
经过昨夜OpenAI的科幻级演示,所有人都在等着今晚来自谷歌的反击。
如果说2023年的I/O大会是谷歌在AI领域的背水一战,今年的I/O大会上皮查虽然靠着自家的Gemini等产品逐步追上OpenAI,但形势却难称喜人。过去一年里,就算祭出免费两个月的大杀器,Gemini的用户量也不过是ChatGPT的1/5,每每有新品上市,必然被OpenAI截胡,让谷歌活活成了AI界的汪峰。
所以皮查太需要一场惊艳的发布会,拿回属于谷歌的牌面了。
所以与OpenAI的仅半个小时,集中在产品介绍的发布会完全不同。谷歌的I/O骨子里就透着一种武库尽出,拼死一战的意思。两个小时的发布会,它一口气拿出来十来款新品及升级,量大管饱,全面对标OpenAI在AI各领域上的发展。
很多产品单看Demo还是有着不错的完成度,但整场发布会没有一点像GPT-4o带来那样的惊艳感。因为他们发布的大多数是追赶那些OpenAI已有的东西,没人会为一些别人已经做到的事情感到惊艳。
最有可能带来惊艳感的新品——Gemini Astra的戏份已经被昨天的GPT-4o演完了。
到头来,想一秀肌肉的谷歌,还是被OpenAI四两拨千斤的卸了力。
我们更多的从它的搜索产品,模型产品上看到了谷歌的疲态,创新的缺失。
本想看巅峰对决,但实际上昨天这场对决就已经结束了。
另外,虽然除了本来就是期货发货的Gemini之外基本谷歌的这次发布又都是期货。看完整场发布会就像逛完一家期房交易中心一样失落,心里甚至有点“别是烂尾楼吧”的疑虑。在谷歌产品序列里这并不少见——Lydia,ESG,这些都是宣布了半年以上还没完全开放给用户的产品。在日新月异的AI领域,这个开放速度基本和烂尾无疑。
谷歌心急想秀肌肉我们理解,但是我们心急想用,不想看期货也希望谷歌能多理解。
因为产品太多,我们把他们做了个简单表格整合,连带发布和新升级的AI相关产品足足有14项:
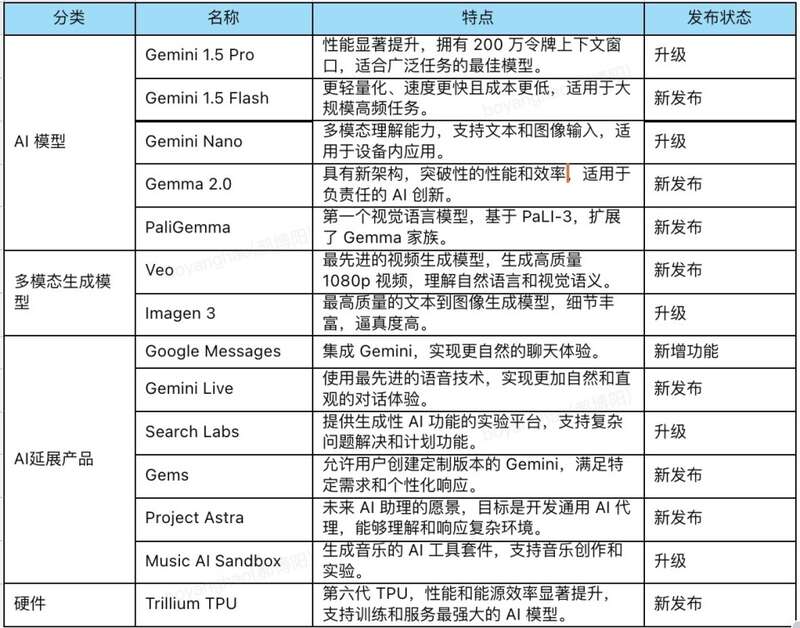
下面我们就沿着发布会的四大主题来拆解一下本次I/O大会谷歌带来的各项产品吧。
基础模型:Gemini 1.5 Pro 期货成真,Light 提速增效,Gemini 2 展露可能
在三个月前发布的Gemini 1.5 Pro终于不再是期货了!从今天起它将正式开放给订阅了Geminni Advance的用户。如果你之前没白嫖过,那这两个月内你都可以免费用。
除了期货成真,在没完全铺开的这三个月时间里,谷歌也没停止对它的升级,四个基础模型最重要的维度都做了加强。
首先是模型性能,谷歌通过数据和算法改进增强了其代码生成、逻辑推理和计划、多回合对话以及音频和图像理解能力。最新版本的 1.5 Pro 在多个benchmark中取得了Sota的成绩,谷歌扬眉吐气。
上下文方面,谷歌还把新Gemini 1.5 Pro 的上下文窗口从业界最高的100万token 扩展到合300本书的200万token。三个月就提升一倍,谷歌的表现证明了上下文的问题在今年看起来已经不再是什么门槛了。

