
从ChatGPT引爆那一刻起,AI行业的竞争从来不仅是技术的竞争,也是一场资源的竞争。
在硅谷,风险投资家在考量是否要投资一个AI项目团队时,一个核心的考量就是该团队是否有渠道获取必要的GPU芯片资源。只有抢占到”硅资源“才意味你有参与AI大模型竞争的入场券。
今年以来,在AI大佬的讲话里,都有一个共同的主题:缺电。马斯克预计在芯片短缺缓解后,马上将会出现电力短缺。OpenAI CEO Sam Altman也预计,AI 行业正在走向能源危机,未来 AI 技术发展将高度依赖于能源。英伟达创始人黄仁勋表示,“AI的尽头是光伏和储能,不要光想着算力。”
从哲学角度看,智力级别的提升首先需要能量级别的提升,我们将经历从缺硅到缺电的转变。Sam Altman表示,AI的第一性原理,最重要的就是能源和智能转换率的问题。而人工智能是能源的无底洞,在可控核聚变实现以前,AI可能将被能源卡脖子。
这一切的关键因素是因为Transformer本质上不是一个能效很高的算法。
二次复杂度的噩梦
在技术领域,权衡是一个永恒的主题,尤其是在设计和开发先进的AI模型时。技术的实现总需要去适配当前的现状。
目前ChatGPT、Gemini、Claude等先进的人工智能模型,都是建立在Transformer架构之上的。它们的强大之处,在于能够通过串联多个Transformer块,捕捉和理解文本数据中的复杂模式和关系。
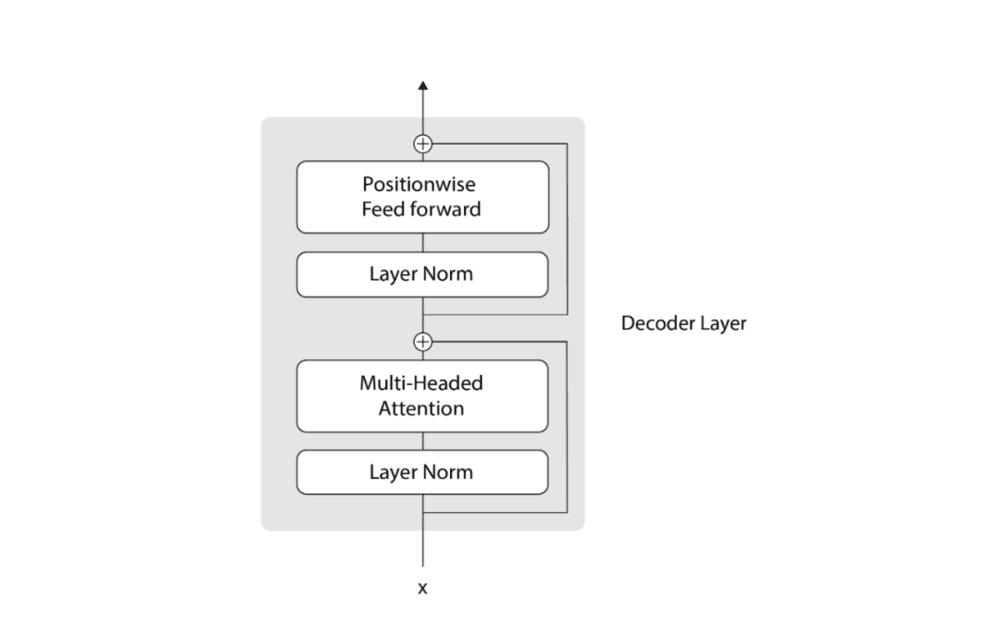
上图是其中一个Transformer块,我们可以看出其中包含两部分:
自注意力层算子(Self-Attention)
前馈神经网络(FFN)
自注意力机制可以用于处理输入序列中不同单词之间的关系,而前馈层则有助于从数据中提取关键特征和关系。
那么为什么说Transformer不是一个能效很高的算法呢?下面我们来分析下Transformer中这两部分的计算分布。
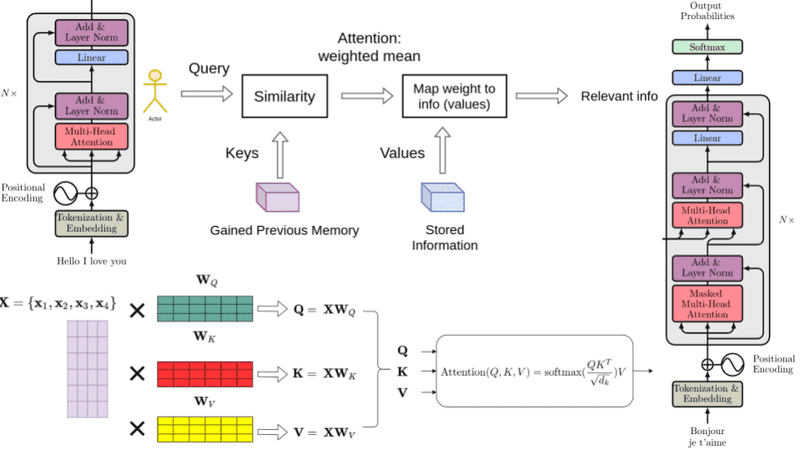
Self-Attention(MHA)
如上图所示,在自注意力模块中,我们首先进行的是查询(Query, Q)、键(Key, K)和值(Value, V)的投影变换,这一步的计算量为(3 x s(hd)2),其中(s)代表序列长度,(h)代表头的数量,(d)代表隐状态的维度。这一步骤的目的是将输入序列转换为更适合进行注意力计算的形式。
接下来是注意力操作本身,即通过计算Q和K的点积,然后应用Softmax函数来获取权重分布,最后这些权重被用于加权求和V。这部分的计算量为(h x (s2d+s2d) + s x (hd)2)。这一步骤是自注意力机制的核心,它允许模型在处理每个序列元素时,都能够考虑到序列中的所有其他元素,从而捕获序列内的长距离依赖关系。
