
OpenAI新爆款Sora的热度持续发酵,在科技圈的刷屏阵仗都快赶上正月初五迎财神了。
智东西2月17日报道,这两天,OpenAI首款文生视频大模型Sora以黑马之姿占据AI领域话题中心,马斯克、杨立昆、贾扬清、Jim Fan、谢赛宁、周鸿祎、李志飞等科技人物纷纷下场评论,一些视频、影视、营销从业者也关注起这个新工具,开始担心自己的饭碗。
OpenAI CEO萨姆·阿尔特曼在社交平台X上积极与网友互动,马斯克感叹“人类愿赌服输”,360集团创始人、董事长兼CEO周鸿祎预言“AGI实现将从10年缩短到1年”。身为竞争对手的AI文生视频创企Runway联合创始人兼CEO Cristóbal Valenzuela也被惊到发表感言。
技术大牛们则开动脑力,从有限资料中抽丝剥茧,推演Sora的技术配方。Meta首席AI科学家杨立昆称,纽约大学助理教授谢赛宁作为一作的扩散Transformer论文是Sora的基础。谢赛宁也积极发长文分析Sora基于DiT架构、可能用到谷歌NaViT技术,推算Sora参数量约30亿。
一些OpenAI技术人员还在持续放出更多用Sora生成的视频作品,如海上自行车比赛、男人向巨型猫王鞠躬、鲨鱼跳出海面吓到在海滩的人……
民间高手们同样行动力惊人:有的将OpenAI展示的生成视频示例的提示词输入到Midjourney、Pika、RunwayML、Make-A-Video等其他明星模型对比效果;有的把Sora和比它早几个小时发布的谷歌最新力作Gemini 1.5 Pro玩起了联动。
Sora的爆火,再度坐实了阿尔特曼“营销大师”的称号。
一些网友怀疑阿尔特曼是专挑谷歌发Gemini 1.5的时间亮出Sora,硬生生把手握100万tokens技术突破的Gemini 1.5话题度杀到片甲不留,是一出用大型广告秀吸引更多融资的高招。
而最新被曝出的消息,似乎印证了OpenAI对新融资的迫切。据外媒报道,随着新一笔要约收购交易完成,OpenAI的估值或超过800亿美元。
阿尔特曼宏大的7万亿美元芯片筹资计划也亟待输血,毕竟最近刚给他的小目标再加1万亿美元,并收获了马斯克的评论。
这样看来,利好的还是AI infra和芯片企业。
一、大佬们怎么看Sora?
不管是震惊Sora的强大,还是吐槽其生成视频的破绽,都能收获极高的关注度。大佬们也分为几派,从不同角度对Sora进行点评。
1. 吃瓜感慨派:时间不等人,甘拜AI下风
代表之一是马斯克,在社交平台X上的各网友评论区活跃蹦跶,四处留下“人类愿赌服输(gg humans)”“人类借助AI之力将创造出卓越作品”等只言片语。

AI文生视频创企Runway联合创始人兼CEO Cristóbal Valenzuela感慨后浪拍前浪,以前需要花费一年的进展,变成了几个月就能实现,又变成了几天、几小时。
出门问问创始人李志飞在朋友圈感叹:“LLM ChatGPT是虚拟思维世界的模拟器,以LLM为基础的视频生成模型Sora是物理世界的模拟器,物理和虚拟世界都被建模和模拟了,到底什么是现实?”

2. 展望预言派:OpenAI还有武器,创企压力倍增
周鸿祎发了一条长微博和一个视频,预言Sora“可能给广告业、电影预告片、短视频行业带来巨大的颠覆,但它不一定那么快击败TikTok,更可能成为TikTok的创作工具”,认为OpenAI“手里的武器并没有全拿出来”“中国跟美国的AI差距可能还在加大”“AGI不是10年20年的问题,可能一两年很快就可以实现”。
美国旧金山早期投资人Zak Kukoff预测:一个不到5人的团队将在5年内用文生视频模型和非工会的劳动力。制作一部票房收入超过5000万美元的电影。

