
AIGC的迭代正以指数级的速度增长。
Gemini刚发布不久,便迅速被OpenAI的Sora夺去了光芒。显然,与详尽的技术对比报告和性能指标相比,大众对Sora提供的酷炫逼真的视觉效果更为关注。有爱好者尝试使用Gemini来分析Sora生成视频的结果,这种做法宛如用最强之矛去攻击最坚固之盾。
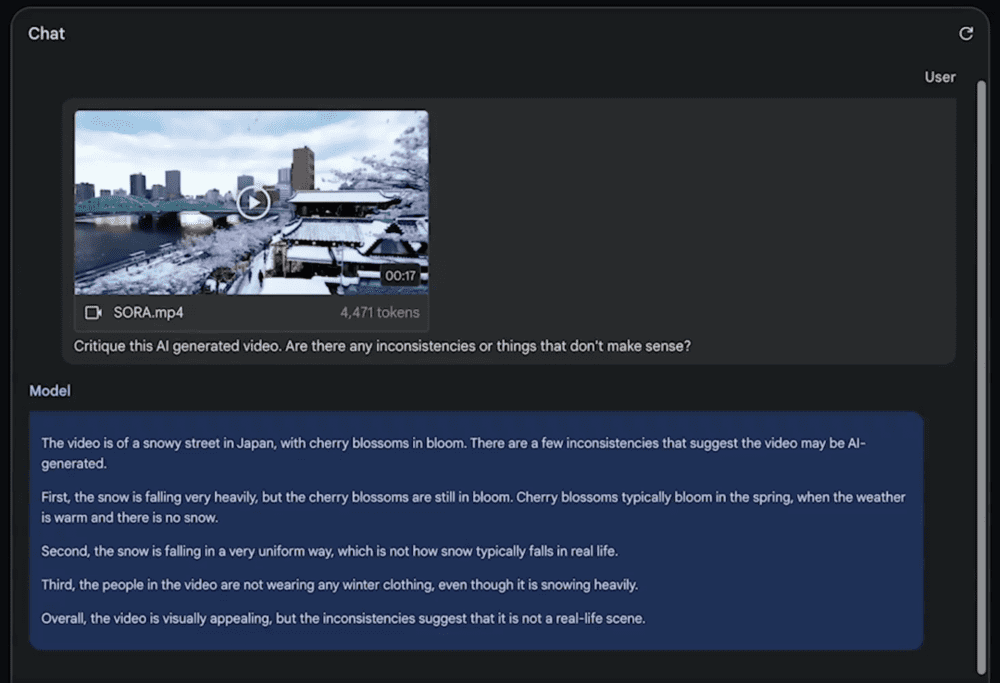
测试结果显示,Gemini 1.5不仅准确理解了视频的基本内容,还指出了生成视频中的一些不符合常理的细节。用魔法对抗魔法,尽管Sora的生成效果确实令人惊艳,但还是很容易就被Gemini找到了漏洞,与众人所期待的“物理引擎”水平之间还存在显著的差距。
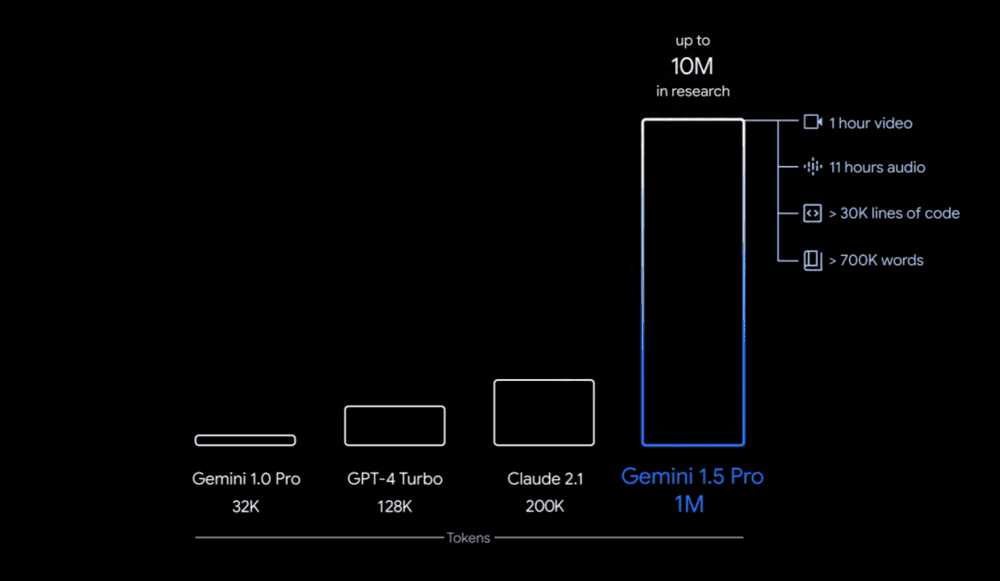
相比Sora的博人眼球,Gemini发布的五十多页技术报告更值得一读。报告详细介绍了长上下文和多模态测试,这些测试的许多方面将对AIGC应用的未来发展产生深远影响。Gemini支持高达1000万token的超长上下文和强大的多模态能力,这意味着利用Gemini能够与整本书籍、庞大的文档集、数百个文件组成的数十万行代码库、完整电影、一整个播客系列等进行交互。
一、大海捞针:长上下文究竟意味着什么?