在多模态支持上,Gemini Pro现在还把语音理解这个过去的短板部分进行了补齐,虽然不像GPT-4o一样是原生语音多模态,但总算是模态齐全,成了完全体。
非常影响使用体验的指令跟随能力方面,Gemini 1.5 Pro也进行了一轮更新。现在可以遵循越来越复杂和细微的指令,包括那些指定产品级行为(如角色、格式和风格)的指令。你现在能让Gemnini假装自己是猫了。
虽然没有公布Gemini 2,但四维拉满,从数据上看全面超越GPT4的Gemini 1.5 Pro应该还是能给谷歌撑起更大的场子。
后续宣布的Gemini 1.5 Flash就是本场的汪峰本峰了。它的主要特色——快速反应和昨天的GPT-4o完美撞车,本该有的惊艳感被完全破坏了。

从功能上看,虽然它比 1.5 Pro 轻量化,但它也能够跨大量信息进行多模态推理,并且擅长摘要、聊天、图像和视频字幕、长文档和表格的数据提取等工作。但与GPT-4o青出于蓝不同,Gemini 1.5 Flash还是牺牲了一些性能已达成其速度。
昨天GPT-4o基本上等于没写的技术报告没法解释的它的速度,谷歌比较老实,从技术文档上看,这是因为 Flash 通过一种称为“蒸馏”的过程,从较大的模型中传递最重要的知识和技能到较小、更高效的模型,实现了速度的提升。
这里展示的能力是需要Agent支持的,因此谷歌的下一个重磅产品是Project Astra。谷歌将其定义为自己的Agent战略的核心。

它是一种Agent 框架:为了真正有用,Agent需要像人类一样理解和响应复杂多变的世界——并且记住它看到和听到的内容以理解上下文并采取行动。它还需要具有主动性、可教性和个性化,这样用户可以自然地与它交流而不会有滞后或延迟。低延迟的要求,让你可以把Astra理解成Gemini Light 的Agent形式。在谷歌的展示中,它的最佳形态就是个人助手。
所以,为了让它更有用,谷歌通过持续编码视频帧、将视频和语音输入结合到事件时间线上,并缓存这些信息以实现高效回忆来更快地处理信息,就是能与视频交互,还有时间记忆。通过语音模型,谷歌还增强了Astra的声音,使Agent具有更广泛的语调,让这些Agent可以更好地理解它们所处的上下文,并在对话中快速响应。

从演示上看,Astra的视觉理解能力确实让人印象深刻。它可以理解薛定谔的猫之类的梗,反馈速度也非常快捷。
但它并没有超越想象。整个演示的感觉就是又看了一遍GPT-4o的视频沟通Demo。而且它远比GPT-4o期货,要几个月后才能上线。
谷歌表示,不是几周,而是今年晚些时候,这些功能中也仅有“一些”将进入谷歌的产品,可能是XR眼镜,也可能是个人助手。
所以Flash被GPT-4o的模型截胡,Astra 被GPT-4o的产品截胡。你说OpenAI没有内鬼知道谷歌 I/O的情报,我是绝对不信的。OpenAI只做了一件事,就是证明它能做,而且比你做的更好,出得比你更早。
不过再往下想,之前OpenAI都是在谷歌发布产品后再出个完全不同的升级来截胡谷歌热度。这一次却是赶在谷歌之前做了个功能完全一样的产品,来破它带来的惊喜感。这不由的让人怀疑,OpenAI是不是真的没有新品储备了。
除了这两个核心模型更新外,谷歌还宣布了前一阵大火的开源模型Gemma 的2.0版本,270亿参数。并为它拓展了PaliGemma这个多模态版本。鉴于Llama3 官方还没有微调多模态,这很可能是目前最强的官方开源多模态大模型了。据谷歌表示,它的开发是收到了Pali-3的影响。