GitHub Copilot主创Alex Graveley则替生成式AI创企们捏了把汗:“如果OpenAI打算继续逐个行业地蚕食AI初创公司,他们应该尽快上市。构建一个只有500人受益的新经济是个糟糕的未来。”
前阿里副总裁、正在AI infra赛道创业的贾扬清,评价简单粗暴:“真的非常牛。”他认为“对标OpenAI的公司有一波被其他大厂fomo(害怕错过)收购的机会”“开源还需要一段时间才能catch up”,算法小厂“要不就算法上媲美OpenAI,要不就垂直领域深耕应用,要不就开源”,并预言“infra的需求继续会猛增”。
3. 上手体验派:比较多个视频生成模型,联动Sora和Gemini 1.5
知名连续创业者Gabor Cselle在测试关于美丽东京白雪皑皑的提示词后,得出的结论是Sora在长镜头上表现得更好。

Gabor Cselle还让谷歌Gemini 1.5 Pro观看并分析评论了OpenAI Sora制作的视频。
Sora的原提示词是:“美丽、白雪皑皑的东京市熙熙攘攘。镜头穿过熙熙攘攘的城市街道,跟随几个人享受美丽的雪天,在附近摊位上购物。绚丽的樱花花瓣随雪花在风中飞舞。”
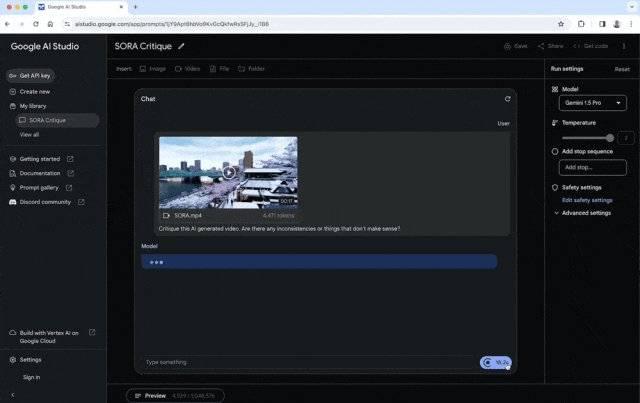
Gemini 1.5 Pro给出的评论是:“这段视频拍摄的是日本一条下雪的街道,樱花盛开。有一些不一致的地方表明视频可能是AI生成的。首先,雪下得很大,但樱花还在盛开,樱花通常开在春天,那时天气温暖,没有雪;其次,雪以一种很均匀的方式落下,这与现实生活中的雪通常不同;第三,尽管下着雪,视频中的人没有穿任何冬天的衣服。总的来说,这段视频在视觉上很吸引人,但前后矛盾之处表明这不是真实场景。”
4. 技术分析派:Sora或有30亿参数,基础论文被扒
含金量最高的当属围绕Sora核心技术的讨论。
PyTorch创始人Soumith Chintala从视频推测Sora是由游戏引擎驱动的,并为游戏引擎生成组件和参数。
英伟达高级研究科学家Jim Fan评价Sora是“视频生成的GPT-3时刻”“数据驱动的物理引擎”,认为它通过一些去噪、梯度下降去学习复杂渲染、“直觉”物理、长镜头推理和语义基础等。

多伦多大学计算机科学AI助理教授Animesh Garg夸赞OpenAI做得好,评价Sora像是“模型质量的飞跃,它不需要快速的工程来实现随时间一致的RTX渲染质量生成”。

纽约大学助理教授谢赛宁高赞Sora是“难以置信的、将重塑视频生成社区”,并发表多篇推文进行分析,推测Sora建立在扩散Transformer模型之上,整个Sora模型可能有30亿个参数。
值得一提的是,Meta首席AI科学家杨立昆转发评论称他的前同事谢赛宁和他的前伯克利学生、现任OpenAI工程师的William Peebles前年合著的扩散Transformer论文,显然是Sora的基础。

论文地址:arxiv.org/abs/2212.09748
杨立昆还特意指出,这篇论文曾因“缺乏新颖性”而被计算机视觉学术顶会之一拒收。
下一章将附上大牛们更全面的技术分析。
二、每个视频都能挑出错,Sora为什么还能这么火?
OpenAI在发布Sora的博客文章下方特意强调其展示的所有视频示例均由Sora生成。比起OpenAI的承诺,更能证明Sora清白的是这些视频中出现的各种生成式AI“灵魂错误”。
比如,随着时间推移,有的人物、动物或物品会消失、变形或者生出分身;或者出现一些违背物理常识的闹鬼画面,像穿过篮筐的篮球、悬浮移动的椅子。