Gemini 1.5的亮点在于其长上下文处理能力,特别是在处理庞大数据集时的强大搜索功能。技术报告中的“needle-in-a-haystack”(大海捞针)测试就精彩地展示了这一点。在这项测试中,模型需要从一个长序列中检索到特定的文本片段。通过在不同位置插入文本(即“针”)并要求模型找到这些“针”,这测试了模型在不同上下文长度下的信息检索能力。
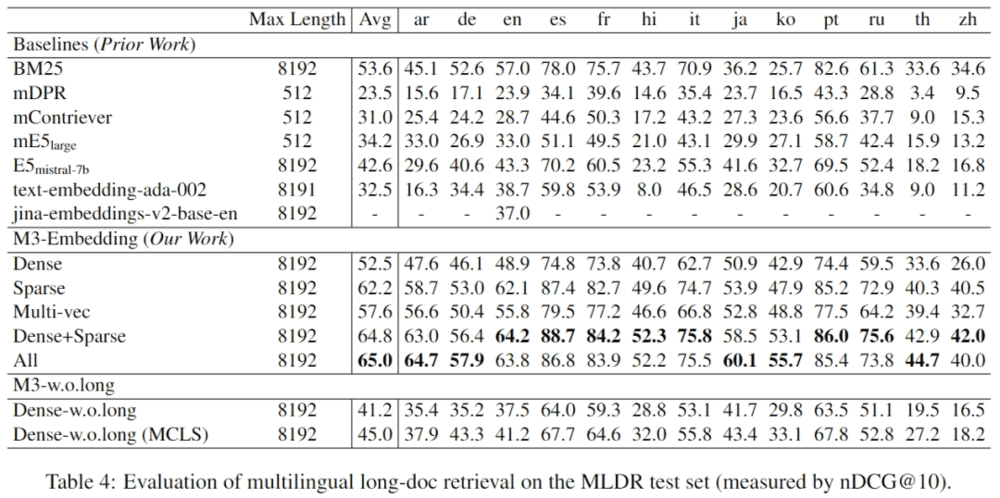
Gemini 1.5 Pro在长达530k token的文档中实现了100%的准确检索,在长达1M token的文档中保持了超过99.7%的检索准确率。此外,即使在文档长度达到10M tokens时,模型仍能以99.2%的准确率找到并提取信息。这一结果不仅证明了Gemini 1.5 Pro处理长文档的能力,还展示了其在极端长上下文中的稳定性和准确性。
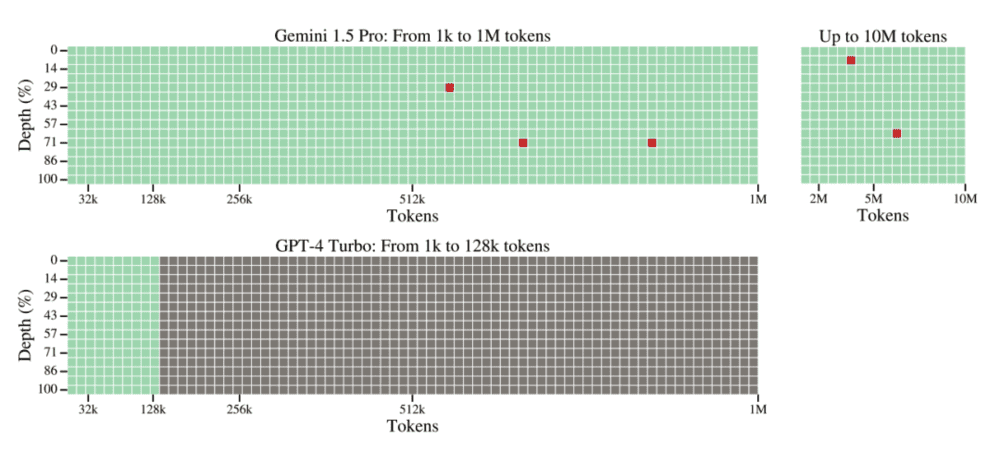
图片来源 https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
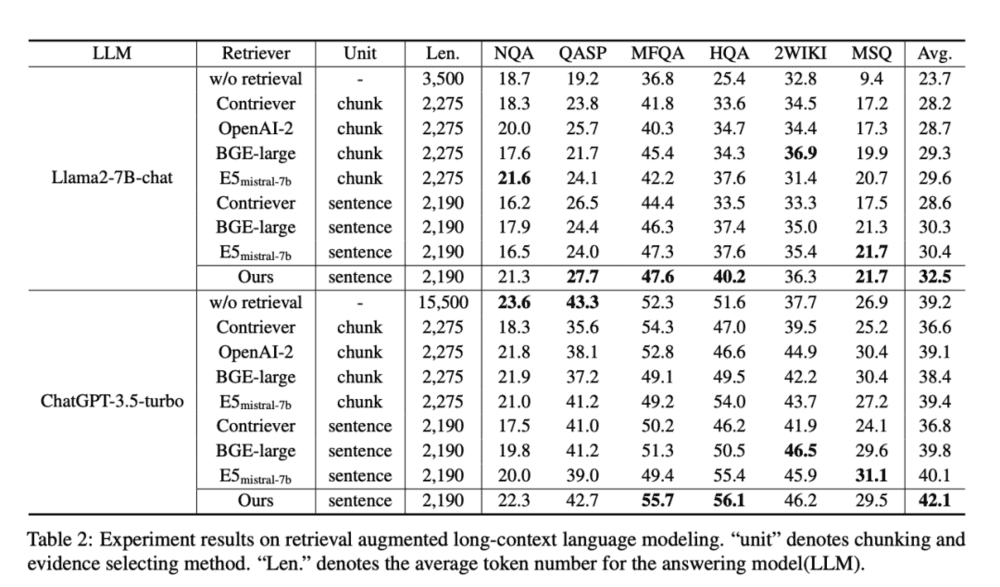
尽管GPT-4在小于128k的上下文中表现也同样出色,但Gemini在处理更长上下文的能力方面有了显著扩展。在长文档QA测试中,直接将一本710K token的书作为上下文输入给Gemini,结果远胜于0-shot查询和只召回4k token的标准RAG查询。
