
大模型就要没弹药了,训练数据成为大模型升级的最大拦路虎。
《纽约时报》报道,为了训练GPT-4,OpenAI使用其旗下语音转文字模型Whisper挖掘了超100万小时的YouTube数据作为其训练模型。而另一端,社交媒体巨头Meta高层也在讨论收购出版社 Simon & Schuster来完成基础模型对高质量训练数据的需求。
但即使如此,现有人类社会生成的包含社交文本在内的互联网数据也不能够支持大语言模型的优化升级。研究机构Epoch报告,在未来两年内,AI训练将用尽互联网上包含音视频在内的高质量数据格式,而现存(包括未来生成的)数据集或将在2030年至2060年之间耗尽。
除了物理世界现实存在的数据,科技公司还考虑使用合成数据作为AI训练材料。合成数据就是用AI生成的数据训练大语言模型。不过,合成数据也就意味着更高的计算费用和人才支出,这也让本就高昂的AI成本雪上加霜。
一、最优的数据,最好的大模型
据悉,GPT-4有着超1.8万亿参数和13万亿token的训练数据。
13万亿,相当于自1962年开始收集书籍的牛津大学博德利图书馆存储的单词数量的12.5倍。这些数据来源于新闻报道、数字书籍、Facebook社交平台数据。不过在这之前,我们并不知道还有基于视频转录的文字。据传,Google模型也使用了Youtube转译的文字作为其大模型训练数据。
不止ChatGPT,市面上的大模型都是建立在上亿级模型的训练基础上的。谷歌的 BERT是在英语维基百科和BookCorpus中包含33亿单词的数据集上进行训练的,微软的 Turing-NLG是在英语网页中超过170亿个词组的数据集上进行训练的。
可以说,数据就是AI模型的燃料。根据标度定律(scaling law),训练模型的数据越丰富,来源愈丰富、异质化愈强,模型的质量越高,语义理解能力越强。这不难理解,AI就像是一个小孩,需要学习大量的课本、报道,而一个学生学习掌握的知识越多,一定程度上就越聪明,能处理的任务就越多。
大模型的数据训练是一个迭代的过程。2020年之前,大部分的AI模型数据量相对较小,大多在1000万以下。举个例子,GPT2的训练数据就是40G,GPT3的训练数据则高达570G,约为GPT2的15倍。高达3000亿token的GPT-3开启了大语言模型千亿级token训练的先河。
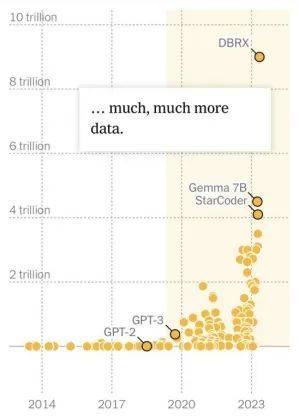
大语言模型训练数据规模
数据规模固然重要,但数据质量也同样不容忽视,有失偏颇的数据可能会造成潜在的刻板歧视和偏见,比如最近引起巨大争议的Meta图像生成案,不能生成白人女性和亚洲男性同框的图像。
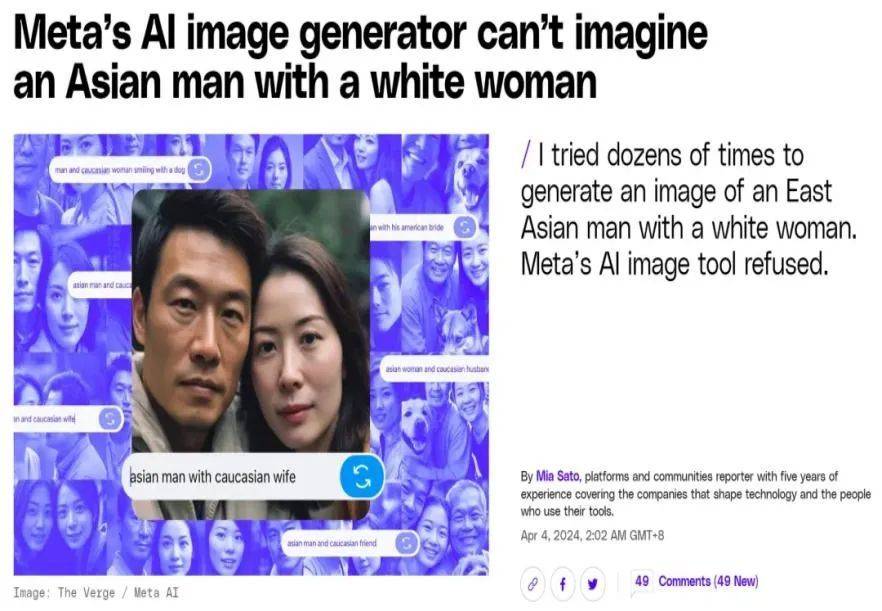
Meta图像生成器拒绝生成亚洲男性和白人女性的图片
所以,AI的训练数据不仅强调量大,更强调样本的异质性,代表的多样性。OpenA负责人Peter Deng就曾说过,训练AI的数据最好能够体现不同民族、不同文化的价值观,大模型发展应该避免民族中心主义和文化霸权,特定来源的训练材料总是有失偏颇的。
最优的大模型需要最好的数据,但是数据也不是天上掉下来的免费午餐。随着模型升级和巨头之间的科技军备赛的白热化,限制LLM发展的最大拦路虎不再是技术本身,而是最关键的也是最容易忽略的因素——数据。
二、供不应求,LLM训练遭遇数据困境
现阶段的AI训练数据主要包括新闻报道、虚构作品、留言板帖子、维基百科文章、计算机程序、照片和播客,比如common crawl,一家从2007年以来收集了超2500亿网页文章的数据库,有1000TB的数据量。
当下的LLM数据困境,主要体现在两个方面:
一是高质量数据的规模有限。高质量数据通常包括出版书籍、文学作品、学术论文、学校课本、权威媒体的新闻报道、维基百科、百度百科等,经过时间、人类验证过的文本、视频、音频等数据。
与大模型训练数据规模每年翻倍不同,这些高质量数据的增长非常缓慢。以出版社书籍为例,需要经过市场调研、初稿、编辑、再审等繁琐流程,耗费几个月甚至几年时间才能出版一本书。这意味着,高质量数据的产出速度,远远落后大模型训练数据需求的增长。
研究机构Epoch称,科技公司或将在2026年使用完互联网上所有可用于模型训练的高质量数据,包括维基百科、学术期刊论文等高质量数据文本。同时,AI公司使用数据的速度比社会生成数据的速度要快,该机构预计在2030-2060年之间,能用于AI训练的人类数据将会全部耗尽。