综上,自注意力SA模块的总计算量为(4 x s x h2 x d2 + 2 x s2 x h x d)。
FFN
其次是FFN模块,在FFN中对每个位置的表示进行独立的变换,其计算量为(8 x s x h2 x d2)。FFN模块包含两次线性变换和一个非线性激活函数,通常用于增加模型的表达能力。
计算量分析
当我们比较SA和FFN两个模块的计算量时,可以发现,当序列长度(s)非常小时,Transformer快的计算量主要在FFN模块中。
而随着序列长度(s)的增加,SA模块的计算量增长速度会超过FFN模块,特别是当序列长度(s)超过隐长度(d)的两倍时,Transformer的总体计算量与序列长度呈二次关系增长。这意味着在处理长序列时,Transformer模型的计算资源消耗会迅速增加,从而可能导致计算资源的饱和。
可以说,Transformer 模型的二次复杂度在一定程度上可以说是其耗电的主要原因之一,特别是在处理长序列时。通俗地说,如果输入序列加倍,处理它的成本就会增加四倍。
实际上,对于较短的序列,这并不是什么大问题,但对于较长的序列,计算和内存需求都会急剧上升。
作为参考,如果我们看一下像 LLaMa-2 7B 或 Mistral-7B 这样的流行模型,尽管它们尺寸很小,但对于 256k 标记(192k 字)的序列,它们分别需要 128GB 和 32GB,尽管后者使用Grouped-Query Attention。
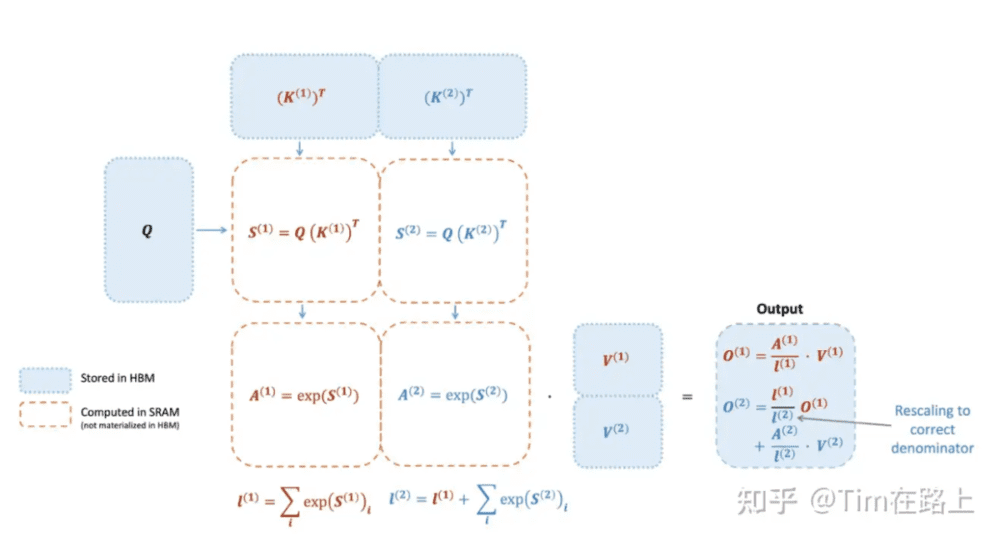
当前存在一些针对Attention自身的计算性能优化主要包括软硬一体的计算一致性优化和KV Cache的优化方式。
其中Flash Attention是一种硬件优化的注意力机制,利用更高速的上层存储计算单元,减少对低速下层存储器的访问次数,通过Tiling和Recomputation提高效率。Group Query Attention和MQA则通过分组查询向量和优化键值数量来减少计算量。
尽管这些方法提升了性能,但未能解决Transformer模型O(N2)复杂度问题,如果要继续提升性能,可能需要新的模型架构或算法。
因此,多年来,Transformer 由于成本过高而无法扩展到更大的序列长度,使得其一直带有“二次障碍”。
破局之混合体
在算法层面上Transformer模型变化基本上已经收敛很多,在与原生的Transformer相比,主要的变化包括:
架构:
使用RMSnorm代替LayerNorm
使用旋转位置嵌入代替绝对或相对位置嵌入
不使用偏置向量