人类评估和AutoAIS评估的结果都显示,Gemini模型对原材料有很好的理解。相反,在0-shot设置下,大型模型通常选择避免回答问题,以减少可能出现的幻觉和非事实性断言。对于RAG而言,我们观察到,特定的问题集通常需要解决指代表达式(例如,“兄弟”“主角”),这需要跨越长距离依赖进行推理,而这些依赖通常不容易通过RAG的检索技术捕获。
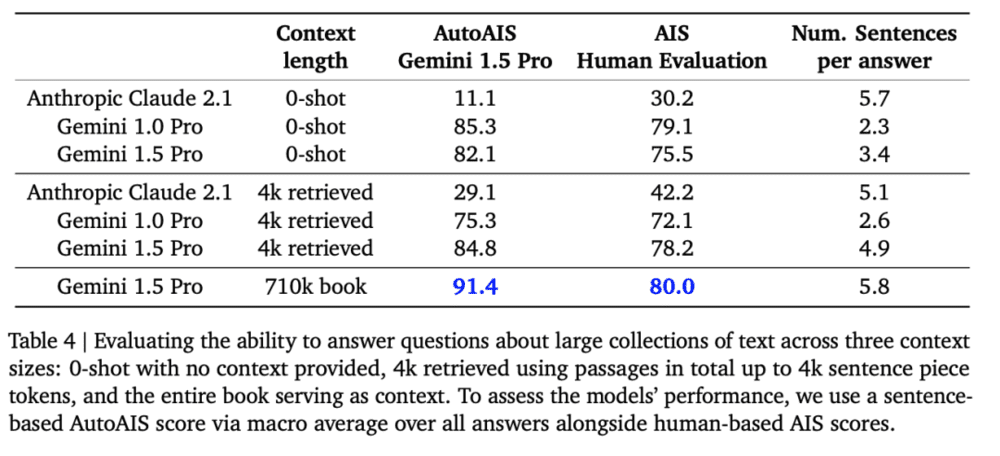
图片来源 https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
由于Gemini在处理长上下文方面表现出色,有人甚至高喊“RAG已死”。爱丁堡大学博士符尧在评价Gemini 1.5 Pro的帖子中写道:“一个拥有1000万token上下文窗口的大模型击败了RAG。大语言模型已经是非常强大的检索器,那么为什么还要花时间构建一个弱小的检索器,并将时间花在解决分块、嵌入和索引问题上呢?”

二、RAG:中点还是终点?
RAG技术,即检索增强生成(Retrieval-Augmented Generation),是一种利用外部来源获取的事实来增强生成式人工智能模型准确性和可靠性的技术。通常包括两个阶段:检索上下文相关信息和使用检索到的知识指导生成过程。通过从更多数据源添加背景信息,以及通过训练来补充大型语言模型(LLM)的原始知识库,检索增强生成能够提高搜索结果的相关性。
在过去的2023年,RAG技术取得了快速发展,也带火了向量数据库。搜索增强能够有效解决幻觉、时效性差、专业领域知识不足等阻碍大模型应用的核心问题。一方面,搜索增强技术能有效提升模型性能,并且使大模型能够“外挂硬盘”,实现互联网实时信息+企业完整知识库的“全知”。这一技术不仅提高了生成式模型的准确性和可靠性,还使其能够更好地理解上下文,并将检索到的知识融入到生成过程中,从而生成更加贴合实际需求的文本。
