
有朋友问:Leslie,你是专业建厂出身,之前传出山姆·奥特曼要投资7万亿造芯,虽然本人不明确回应,但大媒体传出来,一定不是空穴来风。如果有7万亿,造划算,还是买划算?如果造,可能要考虑哪些方面的投入及因素?
奥特曼的“7万亿”传闻的确是石破天惊,构想很有意思,回答这个问题得具备丰富的半导体建厂,工艺,运营等一系列知识,我们可以尝试推算一下,如果手握7万亿美元,如何将这笔钱“合理地”花出去?
每万片晶圆,建厂投资150亿美元
首先,第一步必然是生产GPU逻辑芯片,这样一来需要先盖一座逻辑晶圆厂。我们以台积电最先进的2nm工厂为例,看看每万片晶圆的资本投入情况。
按投资额划分,晶圆厂各项投入比例大致为:制程设备:77%,土地与建筑物:4%,洁净室:5%,水电气化学品等供应系统设施:14%。
光刻机是晶圆厂最大的制程设备投资项目之一,占比在20%左右,而且2nm需要用到EUV光刻机(负责其中25层的光刻),成本相对更高,占比预计会提升至24%左右。
目前台积电的2nm还是采用低数值孔径的EUV,对应ASML最新款的NXE:3800E,其每小时产出晶圆(WPH,Wafer per hour)大致在190-200片的区间,单台设备每月产能预计2400片左右(具体计算见下表注释),这意味着每万片晶圆的产能,需要4台ASML的NXE:3800 EUV光刻机。而除了EUV负责的25层外,其余层还需要3台每小时产出晶圆295片的NXT:2100,以及一台KrF DUV光刻机。
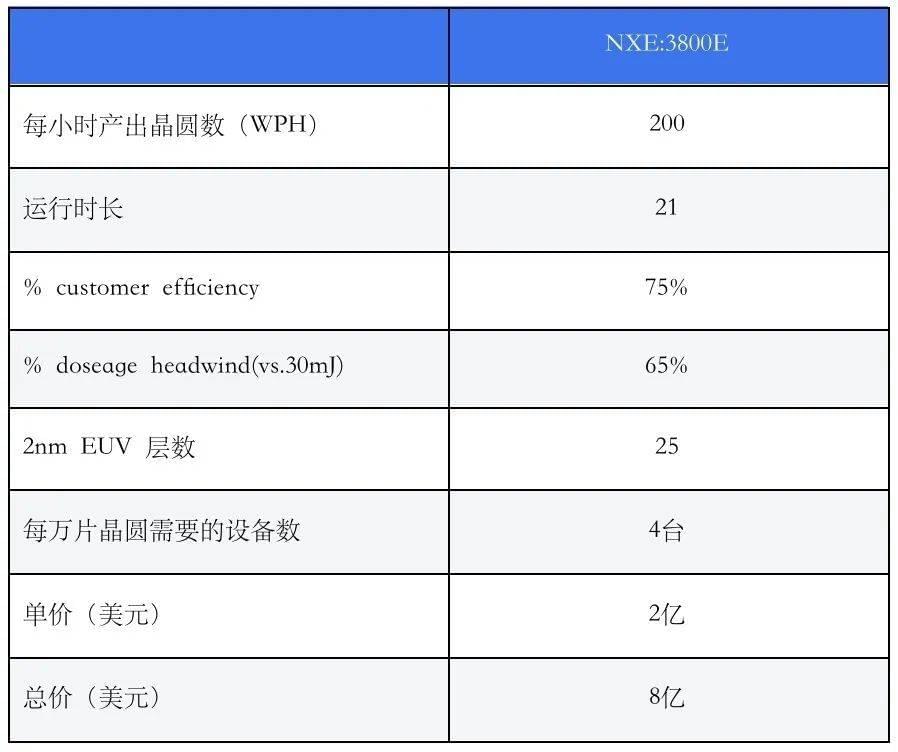
*单台设备月产能=每小时产出晶圆数*运行时长*% customer efficiency(效率)*% doseage headwind(vs.30mJ)*EUV层数*30天
按照ASML提供的数据,NXE:3800E售价2亿美元左右,NXT:2100i约7500万美元,KrF DUV约1500万美元,这意味着2nm工艺的晶圆厂,每万片晶圆产能,光刻机(含维修以及备件)的投入预计在13亿美元左右。
按照光刻机的投入占全部制程设备24%的比例倒推,制程设备的总投入为54亿美元,而制程设备占晶圆厂全部投资额的77%,以此倒推,2nm节点,每万片晶圆产能,晶圆厂总投资额大致为71亿美元。
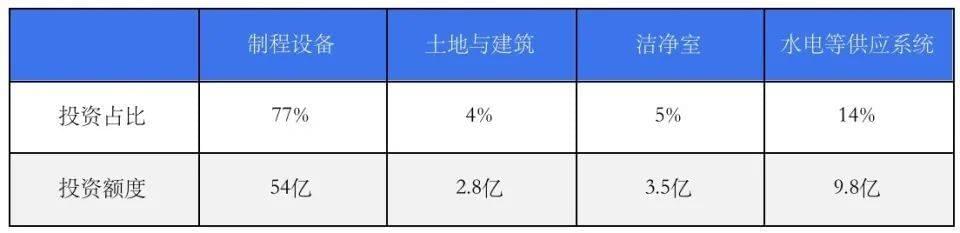
每万片晶圆产能,晶圆厂总投资额划分,单位:美元
建完GPU逻辑芯片厂之后,还要考虑生产HBM的DRAM厂的建设。
我们以最先进的1gamma制程为例,尽管DRAM的EUV光刻层有所减少,但每万片晶圆需要的设备数量却不降反增,尤其是刻蚀设备,整体估算下来,1gamma制程的DRAM厂投资额大概在逻辑芯片晶圆厂的总投资额的85%,即60亿美元左右。
补充说一下,DUV时代,DRAM厂的投资额大概为同级别的逻辑晶圆厂110%-120%,直到7nm节点,逻辑厂开始大量使用EUV光刻机,每万片晶圆产能的投资额开始反超DRAM厂。