使用SwiGLU激活函数代替ReLU
训练方法:
使用AdamW优化器代替Adam
采用稍微不同的学习率调度
除此以外为了克服“二次障碍”的缺陷,研究者们开发出了很多注意力机制的高效变体,但这往往以牺牲其有效性特为代价。到目前为止,这些变体都还没有被证明能在不同领域发挥有效作用。
可以说近六年来,没有什么能打败 Transformer,它是所有生成式 AI 模型的核心。许多人一直试图推翻它,但都失败了。
然而由于当前的能源问题并未解决,即可控核聚变不能短期实现,而AI大模型的计算的需求还在以指数形式的快速上升,能源问题被摆上日程。
例如,前一段时间还有媒体报道,微软为GPT-6训练搭建10万个H100训练集群,以当前美国的电网能力,一旦在同一个州的部署超过10万个H100 GPU,那么整个电网将被搞崩。
因为只要计算规模呈二次方增长,我们就会不断遇到阻塞,因为世界电网还没有为这种计算做好准备。微软为 OpenAI 建造价值 1000 亿美元的数据中心是有原因的。
这就需要我们通过权衡的方式来缓解这种现状,而就在最近,一个名为Jamba的架构似乎打破了这一局面。我想Jamba宗旨不是要取代Transformer,而是要创造混合体,在这中间找到一种平衡。
Jamba是世界上第一个基于Mamba的生产级模型。通过用传统Transformer架构的元素增强Mamba结构化状态空间模型(SSM)技术,Jamba弥补了纯SSM模型的固有局限性。提供256K上下文窗口。
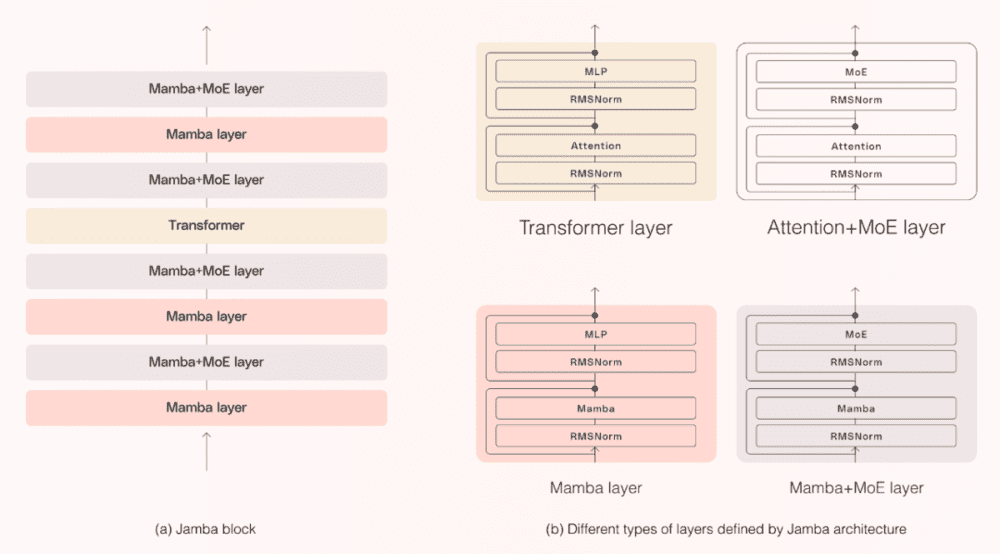
如上图所示,Jamba架构引入Jamba块。它是Mamba层和Transformer的组合,两者之间还有专家混合(MoE)模块。Jamba 52B使用8层的Jamba模块,Attention和Mamba的比例是1:7 ,中间有MoE层。MoE Layers有16个专家,每个Token有i2个活跃专家。
Jamba 并不是试图在质量方面实现代际飞跃,而是证明混合架构与 Transformer 一样好,而且花费价格便宜得多。
Jamba & Manba的优势
1. 可扩展符合Scaling Law
Mamba是一种基于状态空间模型的循环神经网络,被提议作为Transformer的替代架构,而且是遵从Scaling Law缩放法则。
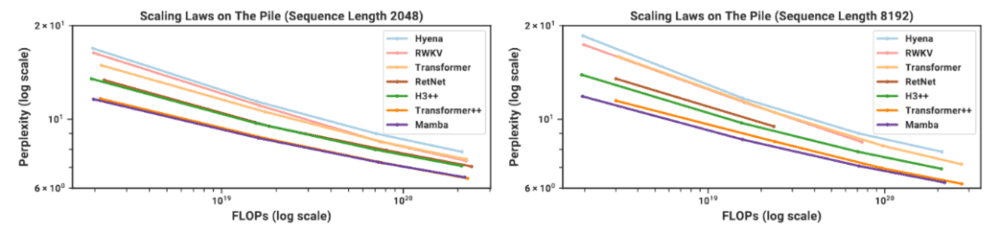
如上图所示,Mamba缩放与Llama(Transformer++)、之前的状态空间模型(S3++)、卷积(Hyena)和受Transformer启发的RNN(RWKV)相比的图示。
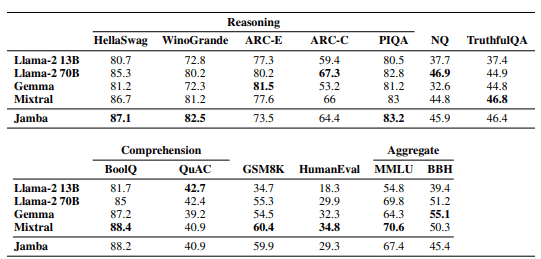