随着大型模型对上下文长度的支持加强以及从长上下文检索信息的能力逐渐增强,我们不禁要问:RAG技术是否已经过时,成为人工智能生成与检索应用中的过客?在笔者看来,RAG技术的发展才刚刚起步,并且随着大型模型在处理长上下文和遵循指令方面的能力不断提升,RAG技术将持续发展迭代。单纯依赖大型模型并不能完全满足非结构化数据处理的4V特性:
1. Velocity(速度):根据目前的测试反馈,Gemini在回答36万个上下文时需要约30秒,并且查询时间随着token数量呈非线性上升。尽管我们对算力和模型的发展都持乐观态度,但要使长上下文实现秒级响应对于基于transformer的大型模型仍然是一个极具挑战性的目标。

2. Value(价值):尽管长上下文的大模型生成结果具有很高的质量,但是推理成本依然是落地的阻碍。例如,如果将上下文的窗口设定为1M,按照当前0.0015美元/1000 token的收费标准,一次请求就要花掉1.5美元。这样高昂的成本显然是无法实现日常使用的。
3.Volume(体量):1000万token相对于当前庞大的非结构化数据体量而言,依然是九牛一毛。目前还没有方式把整个Google搜索的索引数据扔进大模型。
4.Variety(多样性):实际的落地场景不仅包含了长文本、图片等非结构化数据,更包含了复杂的结构化数据,比如时间序列数据、图数据、代码的变更历史等等,处理这些数据依然需要足够高效的数据结构和检索算法。
三、RAG路在何方?
RAG已经被证明是一种解决大模型幻觉的有效方法,那么如何才能进一步提升RAG的实战效果?
