
出品 | 虎嗅科技组
作者 | 杜钰君
编辑 | 王一鹏
头图 | 摄图网
碾压谷歌的Gemini Pro和阿里的Qwen-VL-Plus,与GPT-4V正面硬刚,这个有着SOTA级别性能的多模态大模型真正做到了“人无我有,人有我优”。
继2023年4月的初级版本、2023年10月的LLaVA-1.5之后,2024年1月31日,微软研究院又联合威斯康星大学麦迪逊分校和哥伦比亚大学的研究者共同发布了多模态大模型LLaVa(Large Language and Vision Assistant)的1.6版本。与GPT-4V只提供API接口的闭源经营理念不同,LLaVA1.6的代码、模型与训练数据全开源,且在标准评测数据集上跑出了较为亮眼的成绩。
一、LLaVA1.6:卷上加卷
LLaVA是一种端到端训练的大型多模态模型,又被称为“大型语言和视觉助手”。LLaVa-1.6是微软LLaVa系列的第三个迭代版本。升级后的LLaVa-1.6可谓buff叠满:SOTA级别的性能,低训练花销,多模态的内容生成能力和再一次将开源大模型卷上了新高度。
根据LLaVa-1.6官网的标准评测数据集,该模型的表现超越了Qwen-VL-Plus、CogVLM和Yi-VL等一众模型,在大部分数据集上的表现都优于Gemini Pro,在Math-Vista、MMB-ENG等部分数据集上的表现甚至胜于GPT-4V,成为了开源模型中的“性能王者“。
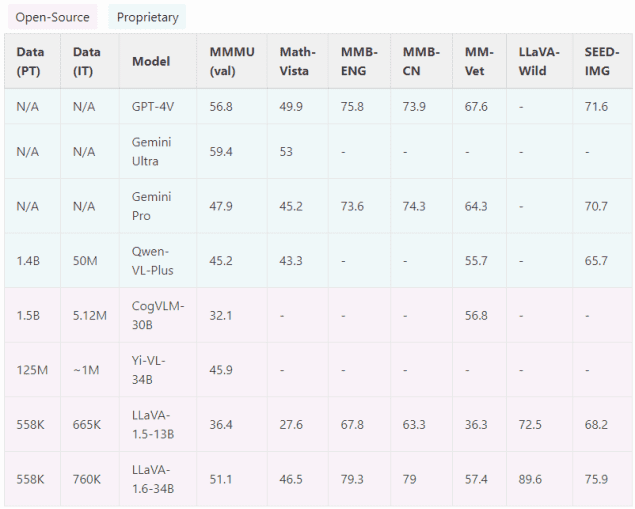
图片来源:LLaVA-1.6官网的标准评测数据
在不拘泥于单一模态的内容生成,具有Text-to-Text和Image-to-Text两种模式的同时,LLaVa-1.6的过人之处还在于更低的训练数据成本。LLaVA-1.6能用32个GPU在一天之内完成训练,仅需1.3M条训练数据,其计算和训练数据比其他模型小100到1000倍。
除了通过对话式AI生成文本外,LLaVA-1.6还可以识别图片信息并转化成文字答案。升级后的LLaVa-1.6对输入图像的分辨率提升到原来的4倍以上,使得模型能够抓住图片的更多细节。目前支持的图像分辨率有672x672、336x1344以及1344x336三种。
LLaVA模型架构基于大量的图像-文本配对的数据集,将预训练的CLIP视觉编码器与大型语言模型(Vicuna)通过映射矩阵相连接,来实现视觉和语言特征的匹配。根据该模型的研发团队成员Haotian Liu在X平台的介绍,此增强版本建立在其前身的简约设计和数据效率基础上,并通过改进视觉指令数据集和SGLang,提升了“推理、OCR等方面的性能”,意味着人类向AGI(通用人工智能)探索的道路上又迈进了一步。
