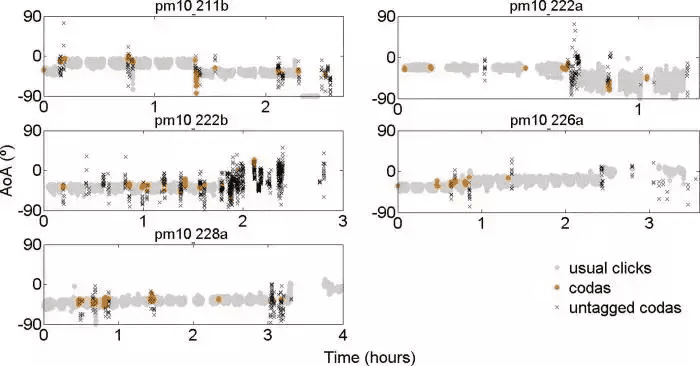
抹香鲸的密码曲 (codas) 示意 图片来源:Michael Bronstein
”对于其它物种是否有类似人类的语言,以及我们是否可以理解它们的语言……如果这个方向有什么动物值得研究,那肯定是抹香鲸了。”Bronstein 表示。
抹香鲸是哺乳动物,人类也是哺乳动物
抹香鲸有发育良好的大脑——全宇宙最大的大脑,是人类的6倍
抹香鲸以家庭为生活单位,可以说有着和人类类似的家庭文化
抹香鲸有着复杂的沟通系统,并且很有可能具有对话的能力。Gruber 有一次在多米尼加曾经旁听了两只位置静止的抹香鲸之间,用密码曲断断续续的“对话”,长达40分钟,几乎每一句都不重样,并且伴各种动作
“既然我们知道抹香鲸有着浓厚的家庭意识,万一这是两只母鲸在拉家常、分享育儿心得呢?”
如果抹香鲸确实有语言的话,那么用 NLP 深度学习的思路,套用到翻译密码曲的任务,就非常合适了。你可以这样理解:深度学习不懂英语和中文,但是通过大量学习语料就可以获得中英互译的能力。
那么就算我们人类无法理解鲸语,但深度学习或许能够从大量鲸语语料中找到文本的构成规律。如果这能实现的话,在人类语言和鲸语之间实现互译,甚至人鲸对话似乎并不是一件遥不可及的事。
Bronstein说,这是他学术生涯目前为止参与过的最疯狂的一个项目,并且希望能够说服人们,他们的设想并不是一个梦,而是真的有可能实现海洋生物学和生态环境保护方面的一个重大突破。
“等我们能和鲸鱼对话的那一天,万一它们想要告诉人类,‘不要再捕杀我们了,不要再破坏环境了’呢?”

Michael Bronstein在2015年国际图像处理大会上演讲
数据收集和项目进展
这个项目听起来特别的宏大,但说句实话,现在整个研究的进度并没有我们想象的那么深入,还没有什么特别值得宣告的进展。目前,团队仍处在数据获取的阶段。想要高效率地收集高质量的抹香鲸声音数据,简直太难了。
在机器学习领域,为了训练神经网络,需要大规模构建标注数据集,而缺乏优质标注数据、标注能力不足,一度制约了技术发展。