多模态生成模型:谷歌版Sora颇为惊艳,其余都略微常规
除了文生视频模型的新公开,谷歌还推出了文生图像模型Imagen 3。从细节拟真度来看与Midjourney v6能达到同一级别,比起Dalle-3更胜一筹。而且在对细节的跟随上也要更细致。

音乐生成方面,去年惊艳众人的期货Lydia到这场发布会为止还是期货。谷歌又给他加了个新拓展 Music AI Sandbox,一套音乐 AI 工具。这些工具旨在为创意打开新的游乐场,让人们从头开始创作新的器乐部分,以新的方式转换声音等等。

然后就是酷炫播片,看起来比Suno厉害。但我用不着,所以还是能用的厉害。
最后,谷歌介绍了自己的视频生成模型——Veo 。它属于谷歌之前的一系列视频生成尝试的集大成者:融合了WALT、VideoPoet、Lumiere这几款在Sora之前发布的明星文生视频模型的长处。

从能力上看它相当能打,可以生成高质量的 1080p 分辨率视频,能够超过一分钟,涵盖广泛的电影和视觉风格。

从示例视频上看,Veo生成的画面相当一致且连贯:人物、动物和物体在镜头中移动的很真实。
谷歌还表示,Veo 具有对自然语言和视觉语义的高级理解能力,能够生成与用户创意愿景紧密匹配的视频——准确呈现详细的长提示并捕捉情感。Veo甚至还能理解电影术语,如“延时”或“航拍镜头”。

从质量上讲,谷歌的Veo和Sora足有一战之力。但是不得不说谷歌真的不太会演示。整个演示过程中,他们就放了一段汽车追逐的长生成视频,还不是全屏,看不清细节。其他的都是小片段,小画幅,细节模糊。震撼力大打折扣。
然而,和Sora一样,Veo 只会将作为 VideoFX 内的私人预览版提供给少量创作者,一般用户可以报名加入候补队列。不过这也说明,靠着VEo,现在谷歌和OpenAI已经进入了谁能首先压缩成本,把这一技术推向toC领域的同一场竞赛了。
AI搜索:多模态最强,但创新有限
AI搜索可以说是谷歌的必争之地。面对着来势汹汹,号称要取代谷歌搜索的新秀Perplexity们,谷歌就算不用AI,也得留着后者。
从去年一年来看,新兴的AI搜索虽然获得了不少用户,但基本上没有动摇到谷歌搜索的根基。所以谷歌也是一副不紧不慢的样子:它的AI搜索服务ESG从去年五月到现在,整整公布一年时间后总算从今天起向公众开放使用了。这个更强的AI搜索引擎被谷歌命名为AI Overview,但仅限美国,其他国家还得排队等着开。
从Demo展示来看,谷歌搜索在功能上的创新不算多,主要集中在多模态。
首先,用户将能够通过简化语言或更详细地分解来调整 AI 搜索结果概述。这个功能并不新,现在主流的AI搜索产品也会区分快捷回复和更深入的研究模式。
其次,借助 Gemini 的多步推理能力,AI 搜索可以一次性处理复杂的多步,乃至多问题。比如说,当用户寻找一个新的瑜伽或普拉提工作室,用户希望找到受当地人欢迎,方便用户的通勤,并且还提供新会员折扣的选项。通过谷歌AI搜索,用户将能够通过一次搜索询问类似“查找波士顿最好的瑜伽或普拉提工作室,并显示其入门优惠和从 Beacon Hill 步行时间的详细信息”的问题得到最佳答案。
这也是其他AI搜索产品现在在努力攻破的一个方向。谷歌在这方面凭借着模型优势很可能会处理的更好。
同样构建在多步推理能力之上的是AI搜索的计划能力。通过AI搜索中的计划功能,你可以直接在搜索里获得一个完整的计划。比如搜索类似“为一群人创建一个易于准备的三天餐饮计划”,您将获得一个起点,包含来自网络各处的各种食谱。这是其他搜索软件暂时还没有专精的能力。但是对于可联网的ChatGPT来说,这应该不是难事。当然,谷歌搜索组织的更漂亮,还可以直接连接,用户体验更优。