而且当前Jamba训练的52B参数MOE Mamba-Transformer混合体,据推断,该模型有12B个主动参数,且其基准分数与Llama-2 70B和Mixtral相当,如上图所示。
2. 高效的推理
Jamba或Manba或RNN的优点之一,是存储上下文长度所需的内存是恒定的,因为只需要存储 SSM 和卷积层的过去状态,而对于 Transformer 而言,它会线性增长。
破局之Moe
在人工智能等领域,一切都变化得如此之快,因此识别出哪些东西是至关重要的。模型会不断更新,模型也会不断改进,但有些突破会变得无处不在。其中之一就是混合专家(MoE)的概念。
MoE 已经变得如此普遍,以至于现在很难找到一个不是 MoE 的新的大型语言模型。GPT -4、Gemini 1.5、Mixtral 8x7B或Jamba都是 MoE,甚至有传言称 GPT-4 也是 MoE。
我们可以简单理解Moe架构将模型“分解”为更小的模型,称为专家。因此,在推理过程中,会选择一定数量的专家来“回答”该预测。
事实上,Moe它不仅计算效率更高,甚至还可以提高质量。通过提高质量来降低成本,这在技术领域是极其罕见的景象。
例如,由于实质上我们可以让大多数专家保持沉默,因此计算成本会成比例下降(如果您激活 8 个专家中的 2 个,则成本平均会下降 4倍)。
许多人不知道,神经网络实际上对于它们所做的大多数预测来说都太大了。尽管每次预测都要运行整个网络,但实际上只有很小一部分模型能够发挥作用。
例如,ChatGPT,尽管它被迫运行整个庞大的网络来预测每一个新词,这需要巨大的计算工作量,但只有网络中非常特定的部分会被激活,以帮助预测新词。
换句话说,它们进行了大量不必要的计算,使得我们更大的 LLM 成为世界上最低效和最耗能的系统之一。
如今,以LLM为主导的人工智能行业消耗的电力比整个小国还要多。
但除了不受控制的消耗之外,针对每个预测运行整个模型也会对性能产生重要影响。
尽管最近取得了成功,MoE(Mixture of Experts)架构仍然面临两个问题:知识混合和知识冗余。
知识混合问题出现在专家数量有限,每个专家需要处理广泛的知识领域时。这种情况下,专家们的知识涉及面过于广泛,无法深入研究特定领域。
而知识冗余则是指在MoE模型中,不同专家学习的知识过于相似,这与模型设计初衷相违背。这里我们就不做过多地展开, 后面我们会专门出一篇文章来详解下Moe。
为了解决这些问题,Deepseek提出了一种新型的MoE架构。
Deepseek提出这些修改的目的是为了解决传统MoE模型中的挑战,并进一步提升模型的性能和效率。