解决前段的GPU逻辑芯片和DRAM存储芯片之后,还要解决后段的封装问题,包括CoWoS先进封装、HBM封装两部分。
目前,最先进的AI芯片采用的是SoIC+CoWoS封装技术,HBM4将会采用混合键合(Hybrid Bonding),每万片晶圆的投资额将大幅提高至10亿美元(含设备厂房)。另外,先进封装涉及到的中介层,也还需利用DUV构建配套的65/45nm的前段晶圆厂,投资额为每万片晶圆8亿美元。也就是说,封装部分,每万片晶圆的整体投资额预计在18亿美元左右。

每万片晶圆产能,不同晶圆厂单位投资额,单位:美元
这个花钱的活涉及到的数据比较多,帮大家做一个小总结,每万片晶圆产能,或者说单位投资额,对应2nm制程的逻辑晶圆厂、1gamma制程的DRAM厂、封装厂(先进封装+中介层,10亿美元+8亿美元)方面的投资,合计在150亿美元左右。
年产600万颗GPU,成本500亿美元
但是,GPU逻辑芯片、HBM内存以及中介层,对应的比例不是1:1:1的关系,所有总投资额还要在单位投资额的基础上,按照系数增加,这个系数大致可以从一颗GPU,所需要的CPU、HBM内存、中介层的数量来推算。
以英伟达最新的Blackwell架构GPUB200的Die size(814mm²)为例,每片晶圆可以切80颗芯片,按照台积电最好的工艺,良率大致在65%左右,即每片晶圆可以切50颗Good Die。
附带说一下,由于GPU逻辑芯片是大芯片,为了提高光刻的曝光清晰面积,物镜成像的景深就需要控制在相对较大水平,这会导致分辨率降低,是缺陷变多,良率下降的重要原因。
英伟达的B200搭配了Grace CPU,2颗GPU搭配1颗Grace CPU,那么50颗GPU,需要搭配25颗CPU。按照3nm制程计算,以CPU的Die Size和良率预估,一片晶圆可以切300颗左右的CPU芯片,这意味着一片GPU晶圆,需要搭配0.08片CPU晶圆。
目前3nm节点,每万片晶圆的投资是2nm节点的70%,大致50亿美元,也就是说投入71亿美元生产10000片GPU晶圆的同时,还要对应投资71亿美元×70%×0.08,即4亿美元,用于CPU晶圆的生产。
AI芯片的另一个重头戏即HBM,英伟达的H100、H200标配6颗,到Blackwell架构的B200,则采用了8颗HBM3e内存。按照台积电最新的路线图,2026年,一颗GPU可以搭配12颗HBM内存,届时HBM的规格还将从12层堆叠的HBM3e,升级至16层堆叠的HBM4/4e。
如前文所述,2nm晶圆可以切出50颗GPU逻辑芯片,按照B200的标准,每片晶圆需要搭配400颗HBM3e内存。目前,1gamma制程的DRAM芯片,每片晶圆大概可以出1200颗DRAM颗粒,而按照85%的良率计算,最终可以得到1000颗DRAM颗粒,之后要将这些DRAM颗粒封装成12层堆叠的HBM3e内存。当下封装的良率大概在80%,即一片DRAM晶圆可以出1000÷12*80%,约等于70颗左右12层堆叠的HBM3e内存。
