
本文来自微信公众号:AINLPer(ID:gh_895a8687a10f),作者:ShuYini,原文标题:《Google | 提出Infini-Transformer架构,可让LLMs处理无限长上下文,内存节约114倍!》,题图来自:视觉中国
引言
为解决大模型(LLMs)在处理超长输入序列时遇到的内存限制问题,本文作者提出了一种新型架构:Infini-Transformer,它可以在有限内存条件下,让基于Transformer的大语言模型(LLMs)高效处理无限长的输入序列。实验结果表明:Infini-Transformer在长上下文语言建模任务上超越了基线模型,内存最高可节约114倍。

https://arxiv.org/pdf/2404.07143.pdf
背景介绍
对于人工智能来说,内存资源是神经网络模型进行高效计算的必要条件。然而,由于Transformer中的注意力机制在内存占用和计算时间上都表现出二次复杂度,所以基于Transformer的大模型就更加依赖内存资源。
例如,对于批量大小为 512、上下文长度为 2048 的 500B 模型,注意力键值(KV)状态的内存占用为 3TB。这意味着对于标准的Transformer架构大模型,要想支持越长的上下文,那么需要的内存成本也将越高。既要降低内存成本,且要让LLMs能够支持更长的上下文,这无疑是一项非常具有挑战的任务。
面对超长序列,相比注意力机制,内存压缩技术更具扩展性。内存压缩不使用随输入序列长度而增长的数组,而是在有限的内存资源上,维护固定数量的参数来进行信息的存储和回调。然而,目前的LLMs尚未有一种有效、实用的内存压缩技术,可以在简单性与质量之间取得平衡。
基于以上背景,本文作者提出了一种新架构:Infini-Transformer,能够让基于Transformer的大模型在有限内存、计算资源的条件下,处理无限长的上下文输入。
Infini-Transformer模型
下图是本文Infini-Transformer模型、Transformer-XL模型的对比图。与Transformer-XL类似,Infini-Transformer处理的是一系列片段。即在每个片段内计算standard causal点积attention context(注意力上下文)。因此,点积注意力计算在某种意义上是局部的,它覆盖了索引为 S 的当前片段的总共 N 个标记。
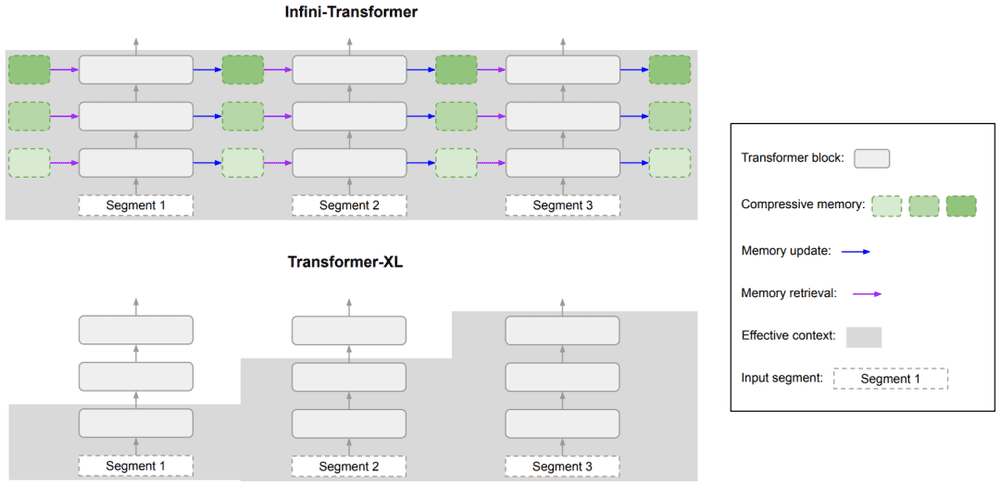
