
3D图像一直是芯片发展的推动力之一。从上世纪九十年代直到今天,以游戏、电影等为代表的高性能图像渲染应用的蓬勃发展,直接让GPU芯片成为了一个新的芯片品类。从这个角度,我们认为高性能3D图像渲染以及3D图像学的发展一直在驱动着GPU芯片品类的发展。
在3D图像学中,对于真实场景和物体的高精度建模/渲染一直是整个学界梦寐以求的目标之一。在过去几十年中,3D场景和物体建模的主流方式是基于多边形(ploygon mesh)的建模,即把一个3D建模的物体表面近似为由大量多边形组成,而多边形数量越多,则3D建模和真实物体/场景越接近。
在具体3D模型创建方面,则是由3D建模人员创建模型。在这样的情况下,多边形数量一方面限制了渲染的性能(即主流设备难以渲染多边形足以表现全部真实场景细节的模型),另一方面从建模方面,3D建模人员也难以完成含有真实物体或者场景所有细节的3D模型。因此,我们目前看到的主流3D模型都和现实的真实场景有显著区别。
最近几年,随着人工智能的发展,以辐射场为代表的新的3D图像学正在挑战多边形建模的传统3D范式,而今年下半年3D图像学界更是由于几篇重磅研究的发表,而进入了一个快速发展阶段,真实场景建模正在以前所未有的速度接近我们。
在这几个里程碑式的研究中,第一个是由法国INRIA和德国马克思普朗克研究所完成的3D Gaussian Splatting(3D GS)。3D Gaussian Splatting是辐射场建模的一种,它和传统的多边形建模的区别在于:
第一,其3D场景的建模单位不再是多边形,而是形状和颜色可变的Gaussian Splatting (GS),通过大量GS的叠加,可以高精度还原3D场景中的细节。
第二,其建模过程不再是由3D建模人员完成,而是用了人工智能的方式,具体来说建模过程是对需要具体的场景拍摄不同视角的图片,然后这些图片通过人工智能的优化方法可以完成整个场景的3D GS建模,这样就避免了建模过程对于最终场景精度的限制。最后,3D GS的渲染速度可以很快,在现有的桌面GPU上,可以实现100 fps的渲染。当然,由于目前的GPU还没有针对3D GS做优化,这个速度和效率肯定还有很大的提升空间,但是这样的渲染速度和精度已经足以让3D GS进入实用。

使用3D GS实现的超高精度3D场景建模和渲染
第二个重要研究是由Nvidia发表的Adaptive Shells for Efficient Neural Radiance Field Rendering。
神经辐射场(Neural Radiance Field,NeRF)和3D GS类似,都是可以通过场景的多角度图片来完成场景的超高精度建模,并且其建模方式也是通过人工智能模型训练的方法来完成。NeRF和3D GS的主要不同在于,其建模方法是通过神经网络来完成,因此其渲染过程就是等价于神经网络的推理过程。NeRF出现已经有了数年,但是直到今年Nvidia的研究发表,才真正实现了GPU上高帧率(100-200fps)的高质量NeRF渲染,因此今年可望是NeRF渲染真正进入实用的开始。
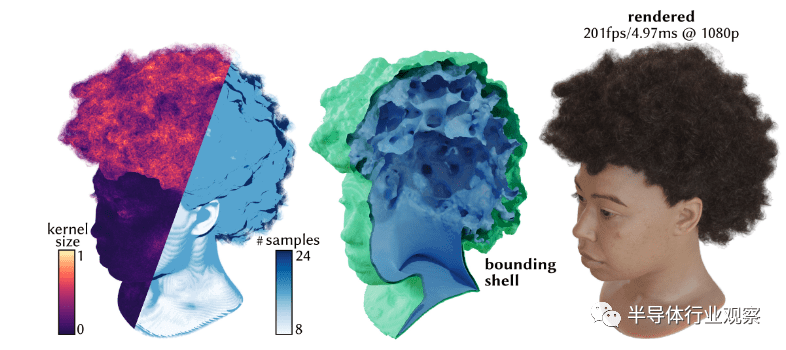
人工智能图像学对于GPU的需求
我们认为,人工智能图像学对于GPU提出了新的需求。
首先,在基本的NeRF或者3D GS的渲染中,传统的GPU中的多边形渲染流水线已经无法高效支持,因为NeRF和3D GS的渲染需要一些重要的新计算。对于NeRF来说,其场景建模信息都包含在训练过的神经网络中,神经网络的输入就是用户当前的视角,输出则是场景在视角下的2D图像。
因此,其渲染过程其实就是根据用户的视角来完成神经网络的推理计算。而在3D GS中,具体的渲染过程则是把整个场景分成多个块(tile),每个块中根据当前视角首先排序选出对于视觉影响最大的N个GS,之后再仅仅针对这些GS做渲染,从而可以实现高效率。我们可以看到这些都和当前的多边形渲染流水线有较大不同,为了能高效支持这些3D图像学的新范式,GPU需要能高效支持这些新计算。
另外,在新的3D图像学是由人工智能驱动的这一潮流下,我们势必会看到3D图像渲染和人工智能的进一步结合,例如在NeRF和3D GS的场景建模中加入基于神经网络计算的动画或者编辑(光影变化等),这些又进一步说明目前的GPU上的多边形渲染流水线对着这类新图像渲染范式已经无法高效支持。
GPU新架构呼之欲出
我们认为,这些新的超高精度3D图像学会推动新的GPU架构发展。