这些怪诞的镜头,说明Sora虽然能力惊人,但水平还不够“封神”。这也给它的竞品和担心工作被取代的人类留下了进化的余地。
毕竟,AI视频生成已经断断续续火了一年多,而当前最晚出场的Sora,就算是错漏百出,也已经在时长、逼真度等方面甩开同行一条街。
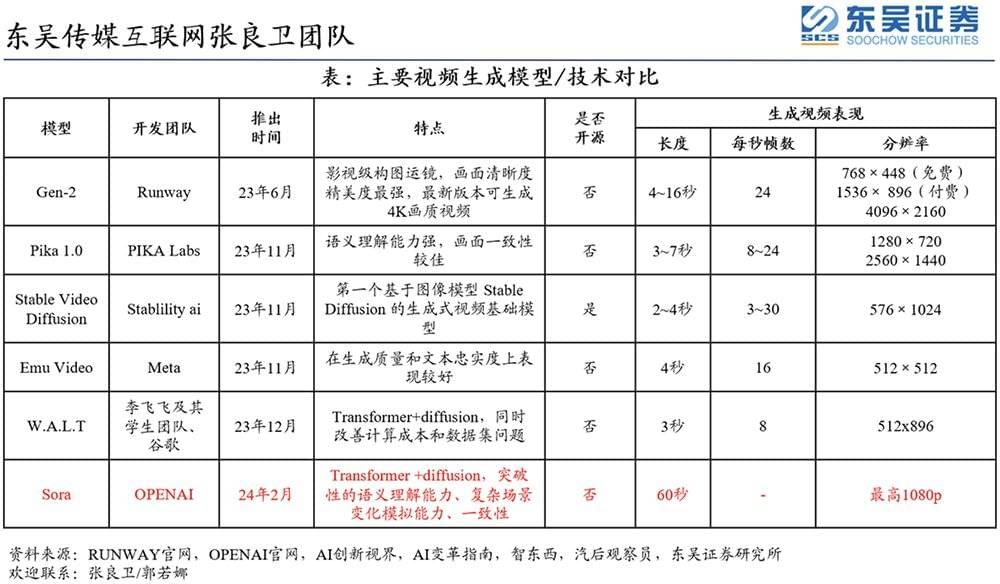
主要视频生成模型/技术对比(来源:东吴证券)
让机器生成视频,难点在于“逼真”。比如一个人在同一个视频里的长焦和短焦镜头里外观不会变化;随着镜头转动,站在山崖上的小狗应该跟山崖保持一致的移动;咬一口面包,面包就会少一块并出现牙印……这些逻辑对人来说似乎显而易见,但AI模型很难领悟到前一帧和后一帧画面之间的各种逻辑和关联。
首先要强调下生成式AI模型跟传统信息检索的区别。传统检索是按图索骥,从数据库固定位置调取信息,准确度高,但不具备举一反三的能力。而生成式AI模型不会去记住数据本身,而是从大量数据中去学习和掌握生成语言、图像或视频的某种方法,产生难以解释的“涌现”能力。
OpenAI在技术报告里总结了一些以前模型常用的视频生成和建模方法,包括循环网络、生成式对抗网络、自回归Transformer和扩散模型。它们只能生成固定尺寸、时长较短的视频。
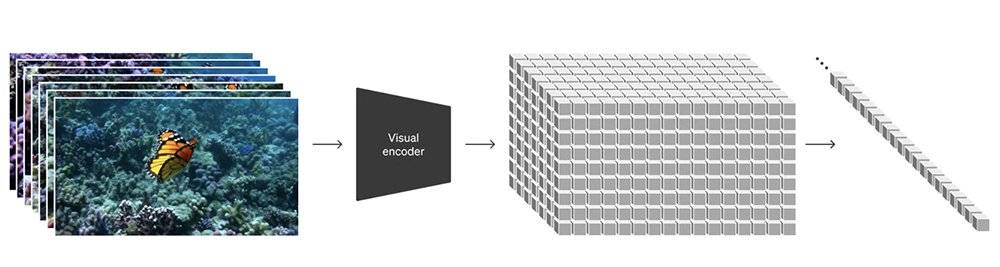
而Sora实现了将Transformer和扩散模型结合的创新,首先将不同类型的视觉数据转换成统一的视觉数据表示(视觉patch),然后将原始视频压缩到一个低维潜在空间,并将视觉表示分解成时空patch(相当于Transformer token),让Sora在这个潜在空间里进行训练并生成视频。
接着做加噪去噪,输入噪声patch后Sora通过预测原始“干净”patch来生成视频。OpenAI发现训练计算量越大,样本质量就会越高,特别是经过大规模训练后,Sora展现出模拟现实世界某些属性的“涌现”能力。
这也是为啥OpenAI把视频生成模型称作“世界模拟器”,并总结说持续扩展视频模型是一条模拟物理和数字世界的希望之路。