而在鲸类翻译计划这里,团队面临同样的问题:要获取数据,就得跟踪抹香鲸的位置,而这又是一种听力极好,对声音/噪音极其敏感的动物,想要跟踪他们并且“偷听”,非常费时费力。其次,因为人类的航海活动,最适合抹香鲸生活的海域噪音也非常大,也会影响数据收集的质量。
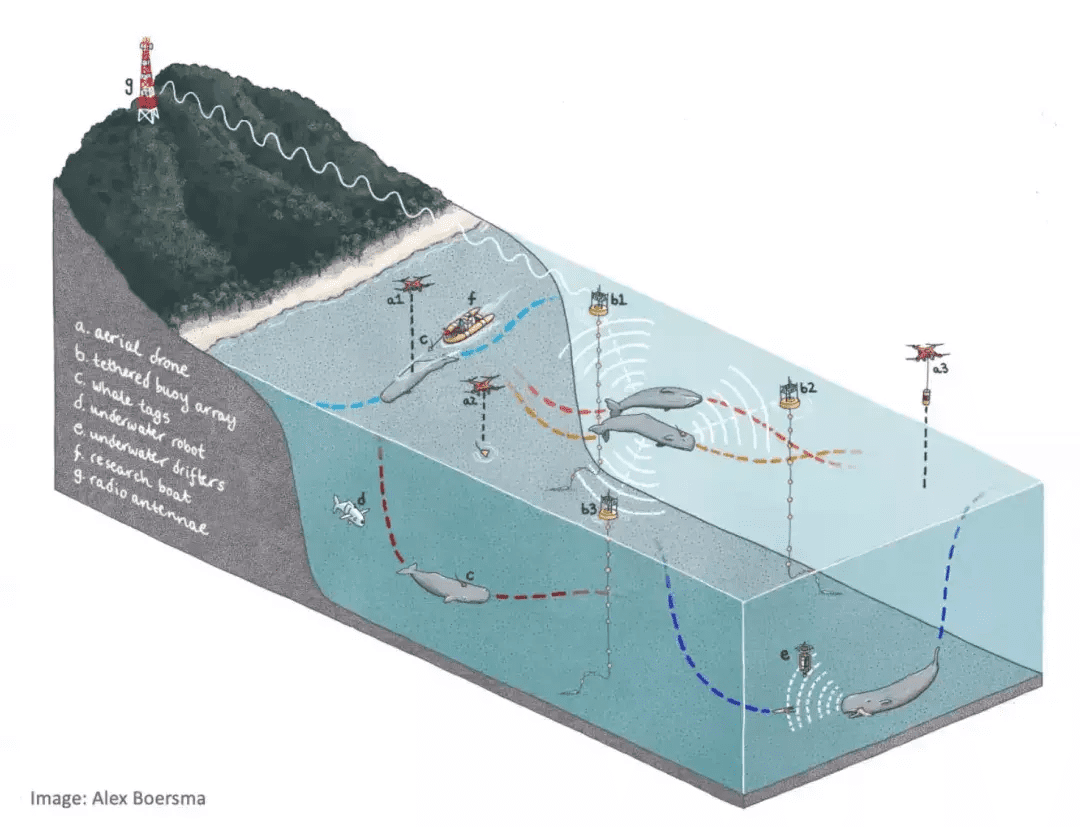
为了更好地收集数据,鲸类翻译计划专门吸纳了机器人和信号学方面的专家。团队计划开发几种不同的数据收集装置,实现“全方位全天候覆盖”:
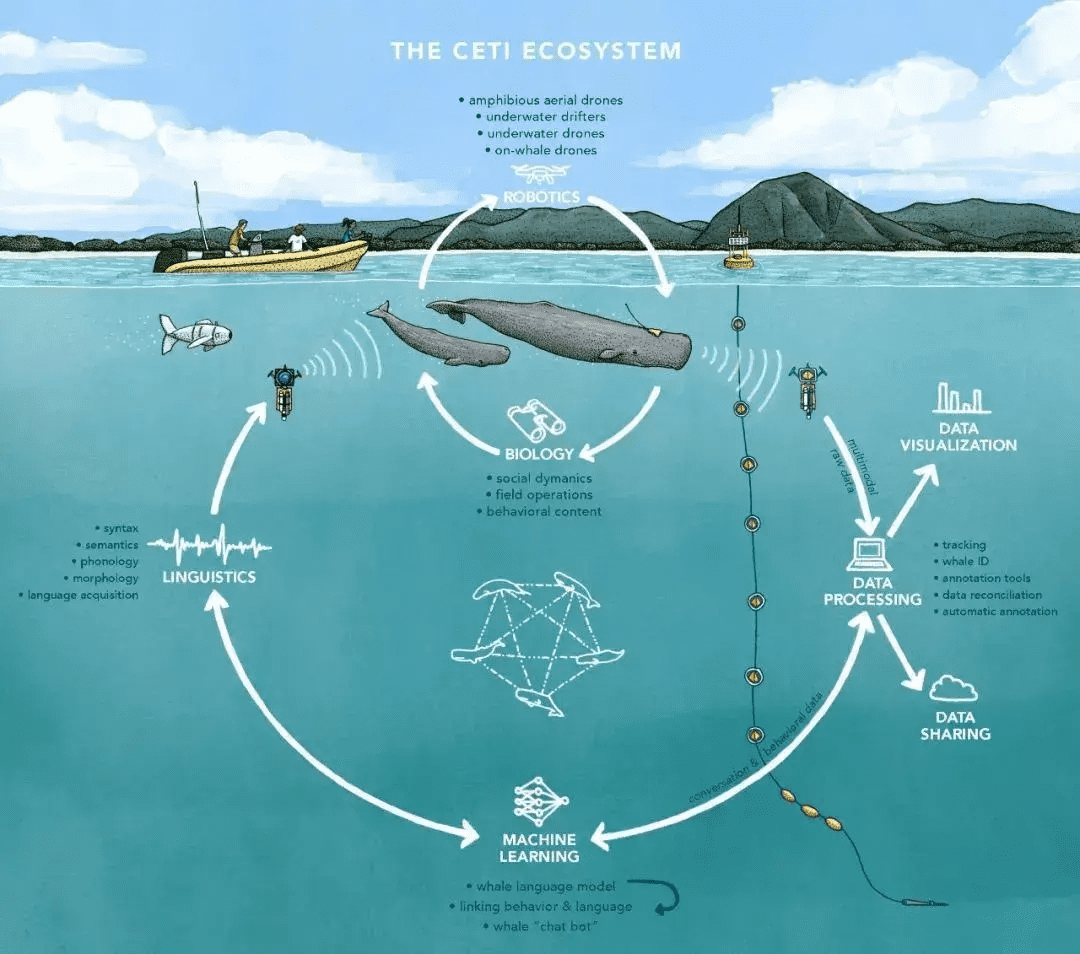
第一种是常规的水下麦克风,通过浮标的方式安放在海域固定位置和固定深度。
这种传感器,和军事场景侦测潜水艇的技术差不多,好处是成本较低,能够全天候收集大量的背景声音数据(如下图所示)。
这种固定麦克风的劣势在于容易受到噪音的影响,且追踪特定鲸鱼的能力较差。所以就需要其他的传感器来补充。
第二种传感器叫做“Tag”(标签),也就是吸附在每一条抹香鲸身上,针对性地只收集这一只(以及附近和它交流的其他鲸鱼)的声音数据。这些标签不仅收录声音,还可以同时记录其更多类型的行为数据位置、深度、速度、动作、姿态等等:

第三种就是水下/空中无人机,具有导航、追踪、视频音频记录功能用来覆盖前集中数据收集方式的盲区。在未来,一部分水下无人机还可以改造成“鲸语聊天机器人”。
至于鲸类翻译计划目前的进展:这个项目是去年正式组建的,今年前不久刚获得更多外部机构的资助和学术支持。Bronstein告诉硅星人,团队预计将在明年陆续完成各种数据收集装置的开发,并开始收集更多数据。
鲸类翻译计划的团队成员们一厢情愿地认为,自己的研究方向是正确的,一方面是考虑到之前有针对海豚等其他海洋生物的类似项目取得了成果,另一方面也因为前文提到的,基于机器学习(也即统计学)的研究方法,无论如何都是能用的。
在学术界中,支持和质疑该项目的声音此起彼伏。但不管怎么样,由于研究对象和研究方式的限制,鲸类翻译计划无法在短期(一两年内)取得关键突破的。这注定是一个超长期的项目——无论结果如何,团队成员的猜想最终是否应验,这个项目都将帮助人类,增进对抹香鲸以及更多智慧生物沟通方式的了解。
