
本文来自微信公众号:芯东西 (ID:aichip001),作者:ZeR0,原文标题:《英伟达下“封杀令”:不准转译CUDA!国产GPU企业回应》,题图来自:视觉中国
兼容CUDA这条路,走不通了?
芯东西3月6日消息,据外媒报道,英伟达已禁止用转译层在其他GPU上跑CUDA软件。
自2021年以来,英伟达已在其在线列出的许可条款中,明文禁止使用转译层在其他硬件平台上运行基于CUDA的软件。软件工程师@Longhorn发现这项“禁令”已被添加到安装CUDA 11.6及更新版本包含的最终用户许可协议(EULA)中。
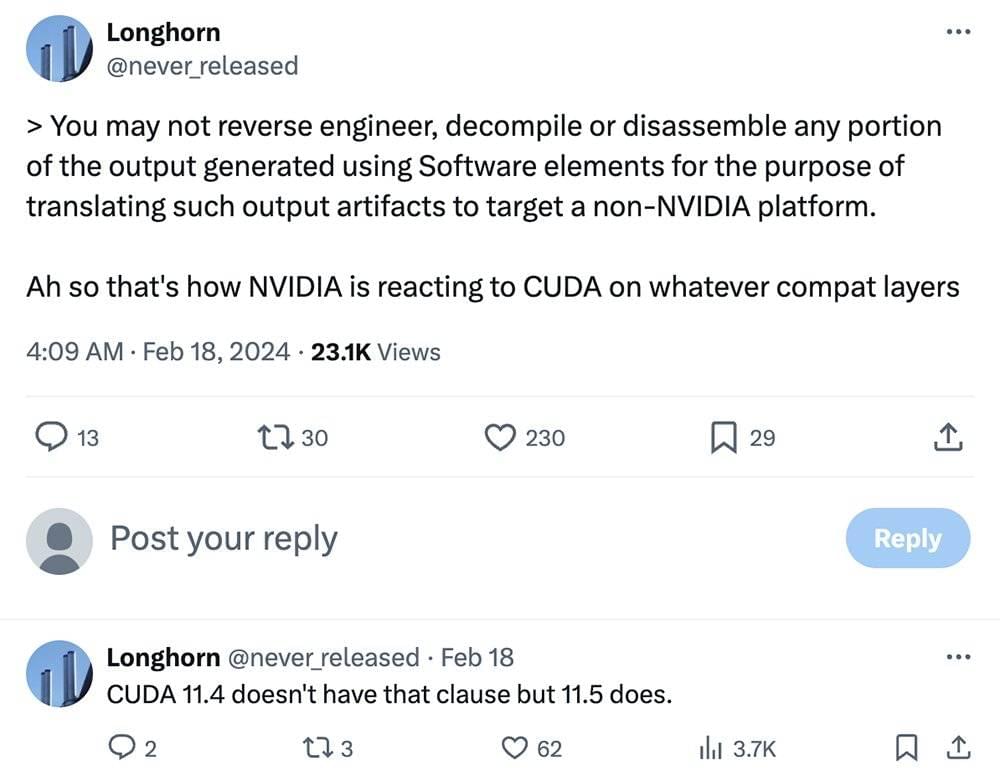
英伟达CUDA 11.6及更高版本的EULA有一条限制条款:“你不能逆向工程、反编译或反汇编使用此SDK生成的任何结果,并在非英伟达平台上进行转译。”

英伟达CUDA EULA相关限制条款截图
一石激起千层浪。GPU行业长期患有“CUDA依赖症”,英伟达多年来不断巩固的CUDA生态墙就像铜墙铁壁,是其他GPU新秀难以望其项背的关键壁垒。为了迎合市场需求,一些非英伟达的GPU平台选择兼容CUDA,以站在英伟达生态的肩膀上去拥抱GPU开发者。
这一消息随即引起讨论:CUDA兼容禁令意味着什么?是否会对国内GPU企业产生不利影响?
对此,北京GPU独角兽企业摩尔线程发声明澄清:“摩尔线程MUSA/MUSIFY不涉及英伟达EULA相关条款,开发者可放心使用。”
据Tom’s Hardware报道,兼容CUDA有两种常见做法:重新编译代码(可供相应程序的开发人员使用)、使用转译层。
其中第一种重新编译现有CUDA程序的做法是合规的。AMD和英特尔都有工具来分别将CUDA程序迁移到他们的ROCm和OpenAPI平台上。一些国内GPU企业也采用了类似的兼容思路。
EULA条款主要禁掉的是第二种,使用像ZLUDA开源库之类的转译层。外媒称这是在非英伟达硬件上运行CUDA程序的最简单方法。
此前,英特尔和AMD都支持过ZLUDA项目,但后续又都停止了。ZLUDA利用ROCm技术栈上实现CUDA应用二进制兼容,支持无需修改代码就能在AMD硬件平台上运行CUDA应用。
开发者之所以对英伟达GPU长期依赖,就是因为CUDA已经足够好用,跟英伟达GPU硬件的软硬协同也做到最好,没必要换个新平台,而且其他平台还可能存在出现潜在bug的风险。