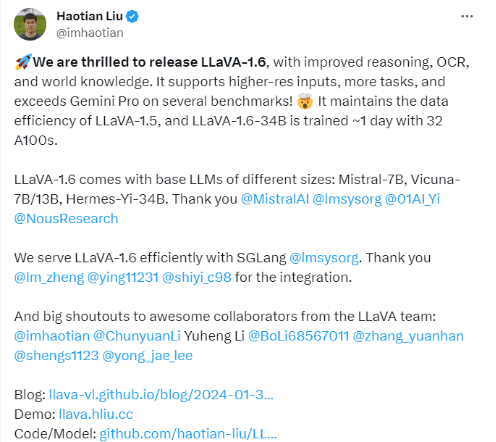
LLaVA-1.6的研发团队成员Haotian Liu在X平台发文原文
二、更适合中国人体质的GPT-4V
在奋力追平GPT-4V的同时,LLaVa-1.6也展现出强大的零样本中文能力。
LLaVa-1.6不需要额外训练便具备杰出的中文理解和运用能力,其在中文多模态场景下表现优异,使得用户不必学习复杂的“prompt”便可以轻松上手,这对于执行“免费(限制文本长度、使用次数等)+付费会员”制的文心一言们而言无疑提出了新的挑战。
笔者在对LLaVa-1.6模型的demo进行尝试时发现,LLaVa-1.6对古诗词等具有中文语言特色的文本内容理解也较为到位,且能给出中上水平的答案。因而对于有图生文或文生文需求的用户而言,LLaVa-1.6模型不失为更适合中国人体质的GPT-4V。
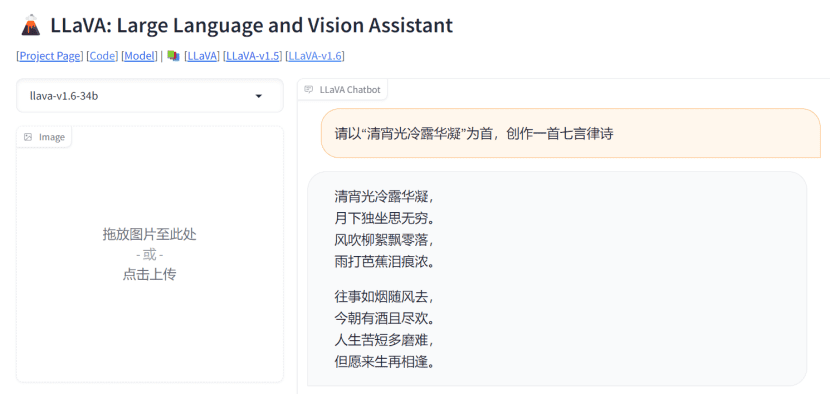
图片来源:笔者在文心一格平台的使用截图
更强的视觉对话能力使得LLaVa-1.6的智能服务可以覆盖更多元的场景、具有更强的常识和逻辑推理能力。
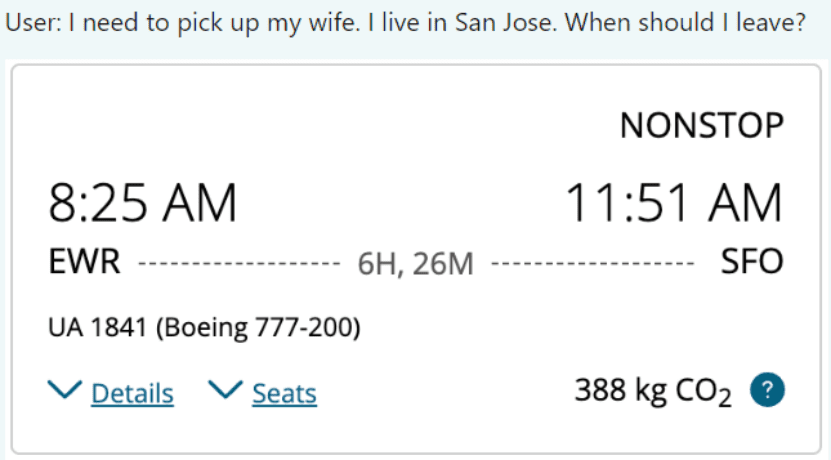
图片来源:用户在X平台对LLaVA-1.6的试用截图
在上图的应用场景中,用户发给LLaVA-1.6一张机票,询问与之相关的接机和日程安排。LLaVA-1.6不仅准确的估计了驾驶时间,还考虑到了可能堵车的情况,颇具一个“智能管家”的自我修养。
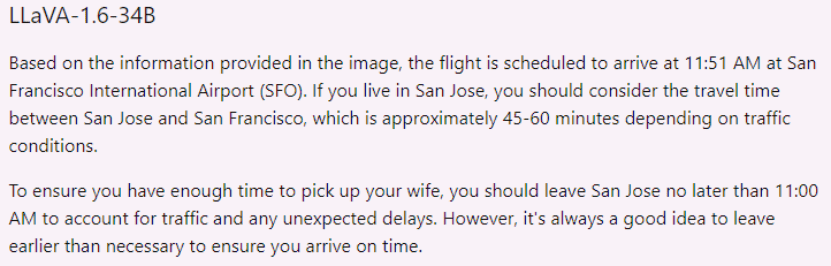
图片来源:用户在X平台对LLaVA-1.6的试用截图
为了促进多模态大模型社区的发展,开发者们开源了LLaVa-1.6的全部代码、训练数据和模型。这无疑有益于人工智能开发的透明度和协作。在较小训练样本和开源的前提下,如果可以基于本地数据训练专业模型,推动解决当前大模型基于云的产品的责任和隐私问题。
不难发现,轻量化的训练数据是LLaVa-1.6与其他多模态大模型不同的关键一点。一直以来,成本的高企便是横亘在大模型训练面前的一大难题。随着大模型赛道越来越卷,研发者们开始将关注点从性能转向成本,在关注大规模参数量的同时着力降低模型的运算和推理成本,实现模型压缩化和计算高效化。