也就是说,一片GPU晶圆,除了需要0.08片CPU晶圆,还需要5.7片DRAM晶圆。未来随着GPU逻辑芯片搭配HBM颗粒数进一步增加,尤其是堆叠数量从12层提升到16层,GPU:DRAM晶圆(1:5.7)的比例,还会进一步扩大。
按现有先进封装的中介层尺寸,一片晶圆可以完成15颗GPU逻辑芯片的封装,对应一片GPU逻辑芯片的晶圆,需要3.3片晶圆的先进封装。
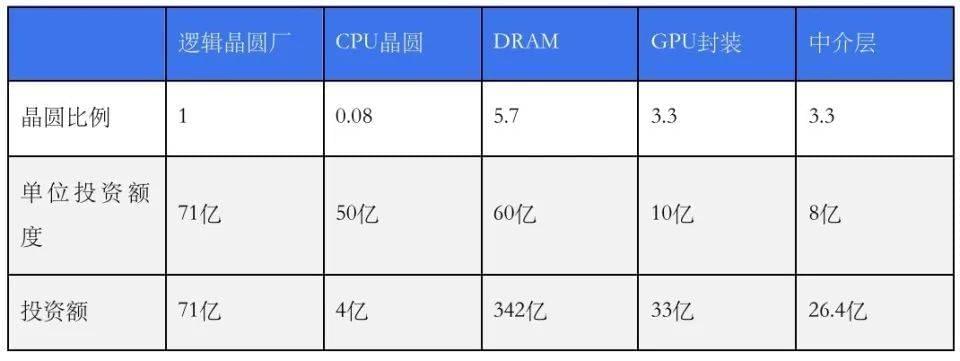
每万片晶圆产能,不同晶圆厂的建厂投资总额,单位:美元
一句话总结:每10000片GPU晶圆,需要800片CPU晶圆,5.7万片DRAM晶圆,3.3万片中介层晶圆,3.3万片SoIC+CoWoS先进封装,5.7万片HBM封装,对应的投资额,即1*71+0.08*50+5.7*60+3.3*10+3.3*8+5.7*10≈476亿美元。
每10000片GPU晶圆所有配套芯片的生产工厂需要耗费476亿美元,加上其他杂七杂八费用直接算整数为500亿美元,换算成GPU芯片数量,为每月50万颗,一年600万颗。
8年半可以烧完7万亿美元
投资500亿美元,一年生产600万颗GPU,这是个什么概念?可以根据台积电CoWoS产能,来推算全世界的AI GPU的量,然后再进行对比。
2024年,台积电CoWoS总共31万片的产能,其中95%都是给AI GPU,只有1万多片是给Xilinx的FPGA,剩下的近30万片产能被英伟达、AMD以及全球互联网大厂诸如Google,AWS,Meta,Mircosoft自研的ASIC芯片瓜分。
也就是说,台积电CoWoS产能代表全世界AI芯片产能,2024年80%的GPU还是只使用2.5D CoWoS,英伟达的H100大约是每片29颗,其他自研ASIC则都高于这个标准,有的还超过40颗,目前只有AMD的MI300使用SoIC封装,每片约为15颗。
综合下来,今年台积电30万片CoWoS产能,对应大约是1000万颗GPU,这也就是2024年全球AI GPU的大致总量。前面提到,投入500亿美元,每年可生产600万颗GPU,也就是说,在2024年,想要生产满足全世界需求的1000万颗AI GPU,总投入需要830亿美元。这个水平相当于台积电2-3年的资本支出,也大概是台积电Fab20A,一座月产12万片的2nm芯片工厂的总投资额。
投入830亿美元,就能生产出2024年全世界所需要的AI芯片,想要把奥特曼的7万亿美元花完,还有很多工作要做,毕竟830亿美元也仅仅是建设芯片工厂的费用。