跨物种沟通的“罗塞塔石碑”
两个完全不同的物种想要进行平等的沟通是非常困难的。幸运的是,人类对于语言这门巨大的学问已经掌握了非常多科学的方法。
文章一开始提到的《降临》电影,就是一个非常好的例子。片中,人类一开始错以为七肢桶发出的声音是他们在说话,后来主角语言学家班克斯成功“激活”了外星人,让他们用真正的文字语言(圆环状的符号)进行沟通。有了文字,班克斯的团队进一步构建出了共享词汇,进而双方之间的沟通效率极大提升。
在古埃及历史文化中,“罗塞塔石碑”(Rosetta Stone) 是一个极其重要的存在。这是一块刻有托勒密五世诏书的石碑,同一段内容用了埃及草书、古希腊文,以及失传了上千年的古埃及象形文,三语对照的写法。
毫无疑问,这块石碑,就是这三种语言最古老的“词典”,或者用今天机器学习的术语来说,这是最古老的平行语料库。通过它,考古学家解读出了失传上千年的古埃及象形文的意义、结构,甚至还发现象形文字也具有表音的作用。罗塞塔石碑也被公认为后世了解古埃及语言和文化的关键基础。

而在今天机器学习方式,特别是无监督深度学习的方法,为人类处理语言任务,甚至拓展语言研究的边界,开启了一种全新的思路。
在翻译这一经典任务上,机器不需要理解语言,而是仅靠单一语言的语料,即可掌握该语言的句法、语法等关键要素。
Bronstein表示,在神经网络处理翻译任务的时候,研究者有一个重要的发现:英语和意大利语,在词、句、语法等各方面差异巨大的两种语言,在表达同一句话时,在神经网络内部的Word Embedding模式惊人的近似。
这一情况的存在,让鲸类翻译计划的成员们对于未来非常期待。逻辑简单形容一下其实是这样的:
这两种语言都是人类说的↓
人类是智力高度发达的哺乳动物↓
抹香鲸也是智力高度发达的哺乳动物↓
那么,人类的语言和抹香鲸的“语言”,是否至少存在那么一点点相似之处,可以用机器学习/语言/统计学的思路,来打开一个突破口?
这也是鲸类翻译项目的存在之外的另一个启发:在机器学习技术飞跃的时代,“罗塞塔石碑”或许不再是词汇表,而是跨物种之间共通的,只有依靠先进科学才能够识别出的,隐性的规律。
也许经过多年的研究,人鲸对话将成为现实。