首先,增加专家数量的修改旨在引入更多的专业化,以应对更广泛和复杂的主题。通过增加专家数量,可以降低每个专家负责的主题数量,使得每个专家更专注于其领域,从而提高模型在各个领域的专业性和准确性。此外,增加专家数量也会增加可能的专家组合数量,从而提高了模型对不同输入的适应能力和泛化能力。
其次,引入共享专家的修改旨在解决过度专业化可能导致的问题。尽管增加专家数量可以提高模型的专业性,但过于专业化的专家可能无法涵盖足够广泛的主题,从而限制了模型的应用范围。通过引入共享专家,即为每个预测引入一组神经元,模型可以在保持广泛知识的同时,确保在每个预测中都能涉及到适当的专业领域。
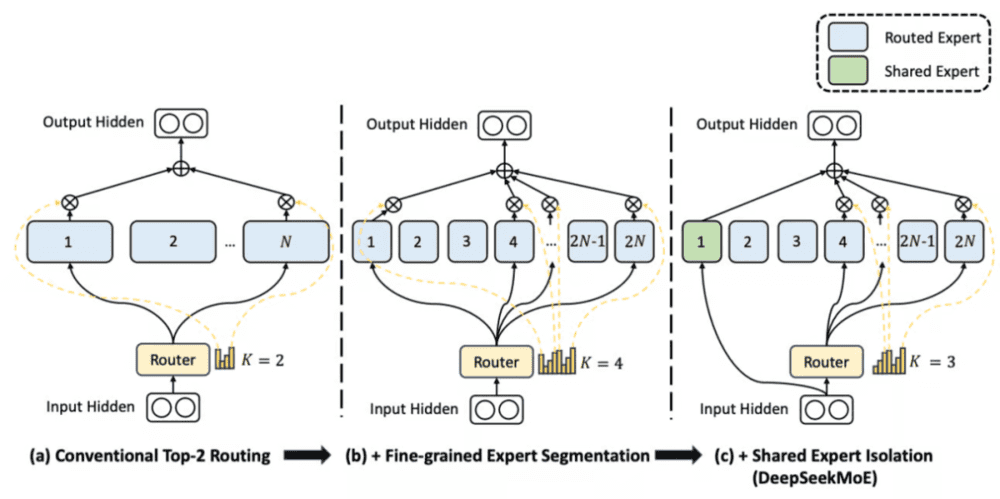
这些修改的结果清楚地展示了它们的前景和潜力。DeepSeekMoE 16B在一系列基准测试中表现出与类似模型相媲美甚至超越的性能,而其计算成本仅约为原先的40%左右。将DeepSeekMoE扩展至145B参数后,初步结果显示,它不仅在性能上保持了优势,还能与更大的密集模型相媲美,同时大幅降低了计算成本。
因此,这些修改为改进MoE模型的性能和效率打开了新的可能性,并且在当前的研究领域中备受关注和重视。
破局之更好的数据质量
最近Llama3的发布,更强调了数据工程的重要,其模型架构不变,更多的数据量和更高数据质量能够带来明显模型效果提升。
Llama3 与Llama2的模型结构的区别
Llama3与Llama2的模型架构完全相同,只是model的一些配置(主要是维度)有些不同,Llama2推理的工程基本可以无缝支持Llama3。在meta官方的代码库,模型计算部分的代码是一模一样的,也就是主干decoder only,用到了RoPE、SwiGLU、GQA等具体技术。
Llama3-8B与Llama2-7B的模型具体差别,主要在于:
vocab_size:32000 -> 128256:词汇表的扩大导致了embedding参数的增加。计算公式为(128256-32000)* 4096 * 2 字节,加上最后一层lm_head的输出维度增加,共计带来模型增大1504MB。
max_position_embeddings:4096 -> 8192:上下文窗口大小扩大,训练时输入的序列长度增加,推理时支持的序列长度也相应增加,但在计算上没有实际差别。
num_key_value_heads:32 -> 8:使用了GQA,因此key、value要复制4份。参数量会下降,K_proj、V_proj的参数矩阵会减少为Llama2-7B的1/4,总计减少1536MB。