芯片厂、DRAM厂、封装厂都盖完之后,就要考虑生产服务器的工厂建设,还得盖许多座类似工业富联的这样的工厂。不过这类服务器组装工厂与芯片工厂相比来说,只是小巫见大巫,把AI服务器所有产业链上的工厂全部建设起来,包含服务器,光模块,液冷,铜线材,各式各样的模具厂,年产1000万颗GPU,按单个服务器8颗GPU算,即120万台服务器,所有下游工厂的总投资额大致为170亿美元。加上上游芯片工厂的830亿美元,1000亿美元则是2024年全球所有AI 芯片+服务器出货量所需的工厂建设总成本。
上下游工厂建设只是开端,工艺还需要持续的研发投入,包括设计、制造相关的研发费用,覆盖GPU、CPU、HBM、先进封装等等环节,这部分可以打包算一下英伟达、AMD、台积电、SK海力士的研发总额,大致300亿美元。再加上服务器硬件研发、比如光模块、液冷等等,研发部分的费用满打满算可以达到500亿美元。
而对于OpenAI,在推进AGI的路上,也需要持续进行模型研发投入,每年在这上面的费用至少200亿美元。
芯片部分的研发+AI部分的研发,每年的总投入至少在700亿美元,如果要更快推进,加大研发投入是必然,所有推进AGI终极目标的研发投入,每年估算需加大投入到1000亿美元。
以上的研发费用还不包括训练费用,且训练需要大量的水电资源消耗,这部分基础设施同样需要自建。
欧美地区目前建设1KW核电机组的成本大约4000美元,每百万千瓦的核电机组一年发电量约为8.6亿度电,根据IEA(国际能源协会)计算,2027年全球人工智能将耗费1340亿度电,所以要建设155组百万千瓦的核能机组,这需要6000亿美元左右。
根据加州大学河滨分校的研究,2027年人工智能将耗费66亿立方米的清洁淡水,大约是全英国一半的用水量,主要场景来自于服务器的冷却,发电以及芯片制造这三大耗水环节,建设相应的水处理厂费用大约为1000亿美元。
相比前面的投资,制造环节的人力成本规模相对较小,重头戏主要在芯片的设计,包括模型研发部分。
前段晶圆厂把人力配置拉满 , 每万片约需要1000人,后段约1500人,2000万颗GPU年产能的所有前段工厂(含DRAM,中介层等)大约需要2万人,人均年芯为15万美元,后段封装需要3万人,人均年薪约为7万美元,加上5000名各类芯片制造研发人员,人均20万美元,每年芯片制造的人员薪资费用总共60亿美元。
芯片设计以及大语言模型的人力成本方面,按照英伟达+OpenAI+微软服务器部门的1.5倍计算,约为5万人,人均年薪30万美元,共150亿美元涉及服务器所有硬件制造的工厂人数为15万人,电力以及用水保障设施人员15万人,共30万人,人均年薪8万美元,总共为240亿美元。
以上所有环节,人力薪资成本为每年60亿+150亿+240亿,共450亿美元。
物料成本方面,GPU及相关芯片,再加上所有服务器硬件的成本为2000美元/颗,年产2000万颗,即400亿美元。服务器的运营费用方面,人工420亿美元+物料成本400亿美元+其他杂费180亿美元,取整数1000亿美元。
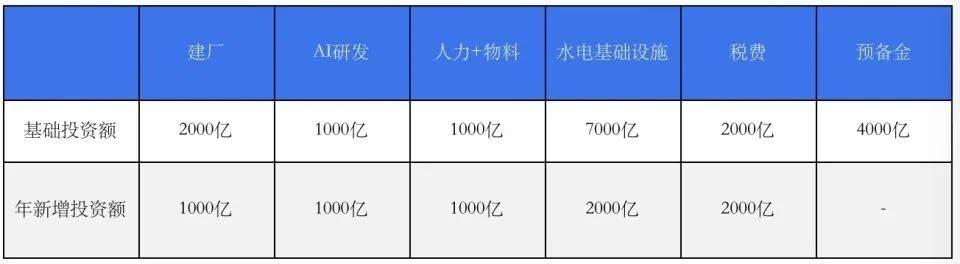
OpenAI年产2000万颗GPU的投资额及各项费用推算,单位:美元