除了高质量数据本身有限外,这些数据获得难度也在大大提升。由于担心平补偿等问题,社交媒体平台、新闻出版商和其他公司一直在限制AI公司,使用自家平台数据进行人工智能训练。
去年7月,Reddit 就表示将大幅提高访问其 API 的费用。该公司的管理人员表示,这些变化是对人工智能公司窃取其数据的回应。Reddit 创始人兼首席执行官 Steve Huffman 告诉《纽约时报》:“Reddit 的数据库真的很有价值。”“但我们不需要把所有这些价值都免费提供给一些全球最大的公司。”
此前,OpenAI也曾因未经授权使用新闻报道与《纽约时报》打了官司,英伟达也因未经授权使用原创小说遭到美国作家的联合诉讼。
总的来说,大模型企业已经基本上搜刮了电子数据、新闻报道、社交媒体数据等所有能够想到的数据来源。而部分明确受到保护的版权作品,科技巨头在短时间内也难以征得其训练版权。同时,高昂的版权费可能也会令目前盈利能力微弱的AI公司捉襟见肘。
在这种情况下,科技巨头纷纷殚精竭虑寻找优质训练数据喂给自身模型,也就有了OpenAI采集超百万小时YouTube数据,为GPT-4提供训练素材的故事了。
据了解,OpenAI的数据收集策略并不仅限于YouTube视频。该公司还从Github的计算机代码、国际象棋走棋数据库以及Quizlet的作业内容中获取数据。OpenAI发言人Lindsay Held在一封电子邮件中透露,公司为其每个模型都策划了独特的数据集,以保持其全球研究竞争力。
在最近的一次高层管理会议中,Meta高管甚至还建议收购出版社 Simon & Schuster以采购包括史蒂芬金等知名作家作品在内的长篇小说为其AI模型提供训练数据。
出于法律风险、成本等因素的考量,越来越多公司开始尝试自己制作的训练数据——合成数据。
三、AI合成,会是模型训练的救命稻草吗?
合成数据是一种通过算法或计算机模型生成的数据,它模拟实际情况,但无需通过收集实际数据来实现,而是让AI自己生成文本、图像、代码再反哺给自己的训练系统,生成现实世界中难以获取的数据。
这并不是一个新的概念。合成数据在自动驾驶等领域有着广泛应用。比如,车企可以通过合成数据模拟真实的驾驶场景,为自动驾驶系统提供大量训练数据。
使用合成数据的好处显而易见。一方面,合成数据可以降低人工收集、处理和标注的成本,提高模型训练的效率。同时,合成数据一定程度上也突破了非平台企业的数据瓶颈。一直以来,X、Meta、Instagram等社交平台的用户数据都被微软、谷歌几家大头垄断。初创公司和小微企业难以获得训练自己的AI模型,而合成数据可以通过模拟物理世界的真实行为合成这些数据,从而降低了初创公司训练大语言模型的成本。
但与此同时,合成数据的缺点也明显。作为一种数据建模解决方案,AI合成数据最大的特征是“全面控制”,从代码到算法到微调,程序员可以模拟、调控数据生成的整个过程。这也就意味着,合成数据最大的问题是“有失偏颇”。
相比垂直大模型,通用大模型更加强调数据的异质化、差异性和多样性。但在现阶段,AI的智能程度还难以生成具备多样性、代表性、高质量的训练数据,毕竟机器生成的数据底层逻辑基于人类程序员的设计,难以反映出大千世界的多元文化。
具体来说,建立在合成数据上的大语言模型不可避免地带有内嵌的机器学习思维,而训练数据中合成数据的占比越大,自然语言理解能力或许就越低。这也是AI界固有存在的hallucination幻觉问题,即生成与人工指令prompt不符的胡言乱语。
更不用说,大模型还不可避免地带有人类社会固有的偏见(比如种族歧视、文化霸权等),比如今年二月份谷歌通用人工智能助手生成的黑人纳粹军队图像。如果基于已经存在的真实数据继续训练,生成的数据可能会进一步放大这种误差与偏见。
可以说,AI始于数据,也困于数据。在高质量数据受到版权压力,合成数据面临质量争议的情况下,大模型训练将面临更多的考验。
不过好在大模型企业仍然对合成数据的应用前景表示乐观。据了解,OpenAI和Anthropic的研究人员正试图通过创建所谓的更高质量的合成数据来避免这些问题。在最近的一次采访中,Anthropic的首席科学家JaredKaplan表示,某些类型的合成数据可能会有所帮助。
未来,大模型的数据困境将会从何突破,我们将会持续关注。
本文来自微信公众号:乌鸦智能说(ID:wuyazhinengshuo),作者:Nancy