从桌面和服务器GPU芯片角度,我们认为GPGPU架构会得到进一步的推广。Nvidia主导的GPGPU在人工智能浪潮的前几年(2012-2017)是Nvidia能够占据人工智能霸主地位的核心,因为GPGPU的开放接口可以让GPU去做人工智能计算。在这之后,随着人工智能应用进入主流地位,Nvidia开始给人工智能做专用优化,引入了包括Tensor Core等重要新架构,换句话说人工智能在GPU上已经不再主要依赖其GPGPU思路,而是更多依赖其人工智能架构设计。然而,随着新的3D图形学的发展,GPGPU又会重新进入聚光灯下。
从芯片架构角度来说,从宏观上这意味着GPGPU的进一步进化以及和人工智能的融合。之前,GPGPU允许用户去调用3D图形计算的单元去做其他非图形的计算;而随着新的3D图形学的发展,需要GPGPU能进一步开放图形渲染单元,让图形渲染单元更加灵活,从而能支持新的3D建模范式的高效渲染。我们认为,芯片架构层面,对于这样新3D图形学范式的支持,有三方面的需求。
第一个方面是打通渲染流水线和人工智能引擎。
由于神经网络的计算在新的3D图形学中起了极其重要的角色,如何把图形渲染单元和GPU中的人工智能引擎打通,将是支持这类新3D图形学渲染的核心需求。例如,在芯片架构设计中,需要能够让图形渲染单元和人工智能引擎之间实现有效通信以及互相高效调用,从而能充分支持这样的渲染需求——像NeRF这样的建模方法中,每一帧计算都需要去运行一次神经网络推理,在高分辨率的时候神经网络会非常复杂,而高帧率则需要神经网络延迟有很高的需求,在这种情况下需要图像渲染和人工智能引擎充分打通。
第二个方面是对于这些新的范式,如何实现硬件优化。
对于基于多边形传统3D图形学的渲染加速,GPU已经有了数十年的积累,因此从硬件上几乎已经把优化做到了极致,然而对于NeRF或者3D GS这样的新范式,硬件优化目前仍然不存在。第一步,我们可以把目前已有的针对多边形渲染的优化应用到这类新3D图形范式上,例如分块(tile)渲染以实现并行处理,以及流水线计算以降低延迟,等等。更进一步,未来会出现针对这些新3D图形学范式的专门优化,从而可以将渲染效率进一步提高。
第三个方面是如何提供灵活的用户接口。
3D新图形学方兴未艾,在可预计的未来仍然会高速发展,因此如何能给用户提供接口,从而可以让用户灵活利用和配置GPU上的计算单元,从而用户可以根据自己独特的设计来配置GPU上的渲染流水线以实现高效率。这样的可配置性对于培养新3D图形学的生态将会是至关重要,如果想要重复Nvidia在人工智能浪潮中的成功,那么就需要在新3D图形学算法尚未最终尘埃落定的时候,提供足够支持以培养用户生态;如果想要等到算法技术已经足够成熟后再开始提供支持,就会站在非常不利的位置。
比较桌面和服务器GPU的两大巨头Nvidia和AMD在这方面的状态,我们认为Nvidia由于其在人工智能和GPGPU领域的前期投入,目前毫无疑问站在非常领先的位置——例如,NeRF和3D GS绝大多数的渲染代码和benchmark都是跑在Nvidia的GPU上,这也是其生态强大的一个例子。
当然,也并不是说目前Nvidia都已经把一切做到尽善尽美;3D GS中,研究人员就提到了CUDA的GPGPU计算库虽然能实现高效计算,但是在做渲染的时候存在一定的兼容性问题。这也对应于我们上面提到的GPGPU需要更进一步,能和人工智能引擎打通并且提供灵活的用户接口。
对于AMD来说,在过去一直处于追赶者的地位,目前来说,由于其软件生态的相对不完整,预计在新3D图形学逐渐变成主流的前几年,AMD仍然将处于追赶者的地位。但是,如果AMD不想错过这一波新的3D图形学的机会的话,一方面需要在软件生态上更快速地追赶,另一方面则需要在硬件架构上做相比于Nvidia更加果断的优化来支持这类新的3D图形学。
除了桌面/服务器GPU之外,事实上移动端GPU对于这类新3D图形学也很重要,因为未来ARVR这类使用移动GPU的应用也预计是这样的新3D图形学的最关键场景。从移动端GPU来说,最关键是如何实现高效率支持,确保在电池和散热允许的情况下实现最佳质量和帧率。
从芯片架构角度,一方面,我们预计也会看到GPU和人工智能引擎在移动SoC上的更高效通信以满足图形学上的需求——这将是一个很有趣的架构设计,因为在不少SoC中GPU和人工智能引擎都是完全分离的IP,有些SoC上的GPU和人工智能引擎甚至可能会由不同的公司设计,因此如何确保两者之间能互相通信将是重要的课题,甚至可能会有专用的通用接口协议出现。
另一方面,移动GPU上对于效率和灵活度的取舍,一般都会更偏向于效率,因此如何在算法上提供高效支持,将会是移动GPU优化的重点。
本文来自微信公众号:半导体行业观察 (ID:icbank),作者:李飞