1. 提升长上下文的理解能力
图片来源 https://arxiv.org/abs/2402.11573
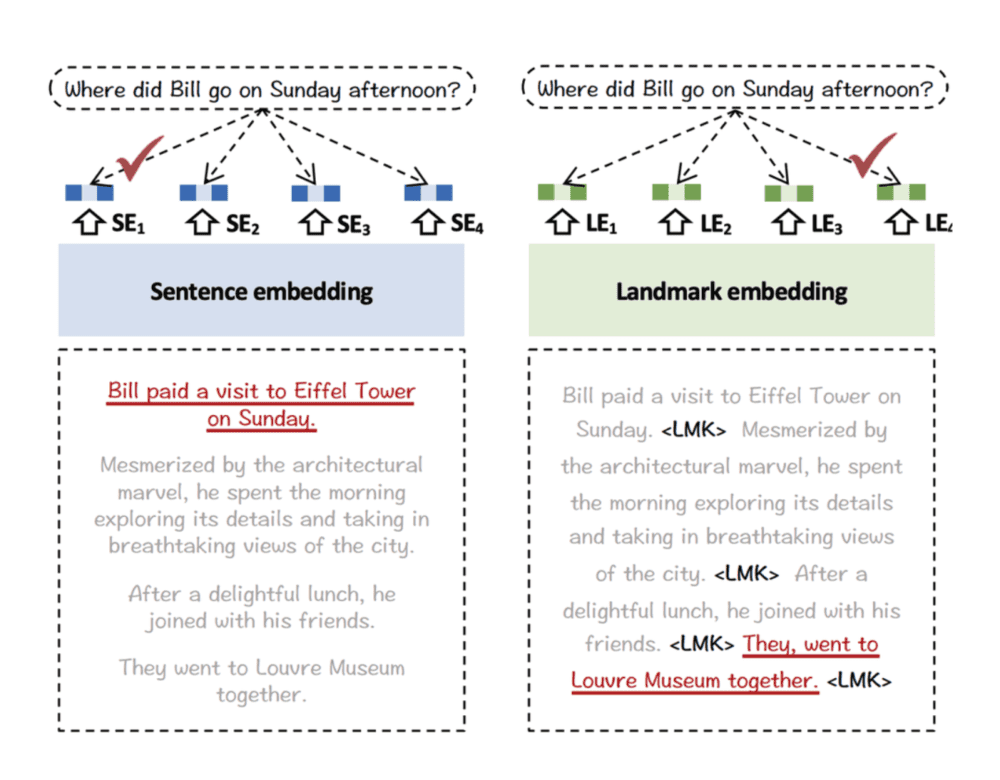
由于嵌入模型通常较小,上下文窗口有限,传统的RAG通常依赖分块对数据进行切分。这会导致上下文信息的丢失,例如一些代词的信息无法被连贯地理解。
举例来说明,某个对话中提到Bill周日去了埃菲尔铁塔,之后又跟朋友一起去了卢浮宫。当我们进行传统的提问,例如询问“Bill周日下午去了哪里?”时,由于上下文信息被分割成多个分块,可能会导致搜索到的信息仅包含Bill周日去了埃菲尔铁塔,从而形成错误的结论。在这种情况下,由于上下文被切分,系统无法正确理解代词“去了哪里”的指代对象,从而导致了错误的结果。
近期,基于大型模型实现的嵌入逐渐成为主流。在Huggingface MTEB LeaderBoard中,效果最好的嵌入基本上都由大型模型霸榜。这一趋势的一个副产品是嵌入的上下文窗口也逐渐提升,例如SRF-Embedding-Mistral和GritLM7B已经支持32k的长上下文,这意味着嵌入本身处理长上下文的能力也得到了大幅提升。
最近发布的BGE Landmark embedding的论文也阐述了一种利用长上下文解决信息不完整检索的方法。通过引入无分块的检索方法,Landmark embedding能够更好地保证上下文的连贯性,并通过在训练时引入位置感知函数来有限感知连续信息段中最后一个句子,保证嵌入依然具备与Sentence Embedding相近的细节。这种方法大幅提升了长上下文RAG的精度。
图片来源 https://arxiv.org/abs/2402.11573
2. 利用多路召回提升搜索质量
要提升RAG的回复质量,关键在于能够检索到高质量的内容。数据清理、结构化信息提取以及多路混合查询,都是提高搜索质量的有效手段。最新的研究表明,相比稠密向量模型,Splade这类稀疏向量模型在域外知识搜索性能、关键词感知能力以及可解释方面的表现更佳。