GPT-4o生成的版本
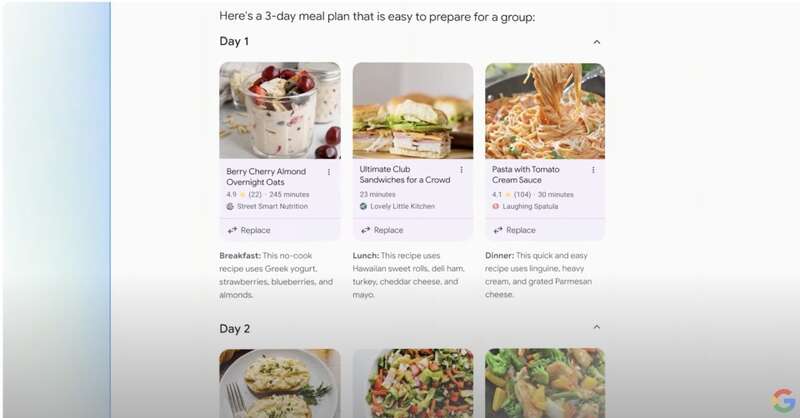
谷歌生成的版本
最后是灵感延展功能,就是AI搜索在创建一个 AI 组织的结果页面,使您更容易探索。在问了一个问题后,谷歌搜索将会延展到其他可能你感兴趣的结果,按独特的 AI 生成标题分类,展示广泛的视角和内容类型。这种联想搜索能力也已经是AI搜索的某种标配了,但谷歌对这个功能做了更好的结构化。
以上的功能,其他的AI搜索都能做,但谷歌的结构化和界面做的最好。也仅此而已。
最后其他AI搜索暂时做不到的是多模态搜索。
靠Gemini的多模态功能,谷歌可以做到利用声音搜歌曲,利用图片搜产品。甚至可以用Circle to Secarch 功能圈出图片中的一部分去搜索。

但Perplexity们,总有用上多模态模型的那一天。而且看到他们用看图视花做例子介绍谷歌搜索的多模态功能时,我第一个想到的是微信扫一扫,不就能干吗(虽然原理并不相同)?
模型产品升级:谷歌版GPTs上线,生态刚追及
模型产品可以说是最让人失望的环节。新意全无,还多少让人看出谷歌的保守态势。
首先登场的是结合Gemini的Wrokspace。
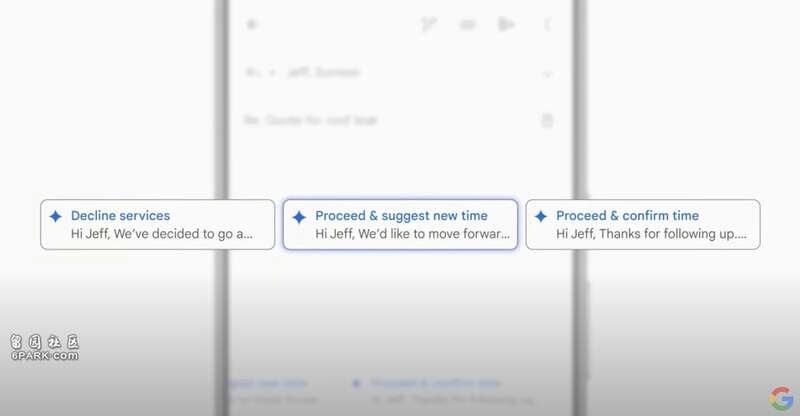
你可以通过 Side Panel(一个能唤起Gemini的侧边栏)功能总结一系列邮件,可以总结你的账单,形成一个Sheet。OK,去年看过了。自动回复邮件。去年看过了。
每个都进行了小的升级,比如回复邮件可以从确认,回绝,搁置三种可能中选了。但……现场都掌声寥寥。
其他的更新,包括在聊天软件里的虚拟员工Chip,能力基本没超过前几个月我们在国内看到的各种办公软件Agent的演示。
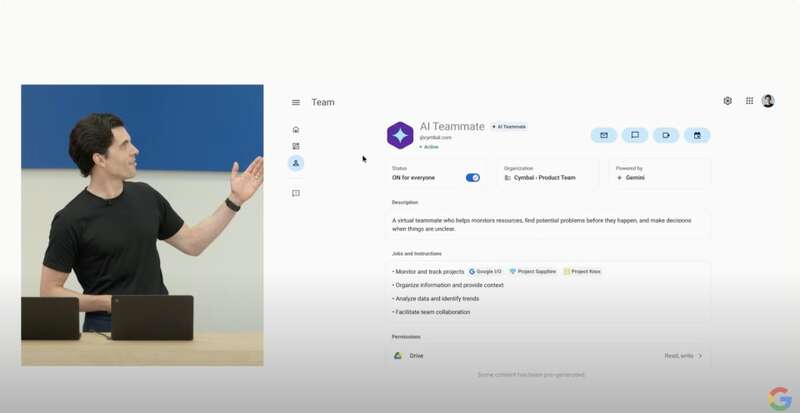
整体看下来,就是去年I/O大会上谷歌展示的可能性下个月就能实现了。因为Side Panel这个产品下个月才公众开放。
模型产品里最重要的更新就是Gmini Live。这是一个移动对话助理性产品,通过 Gemini Live,用户可以与 Gemini 对话,并选择它可以用来回应的各种自然声音。用户甚至可以按照自己的节奏说话或在回答中途打断以提出澄清问题,就像您在任何对话中一样。而且今年晚些时候,用户将能够在上线时使用摄像头,而开启关于周围所见内容的对话。