intermediate_size:11008 -> 14336:FFN时的中间维度变化,但计算模式保持不变。参数量增加:32 * 4096 * (14336 - 11008) * 3 * 2 / 1024 / 1024 字节,总计增加2496MB。
综上所述,通过以上几个设置和维度的变化,最终导致模型增大2464MB,这也是从7B到8B的变化。总体而言,模型的基本计算模式并未改变。
Llama3与Llama2的数据工程的区别
效果提升主要是由于数据工程方面的改进,具体体现在以下几个方面:
数据量增加:
预训练阶段,Llama3使用了超过15万亿个token,是Llama2的7倍多。其中,代码相关的数据是Llama2的4倍多。这样的大规模数据量能够帮助模型更好地学习语言特征和语境。
Fine-tuning阶段的数据也非常丰富,包括来自公开获取的instruction datasets以及超过1千万个人工标注的样本。
数据质量提升:
在预训练阶段,为了确保模型在最高质量的数据上进行训练,开发了一系列数据过滤pipeline。这些管道包括使用启发式过滤器、NSFW过滤器、语义重复数据删除方法和文本分类器来预测数据质量。
在Instruction fine-tuning阶段,重视数据质量同样至关重要。通过对数据的精心整理以及对人类注释者提供的注释进行多轮质量检查,确保了数据质量的提升。
数据混合比例的探索:
进行了大量实验,评估在最终预训练数据集中混合不同来源数据的最佳方法。这种数据混合比例的探索可以帮助模型更好地泛化到不同领域和语境中,提升模型的适用性和性能。
综上所述,数据工程的改进包括数据量的增加、数据质量的提升以及对数据混合比例的探索,这些方面的改进共同促成了模型性能的提升。
从上面我们可以看出,数据工程和数据的质量,在大模型的训练中绝对占非常重要的比重。
总结
如今AI大模型所主导的人工智能行业其消耗的电力比整个小国还要多,这也是未来实现AGI发展必须要考虑的一点。
鉴于随着序列长度的增加,Transformer本身的“二次噩梦”问题,我倾向认为,未来大模型算法可能需要注意的几个点:
通过考虑折中的混合体来减少能源的消耗,提升算法本身的效能。例如Jamba等类的模型,通过增强Mamba结构化状态空间模型(SSM)技术和Transformer的混合,证明与 Transformer 一样好,而且花费价格便宜得多。
通过Moe混合专家的技术,将模型“分解”为更小的模型,在推理过程中,会选择一定数量的专家来“回答”该预测,从而减少大量的资源消耗。
通过数据工程提升数据的质量,实验已经证明通过少了但质量较高的数据,可以实现更大规模数据和模型的效果,从而减少模型训练中的资源浪费。
本文来自微信公众号:Tim在路上(ID:CNSF-2016),作者:Pulsar planet