令技术大牛们兴奋的焦点就在这个能力上。
扩散Transformer模型论文第一作者谢赛宁发表了多篇推文,分享对Sora技术报告的看法:
先看架构,构建于扩散Transformer(DiT)模型上,DiT=[VAE编码器+ ViT + DDPM + VAE解码器]。
其次是视频压缩网络,看起来只是一个训练原始视频数据的VAE(一个ConvNet),Token化可能在获得良好的时间一致性方面发挥重要作用。

谢赛宁回顾说,在研究DiT项目时,他和Bill没有创造“新颖性”,而是优先考虑了简单和可扩展性。
简单意味着灵活。他认为人们经常忽略掉一件很酷的事,当涉及到处理输入数据时,如果让模型方式更灵活。例如在MAE中,ViT帮助我们只处理可见patches,而忽略掩码patches;类似的,Sora“可通过在适当大小的网格中安排随机初始化的patches来控制生成视频的大小”,而UNet并不直接提供这种灵活性。
他猜测Sora可能还会使用谷歌的Patch n' Pack(NaViT),使DiT适应各种分辨率/持续时间/宽高比。

论文地址:arxiv.org/abs/2212.09748
可扩展性是DiT论文的核心主题。就每Flop的时钟时间而言,优化的DiT比UNet运行得快得多。更重要的是,Sora证明了Dil扩展定律不仅适用于图像,也适用于视频——Sora复制了在DiT中观察到的视觉扩展行为。
谢赛宁推测在Sora报告中,第一个视频的质量相当糟糕,怀疑它使用的是基本模型尺寸,并做了个粗略计算:DiT XL/2是B/2模型的5倍GFLOPs,所以最终的16X计算模型可能是DiT-XL模型大小的3倍,这意味着Sora可能有大约30亿个参数——如果是真的,这不是一个不合理的模型大小。这可能表明,训练Sora模型可能不需要像人们预期的那样多的GPU——预计会有非常快的迭代。

在他看来,关键的收获来自“新兴的模拟能力”部分。在Sora之前,我们并不清楚长期的一致性能否独立出现,或者它是否需要复杂的主题驱动生成流水线,甚至是物理模拟器。OpenAl已经证明,虽然不完美,但这些行为可以通过端到端训练来实现。但还有两个要点尚未讨论:
1. 训练数据:完全没有谈论训练来源和构建,这可能只是暗示数据可能是Sora成功的最关键因素。
2. (自回归)长视频生成:Sora的一个重大突破是能够生成非常长的视频。制作2秒视频和1分钟视频的区别是巨大的。
在Sora中,这可能是通过允许自回归采样的联合帧预测来实现的,但一个主要挑战是如何解决误差积累并保持质量/一致性。一个非常长的(和双向的)条件作用环境?或者扩大规模可以简单地减轻这个问题?谢赛宁认为这些技术细节可能非常重要,希望在未来能被揭开神秘面纱。
谢赛宁还不忘给自己团队的新DiT模型SiT打个广告:具有完全相同的架构,但提供了增强的性能和更快的收敛速度。对它在视频生成上的表现也非常好奇。

Jim Fan认为,Sora是一款数据驱动的物理模拟引擎,通过一些去噪和梯度计算来学习复杂的渲染、“直觉”物理、长远规划推理和语义基础。它直接输入文本/图像并输出视频像素,通过大量视频、梯度下降,在神经参数中隐式地学习物理引擎,它不会在循环中显式调用虚拟引擎5,但虚拟引擎5生成的(文本、视频)有可能会作为合成数据添加到训练集中。