好的,又一次GPT-4o的即视感。
剩下其余几个产品升级都纯属是追赶性质。
Gems登场的时候真的有点尴尬,全场鸦雀无声,因为大家一听介绍就明白了这就是谷歌的GPTs,还是慢了半年的版本。用户可以创建一个定制化Geminni。通过描述希望 Gem 做什么以及希望它如何回应,例如“你是我的跑步教练,给我一个每日跑步计划,并保持积极、乐观和激励的态度。”,Gemini 将根据这些指示进行增强,以创建一个符合您特定需求的 Gem。
所以只能通过Prompt制定,没有外接工具,没有工作流。
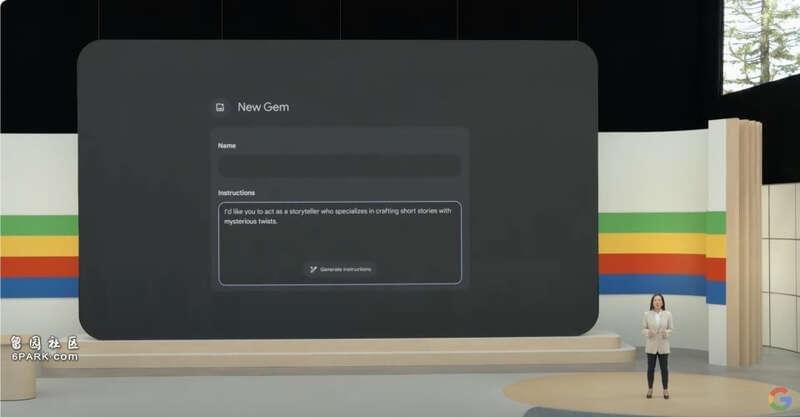
这属于发布晚了半年,功能还不如GPTs的Agent产品。
去年上线的API扩展功能将再次扩大,例如正在推出的 YouTube Music 扩展、Google Calendar、Tasks 和 Keep。全是谷歌自家的服务。说实话,在这次扩展之前,谷歌的插件库就这么五个插件,完全是少的可怜。就算加上这些新拓展,和其他Agent产品支持的API库也完全无法同日而语。
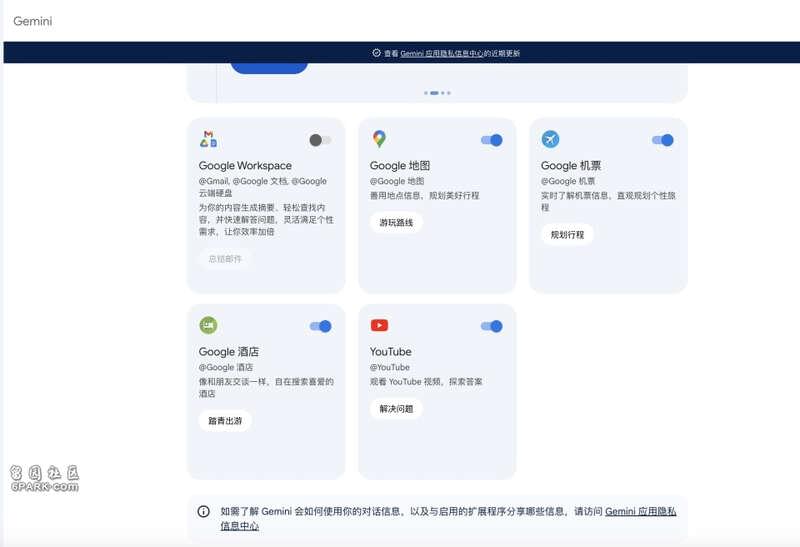
(发布会之前,只有这几个拓展可用)
就从这一点上看,谷歌固步自封在自己的生态里的沙文心态一眼可见。
Andriod + AI:风光被GPT桌面版占尽
除了 Cricle in Search这个聚焦具体图片局部的多模态搜索外,本次Android AI重点是介绍了Gemini的手机应用,可以和手机上正在展示的内容进行互动。比如阅读打开的PDF,从你正在看的YouTube频道反馈问题。
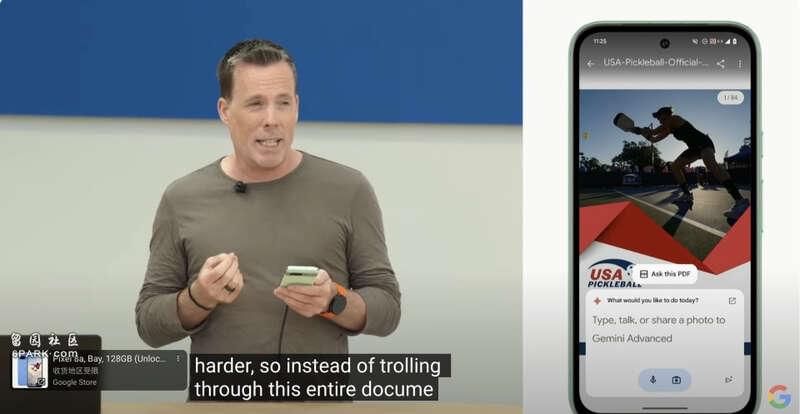
挺好的,GPT-4o的桌面版昨天都做到了,而且比起这里Android实际上是读取打开的文件,GPT-4o的版本更像是和你一起在看着桌面上发生的一切。另外,它还有美妙的语音。
硬件:TPU稳步升级
在这次发布会上,所有的AI模型都是由谷歌最新的TPU——Trillium TPU训练的。相较于前代,它的进步还是非常明显的。 Trillium实现了每芯片峰值计算性能的 4.7 倍提升,比 TPU v5e 提高了一倍。高带宽内存(HBM)的容量和带宽和芯片间互连(ICI)的带宽也比v5e翻了一番。