最近开源的BGE_M3模型能够在同一模型中生成稀疏、稠密以及类似于Colbert的Token多向量,通过将不同类型的向量多路召回并结合大型模型进行排名,可以显著提高检索效果。这种混合查询的方法也被向量数据库厂商广泛接受,即将发布的Milvus 2.4版本也即将支持稠密和稀疏向量的混合查询。
图片来源https://arxiv.org/pdf/2402.03216.pdf
3. 使用复杂策略提升RAG能力
图片来源https://towardsdatascience.com/12-rag-pain-points-and-proposed-solutions-43709939a28c
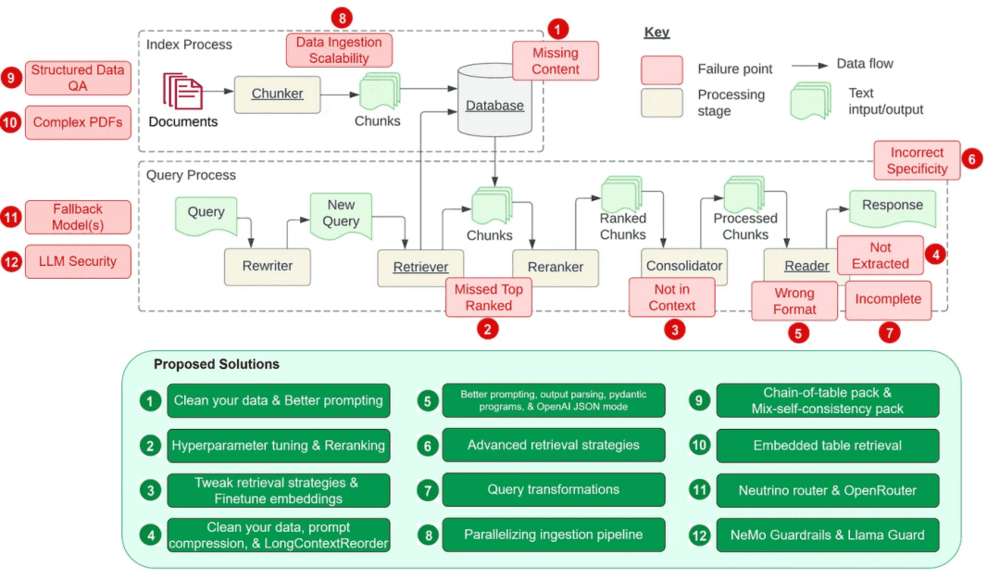
开发大模型应用不仅面临算法挑战,还涉及复杂的工程问题。这要求开发者需要具备深入的算法知识及复杂系统设计和工程实践的能力。采用复杂策略,如查询改写、意图识别和实体检测等,不仅能够提升准确性,也显著加快了处理速度。即使是先进的Gemini 1.5模型,在进行Google的MMLU基准测试时也需调用32次才能达到90.0%的准确率,这显示出采用复杂工程策略以提升性能的必要性。
通过使用向量数据库和RAG,采取空间换时间的策略,RAG系统能更有效利用大型语言模型(LLM)的能力。这不仅可以用于生成答案,还可以执行分类、提取结构化数据、处理复杂PDF文档等任务,增强了RAG系统的多功能性,使其能适应更广泛的应用场景。
四、大内存的发展并不意味着硬盘的淘汰
大模型技术正在改变世界,但无法改变世界的运行规律。自冯诺依曼架构诞生之日起,存储器、计算器和外存分开,即使在单机内存已经达到TB级别的今天,SATA磁盘和闪存依然在不同应用场景下发挥着重要的价值。对于大模型而言,长期记忆的重要性也将持续存在。AI应用的开发者一直在追求查询质量和成本之间的完美平衡。当大型企业将生成式人工智能投入生产时,他们需要控制成本,同时保持最佳的响应质量。RAG技术和向量数据库依然是实现这一目标的重要工具。
本文来自微信公众号:硅基立场(ID:gh_1b4c629a6dbd),作者:栾小凡(Zilliz合伙人兼研发VP)