以上即奥特曼亲自下场造芯涉及到的主要环节的费用的拆解。如果替奥特曼花这笔钱,理想的方案是:
2000亿美元建设年产2000万颗GPU(024年全球约1000万颗)以及涉及所有服务器硬件的制造工厂,然后为了推进AGI的终极目标每年投入1000亿美元的研发投入,相关设计、研发、制造总人力成本1000亿美元,投资7000亿建设能源以及用水的基础设施。
同时编列2000亿美元现金应付税费以及各种杂费或者没有计算到的费用,最后保留4000亿美元作为可能漏算的预备金,如此一来,大约需要1.7万亿美元,就可以覆盖2000万颗AI GPU所有制造工厂的启动资金。
运营资金方面,要保持每年1000亿美元的芯片以及硬件新产能投入,并持续推进摩尔定律,提升晶体管密度。每年新增2000亿美元的新电力及新用水投入,再加上人工以及物料等每年约1000亿美元,这样的话,每年的极限是新增7000亿美元的运营费用。
如此一来,不到2万亿美元即可覆盖2024年全球AI芯片需求量两倍的所有相关制造,能源基础设施和运营费用,每年新增控制在7000亿美元的水平,这笔预算大致可以再烧7.5年。
怒砸2万亿美元,拥有全世界AI GPU两倍产能 ,奥特曼也无法垄断全球人工智能——OpenAI的模型领先全球,建立在以台积电为代表的全球最先进的芯片制造,以及以英伟达为代表的GPU芯片设计的基础之上。如果奥特曼另起炉灶,全方位生产AI芯片,几乎是得罪了目前全球的芯片企业。
作为“旧势力”,台积电、英伟达以及众多芯片设计公司,有可能会扶持OpenAI的所有竞争对手,包括硅谷乃至于全球的大大小小做大模型以及AI应用的企业,诸如老对手DeepMind加上谷歌,AWS,Mircosoft等巨头,以及Stability、OpenAI前创始人成立的Anthropic等创企。
即便OpenAI的芯片设计与制造能力与台积电、英伟达相当,面对全球所有大小模型与算法的一众企业,本身就不一定有绝对优势,更何况带着7万亿美元下场造芯片,站在英伟达、台积电的对立面。
客观地说,如果不考虑生态,GPU设计公司倒不是那么无可替代。在GPU设计上,没有英伟达还有AMD,甚至还有Cerebras这类设计整片晶圆面积远远超过传统GPU的AI芯片设计公司,但在芯片制造上,目前台积电呈现一骑绝尘的态势。
以2024年为例,台积电可生产每平方毫米高达2.84亿晶体管密度的N3P工艺,排名第二的英特尔还只能生产每平方毫米1.8亿晶体管的Intel 4,第一跟第二之间已经出现了代差,如果在最高性能的芯片上不使用台积电工艺,在基础上就落后竞争对手一个世代。
芯片制造无法用钱堆砌,更需要技术积累的行业,往死里砸钱砸人,最快也要三年才能建设好芯片工厂并生产出芯片。对OpenAI来说,假设“7万亿美元”真实存在,面对“旧势力”的反扑,也至少要撑过这三年。
本文来自微信公众号:腾讯科技(ID:qqtech),作者:Leslie Wu