此外,Trillium 配备了第三代 SparseCore,这是一种专门用于处理超大嵌入的加速器,常见于先进的排序和推荐工作负载中。Trillium TPU 使训练下一波基础模型更快,并以更低的延迟和更低的成本服务这些模型。Trillium 可以扩展到一个包含 256 个 TPU 的单个高带宽低延迟 Pod。
另外,能耗上Trillium TPU 比 TPU v5e 的能源效率提高了 67% 以上,省电能力一流。
结语
这场发布会,看的人挺折磨的。
我们想看新的、有竞争力的产品,谷歌却在不停的播片。从创作者感受,到体验演示,就是没有产品细部的表现。
我们想看现场演示,但演示内容平淡无奇。
甚至在很多地方是重复的,很多产品在不同位置被多次提到并展示。
因此这两个小时的时间显得无比冗长,枯燥。
因为没有惊喜,我甚至都很少被调动起好奇的情绪。
这当然有OpenAI截胡的原因,但昨天25分钟,三个产品(其中一个UI还基本没说)的发布会,就足够破坏谷歌这两个小时里的十多个产品发布更新所带来的所有惊喜。
这说明了什么问题?
毫无疑问,谷歌的技术力还在,那些模型都很能打。但那些让人赞叹的技术突破,让人兴奋的产品演示,都没有了。有的都是可预期的表现,难超同行的功能。
在一个新技术的时代,一个无比需要去开创可能性的时代中,想象力可能才是最重要的。
但今天这场发布会里的谷歌,没有想象力了。
我有点为它惋惜。