他对“Sora并不是在学习物理,它只是在操纵2D中的像素”观点持反对意见,认为这类似于说“GPT-4不学习编程,它只是采样字符串”。
“为了生成可执行的Python代码,GPT-4必须在内部学习某种形式的语法、语义和数据结构。GPT-4不显式存储Python语法树。非常类似的,Sora必须学习一些文生3D、3D转换、光线追踪渲染和物理规则的‘隐式’形式,以便尽可能准确地建模视频像素。它必须学习游戏引擎的概念以满足目标。”Jim Fan写道。
Jim Fan认为,如果不考虑交互,虚拟引擎5是一个(非常复杂的)生成视频像素的过程,Sora也是一个基于端到端Transformers的生成视频像素的过程,它们在相同的抽象层次上,不同的是虚拟引擎5是人工制作的、精确的,而Sora纯粹通过数据和“直觉”来学习。
在他看来,目前Sora对涌现物理的理解是脆弱的,远非完美,仍会产生严重、不符合常识的幻觉,还不能很好掌握物体间的相互作用。
目前Sora的训练数据源是业界普遍的关注重点,但OpenAI一如既往遵循“ClosedAI”原则,并没有透露相关信息。
三、打开视频创作便捷之门,或改变短视频市场秩序
Sora向非专业人士打开了一扇创造虚拟世界的便捷之门,尽管它还不能被立即使用,但它剧透了未来先进AI工具能带来的新用途。
FutureHouseSF联合创始人Andrew White认为,或许Sora可以模拟《我的世界》这个游戏,甚至下一代游戏机将是Sora box,游戏将以2-3段文字的形式发布。
当然,不完美的Sora在其生成的48个视频Demo中留了不少穿帮画面,如果将这些镜头放到影视剧里或者作为精心制作的长视频的素材,需要做很多修补工作。
不过对于那些原本无法估量预算的拍摄场景,或者是资源有限的独立创作者,AI工具足以帮助节约相当可观的成本。
一位专业动画师Owen Fern分享说,自己不担心Sora的原因是动画是一个迭代过程,客户会对每一帧的细节提出修改意见,比如这一帧的表情要更可爱、那一帧人物的鼻子要打高光……人类可以一点点按需修改,而AI只能全部推倒重来。
如果用AI制作视频的目的仅仅是“好玩”,那么用Sora生成一些不完美但吸睛的视频,足够在短视频平台上掀起新的流行与狂欢。
用AI制作创意视频固然无可厚非。但设想一下,当你被一些萌宠、萌娃视频可爱到,当你被独具风格的风景或室内设计惊艳到,然后得知这些其实是由AI生成的,会不会有种不舒服的感觉?
再试想,当你订阅的博主账号经常发一些漂亮或有趣的视频,而这些视频都是用AI制作的,运营这个账号的幕后公司还拥有数千个应用类似AI手段的网红账户,流水线般吸走订阅者的时间。
无论是游戏、专业视频还是短视频制作,只要放在公共平台,至少有很多专业人士能来捕捉漏洞。但这类工具的另一重风险,连OpenAI和谷歌都讳莫如深——人类想象力的黑暗面也是无限的,当进入寻常百姓家,AI工具造成的负面影响可能失控。
AI欺诈案件已经越来越频发。由于人们在日常生活中通常不会逐帧分辨视频真伪,愈发以假乱真的AI视频生成和深度伪造技术足以化为欺诈者和诋毁者手里的利刃,刺向毫无防备的人。
四、预计OpenAI会谨慎考虑Sora对外开放时间
此前OpenAI花了大约半年来测试其大语言模型GPT-4。如果测试Sora需要差不多的时长,这个强大的视频生成工具可能会在8月份开放。不过考虑到深伪技术带给美国大选的负面影响,OpenAI估计会谨慎考虑正式公开Sora的时间。
在与谷歌Gemini 1.5 Pro相继出场的舆论战中,OpenAI Sora可以说是取得了碾压式胜利。毕竟相比暴走一年多的大语言模型,还是“眼见为虚”的60秒视频生成模型更有新鲜感和冲击力。
但从实用性来看,风头更胜一筹的Sora只是展示了几十个精选作品,离落地还有相当的距离。而OpenAI的大语言模型大本营正在被对手偷塔——谷歌突破的100万tokens大招,能够给长文本问答、视频理解带来惊人的效率飞升,OpenAI必须尽快回击。
生成式AI工具已经敲响了低水平绘画、动画、影视内容创作者的丧钟。就像蒸汽机、发电机的发明会解放生产力,也会淘汰掉大量旧生产线上的工人,AI同样会顶替一些平凡的任务,淘汰掉一拨人,但最终将推动人类创新和创造力的进化。
随着各类生成式AI模型加速演进,我们看到一个完全由文本构建的整个世界,只是时间问题。
本文来自微信公众号:智东西(ID:zhidxcom),作者:程茜、ZeR0,编辑:心缘