然而,局部注意力在处理下一个片段时会丢弃前一个片段的注意力状态。在Infini-Transformer中,并没有忽略旧的键值(KV)注意力状态,而是通过内存压缩技术重新使用它们来保持整个上下文历史。
因此,Infini-Transformer的每个注意力层都具有全局压缩和局部细粒度状态,这就是前面提到的无限注意力(Infini-attention)。
Infini-attention
Infini-Transformer模型的关键组成部分为:Infini-attention,这是一种新型attention技术,如下图所示。它将计算局部和全局上下文状态,并将它们组合到一块作为输出。与多头注意力(MHA)类似,除了点积注意力之外,它还为每个注意力层维护H个并行压缩内存(H 是注意力头的数量)。
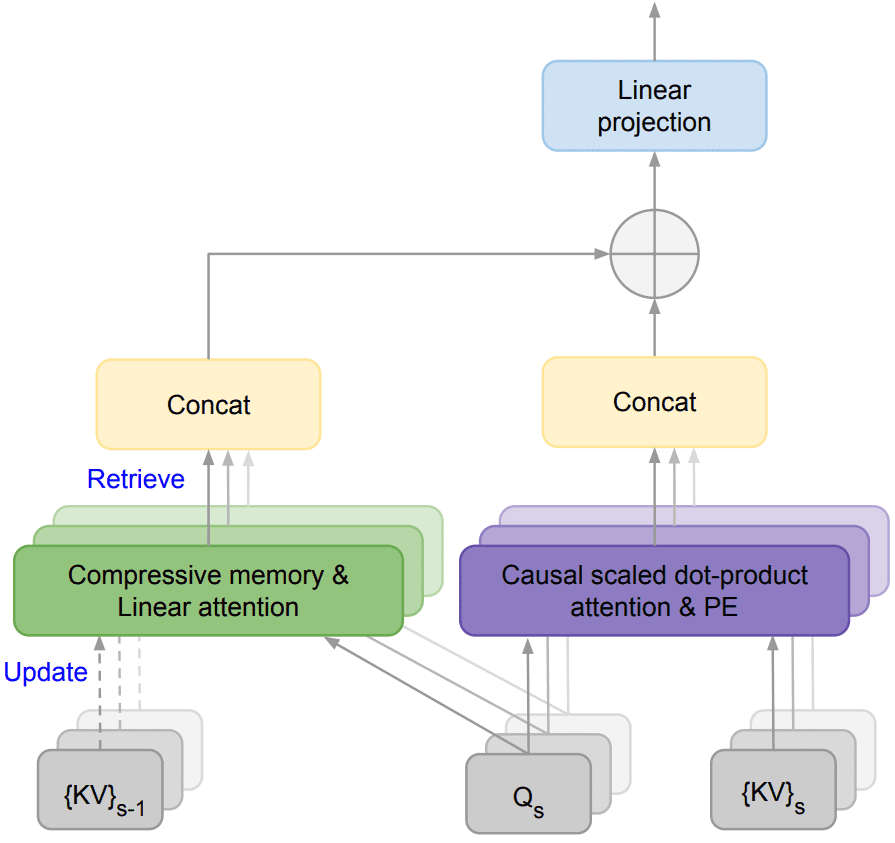
其中:
“缩放点积Attention”在Infini-attention机制中发挥了重要作用。Scaled Dot-product Attention是多头注意力(Multi-head Attention, MHA)的一个变种,它在处理序列数据时能够有效地捕捉序列中的依赖关系。对于MHA,本文并行地为序列中的每个元素计算H个注意力上下文向量,将它们沿着第二维拼接起来,最后将拼接后的向量投影到模型空间以获得注意力输出。
“Compressive Memory”它通过固定数量的参数关联矩阵来存储和检索信息,当处理新的输入序列时,模型会更新关联矩阵中的参数,以存储当前序列的信息。更新过程通常涉及到将新的键值对(KV)与记忆矩阵中的现有参数进行某种形式的结合。在处理后续序列时,模型会利用查询向量(Query)来检索关联矩阵中的信息,从而获取之前序列的上下文信息。
实验结果
如下图所示,在PG19和Arxiv-math数据集上,Infini-attention在长上下文语言建模任务上取得了优于基线模型的性能,同时在内存大小上实现了114倍的压缩比。

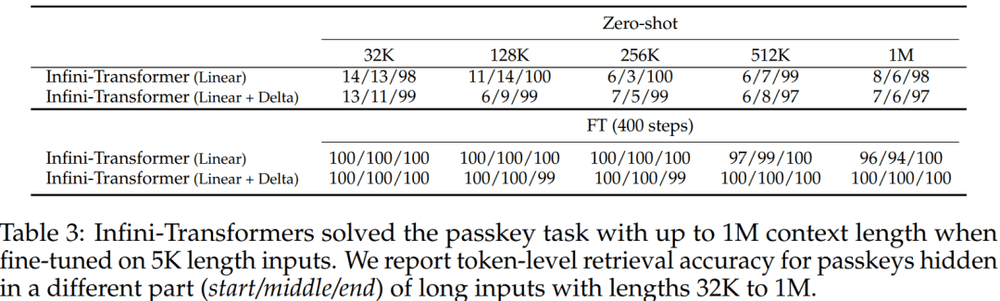
如下图所示,在1M序列长度的密钥检索任务中,Infini-attention在仅使用5K长度输入进行微调后,成功解决了任务,展示了其在处理极长输入序列时的能力。
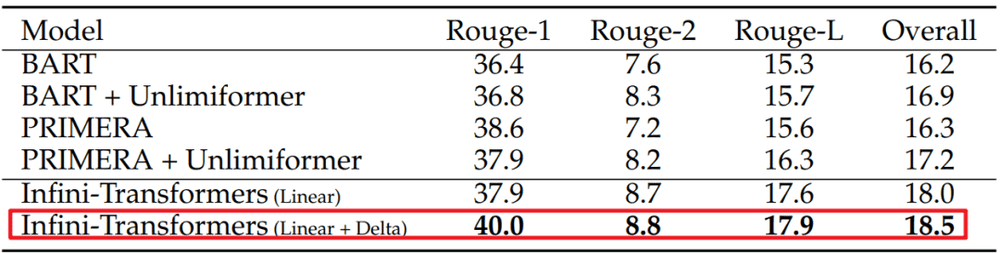
如下图,在500K长度的书籍摘要任务中,Infini-attention通过持续的预训练和任务微调,达到了SOTA,证明了其在长文本摘要任务上的性能。
本文来自微信公众号:AINLPer(ID:gh_895a8687a10f),作者:ShuYini