然而,如果能实现在其他硬件上跑CUDA,虽然会有一定性能损失,但对缩小与英伟达的生态差距已经相当有利。这多少会威胁到英伟达在加速计算领域的霸主地位,英伟达对此做限制也不意外。
随着生成式AI越来越火,被视作英伟达GPU护城河的CUDA,其兼容性已成一个热门话题。
去年在纽约举行的一次活动上,英特尔CEO基辛格在对CUDA技术大加赞赏的同时,也坦言“整个行业都在积极消除CUDA的依赖”。
当时他列举了MLIR、谷歌、OpenAI等例子,暗示他们正转向“Pythonic编程层”,使AI训练更加开放。他认为“CUDA护城河又浅又小”,其主导地位不会永远持续下去,因为行业有动力为大模型训练、数据科学等带来更广泛的技术。
AMD CEO苏姿丰去年接受外媒采访时谈到“自己不相信护城河”。在她看来,过去开发者倾向于使用针对特定硬件的软件,但展望未来,每个人都在寻求构建与硬件无关的软件能力,人们希望确保能从一种基础设施迁移到另一种基础设施,因此正在构建这些更高级别的软件。
上个月,硅谷芯片架构大神Jim Keller也在社交平台上发牢骚:“CUDA是沼泽,不是护城河。”他吐槽写CUDA效率低下,Triton、Tensor RT、Neon、Mojo的存在是有合理理由的。
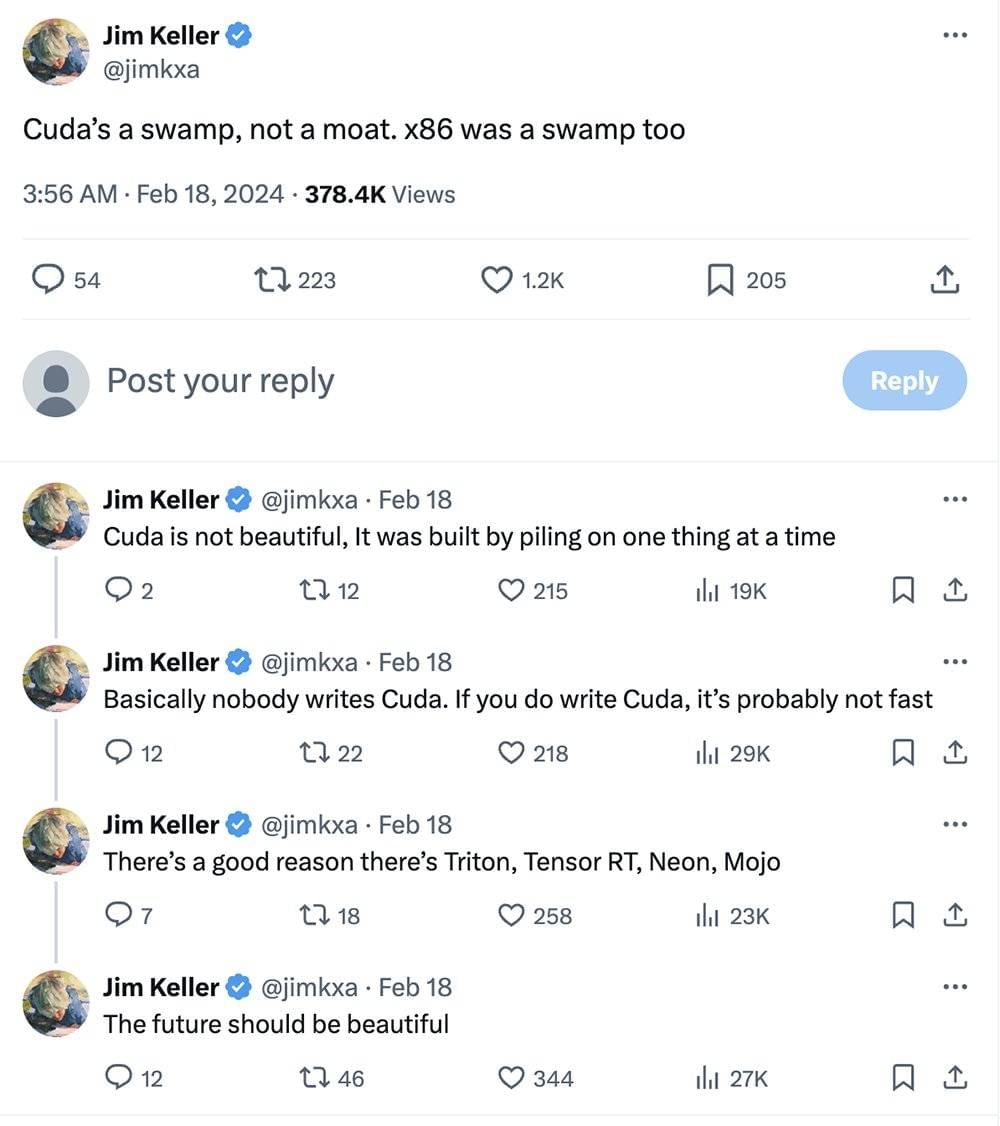
可以说,AI芯片和GPU领域苦CUDA久矣,业界对这种封闭生态已经颇有微词。兼容CUDA只是权宜之计,有长期雄心的芯片大厂或初创公司都在构建自主软件生态,并力挺更加开放的生态。
以OpenAI Triton为代表的开源编程语言,正成为对抗CUDA封闭阵营的关键力量,通过极大简化GPU加速编程过程、显著减少编译新硬件所需的工作量,减弱开发者对CUDA的依赖。
与此同时,当GPU短缺问题愈发严重,迫切需要更多计算能力的AI企业可能会越来越多考虑AMD、英特尔等竞争对手的替代品。当它们纷纷撸起袖子推出性能强大且更加经济高效的GPU产品时,英伟达的霸主地位将受到挑战。
而从商业决策的角度来看,着眼于解决复杂视觉计算问题、持续创新的英伟达,也有充分的理由来捍卫自己长期积累下来的知识产权和商业硕果,让客户与其生态系统产生更加牢固的粘性。
本文来自微信公众号:芯东西 (ID:aichip001),作者:ZeR0