
来自匈牙利罗兰大学动物行动学系的研究人员结合EEG和fMRI的一项新研究发现,狗使用与人类相似的计算和大脑区域从连续语音中提取单词。这是首次证明非人类哺乳动物有能力使用复杂的统计数据来学习单词的界限。
人类婴儿可以在学会这些词的含义之前就发现语音流中的新词。为了分辨一个词在哪里结束,另一个词在哪里开始,婴儿进行复杂的计算来跟踪音节模式:通常一起出现的音节可能是单词,而那些没有出现的可能不是。匈牙利研究人员进行的一项新的大脑成像研究发现,狗也可能识别语音中的这种复杂规律性。
“跟踪模式并不是人类独有的:许多动物从周围世界的这种规律性中学习,这被称为统计学习。语音的特殊之处在于其有效处理需要复杂的计算。”
要从连续的语音中学习新词,仅仅计算某些音节在一起出现的频率是不够的。计算这些音节在一起出现的可能性要有效得多。
“这正是人类,甚至是8个月大的婴儿,解决单词分割这一看似困难的任务的方式:他们计算一个音节紧跟另一个音节的概率的复杂统计数据,”该研究的主要作者之一、罗兰大学动物行动学系交流神经伦理学实验室的博士后研究员Marianna Boros解释道。

“直到现在,我们还不知道是否有其他哺乳动物也能使用如此复杂的计算来从语音中提取单词。我们决定测试家犬的大脑从语音中进行统计学习的能力。狗是最早被驯化的动物物种,可能也是我们最常说话的动物。尽管如此,我们对它们的单词学习能力所依据的神经过程知之甚少。”
“为了找出狗在听语音时计算什么样的统计数据,首先我们用脑电图测量了它们的脑电活动,”另一位主要作者、同一研究小组的博士后研究员Lilla Magyari说,他为在清醒的、未经训练的、合作的狗身上进行非侵入性电生理学奠定了方法学基础。
“有趣的是,我们看到狗的脑电波与罕见的词汇相比有差异。但更令人惊讶的是,我们还看到总是一起出现的音节与只是偶尔出现的音节的脑电波差异,即使总频率是相同的。因此,事实证明,狗不仅跟踪简单的统计数据(一个词出现的次数),而且跟踪复杂的统计数据(一个词的音节一起出现的概率)。这在其他非人类的哺乳动物中从未见过。这正是人类婴儿用来从连续的语音中提取单词的那种复杂的统计数据。”
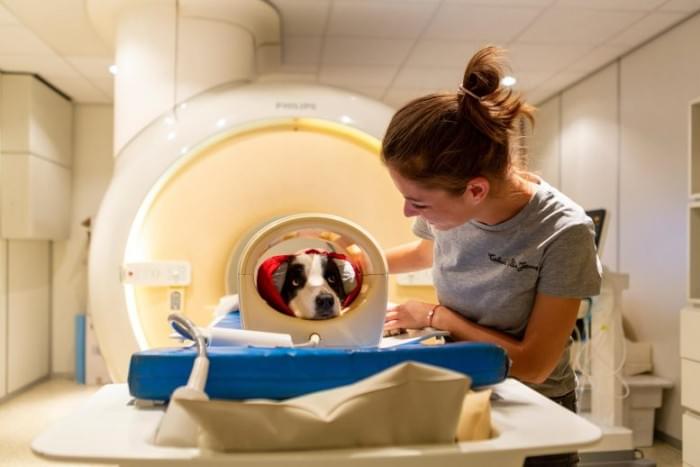
为了探索狗的这种复杂计算能力背后的负责任的大脑区域与人类的大脑区域有多大的相似性,研究人员还使用功能磁共振成像对狗进行了测试。这项测试也是在清醒的、合作的、非约束的动物身上进行的。对于fMRI,狗之前被训练成在测量时一动不动地躺着。
“我们知道,在人类中,一般学习相关的和语言相关的大脑区域都参与了这一过程。而我们在狗身上也发现了同样的双重性,”Boros解释说。“一个通用的和一个专业的大脑区域似乎都参与了从语音中进行统计学习,但两者的激活模式是不同的。一般性脑区,即所谓的基底神经节,对随机语音流(使用音节统计学无法发现任何单词)的反应强于对结构化语音流(仅通过计算音节统计学就能轻易发现单词)的反应。专业的大脑区域,即所谓的听觉皮层,在人类的语音统计学习中起着关键作用,显示出不同的模式:在这里,我们看到大脑活动随着时间的推移对结构化的语音流有所增加,但对随机的语音流则没有。我们认为,这种活动的增加是单词学习在听觉皮层上留下的痕迹。”
“我们现在开始了解到,一些已知对人类语言习得有帮助的计算和神经过程可能毕竟不是人类所独有的,”交流神经伦理学实验室的主要研究人员Attila Andics说。
“但我们仍然不知道这些人类模拟大脑的词汇学习机制是如何在狗身上出现的。它们是否反映了在语言丰富的环境中生活而形成的技能,或在数千年的驯化过程中形成的技能,或者它们代表了一种古老的哺乳动物的能力?我们看到,通过研究狗的语言处理,甚至是具有不同交流能力的更好的狗品种和其他与人类生活接近的物种,我们可以追溯人类对语言感知的专业化的起源。”