
近几年,机器学习已经在放射学、病理学和皮肤病学等各个应用领域取得了长足进展。此前,Google 分享了人工智能皮肤病学辅助工具的预览。近期,Google发布两项新研究,有望帮助机器学习在皮肤病检测方面取得新的进步。
自监督学习推进医学图像分类
近年来,人们对将深度学习应用于医学成像任务越来越感兴趣,在放射学、病理学和皮肤病学等各种应用领域取得了令人振奋的进展。
尽管大家兴致盎然,但开发医学成像模型仍然一定的具有挑战性,因为由于注释医学图像需要比较大的工作量,高质量的标记数据通常很少。
鉴于此,迁移学习(指解决一个问题时获得的知识并将其应用于不同但相关的问题)是构建医学成像模型的常用模式。
使用这种方法,首先在大型标记数据集(如ImageNet)上使用监督学习(让机器学习一个函数)对模型进行预训练,然后在域内医疗数据上对学习的通用结果进行微调。
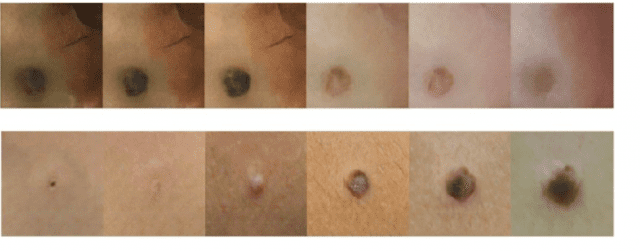
随着输入皮肤颜色的变化,病变的外观也会发生变化,以匹配不同皮肤类型的病变。
自监督预训练比监督预训练更具可扩展性,因为不需要类标签注释,希望在未来将有助于在医学图像分析中推广自监督方法的使用,从而产生适用于现实世界中大规模临床部署高效且稳健的模型。
描述不足给机器学习带来的挑战
随着机器学习模型使用的领域愈发广泛,机器学习常常会出现一些“意想不到”的行为。例如,在计算机视觉模型中,对不相关的特性表现出惊人的敏感度。
或者在“精心策划”的ML模型训练及解决与应用领域在结构上不匹配的预测问题当中,即使处理了一些已知问题,模型行为在部署中仍可能表现出差异性,甚至在训练运行之间也会产生变化。
Google表明在现代机器学习系统中特别普遍的一种故障原因是描述不足(underspecification)。描述不足指的是从业者在构建 ML模型时经常想到的需求与即模型的设计及执行之间的差距。
在实际实例中,Google发现描述不足还具有别的实际意义,事实表明单独的标准保持测试不足以确保其在医疗中的可用性。
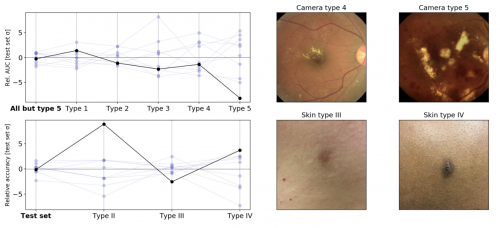
压力测试中医学影像模型的相对可变性。左上角:当对来自不同相机类型的图像进行评估时,使用不同随机种子训练的糖尿病视网膜病变分类模型之间的 AUC变化。
在这个实验中,在训练过程中没有遇到相机类型 5。左下角:在对不同估计皮肤类型进行评估时,使用不同随机种子训练的皮肤状况分类模型之间的准确性差异(由皮肤科医生培训的非专业人士从回顾性照片中得出的近似值,并可能受到标签错误的影响)。右:来自原始测试集(左)和压力测试集(右)的示例图像)。
解决描述不足是一个具有挑战性的问题,需要对超出标准预测性能的模型进行完整的规范和测试。要做到这一点,需要充分了解将使用模型的前因及后果,了解如何收集训练数据,并且通常在可用数据不足时结合领域专业知识。
应用程序帮助判断皮肤健康
Google AI驱动的皮肤病学辅助工具是一个基于网络的应用程序,辅助判断皮肤可能发生的情况。启动该工具后,只需使用手机的相机从不同角度拍摄三张皮肤、头发或指甲问题的图像。
然后,应用程序将询问用户皮肤类型、出现问题的时间以及其他症状。AI模型将分析信息,为用户提供可能的匹配条件列表,方便用户进行进一步确认。
根据用户提供的照片和信息,人工智能皮肤科辅助工具将提供建议的条件
对于每个匹配条件,该工具将提供皮肤科医生审查的信息和常见问题的答案,以及来自网络的类似匹配图像。
但需要注意的是,该工具并非旨在提供诊断,也不能替代医疗建议,Google开发该工具是希望帮助用户在可能出现皮肤问题的时候,及时就医,以便对下一步做出更明智的决定。